数据库
概念性内容
使用文件系统存储数据的缺点
- 数据以多种不同文件格式重复存储
- 数据访问困难
- 数据分散于多个文件或不同文件格式中
- 难以对数据取值范围设定限制,且修改限制不便
- 数据修改操作可能因异常而中途停止
- 多用户并发操作可能导致意外结果
数据库管理系统 (DBMS) 的优缺点
优点
- 安全:未认证用户无法访问系统
- 完整性:确保数据之间无矛盾冲突
- 并发性:支持多用户共享数据库
- 可恢复:能够回滚到之前的版本
缺点
- 占用空间较大
- 需要额外硬件资源
- 数据可能需要转换
数据定义语言 (DDL)
- 用于指定数据库中的数据类型、结构和约束
数据操纵语言 (DML)
- 包括对数据库的插入、更新、删除和查询操作
ER 图
ER 图是设计数据库的关键
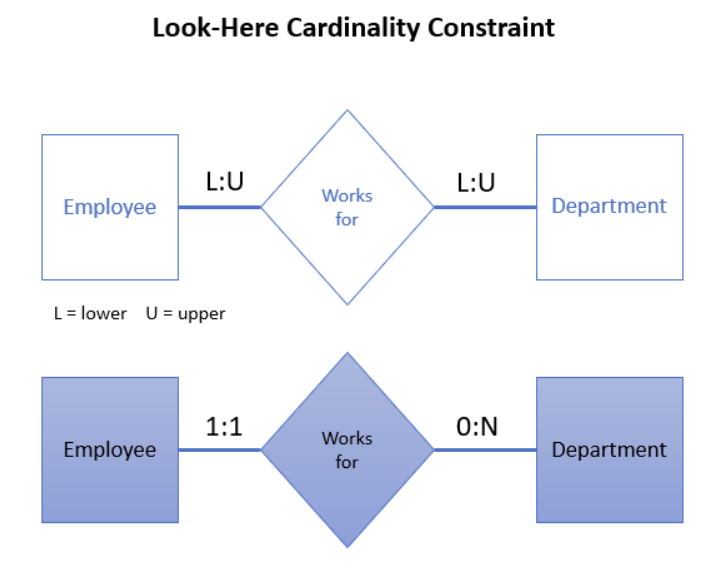
基数比
基数,意思就是这一列的所有值,如果扔到一个集合里面去,集合大小是多少。
对于二元关系,基数比可以是:
- 一对一(1:1):每当一个实体出现时,另一个实体就会恰好出现一次。
- 一对多(1:m):每当一个实体出现时,另一个实体就会出现多次。
- 多对多(m:m):对于一个实体的每次出现,另一个实体可能会出现一次或多次,反之亦然。
SQL 注入攻击
比如,在一个 web 页面当中,用户搜索一个产品名字,然后 Perl 查询 SQL 返回对应信息。假如 Python 代码是这样写的:
user_input = input("请输入产品名称: ")
query = f"SELECT * FROM products WHERE name = '{user_input}'"
print("生成的SQL查询:", query)现在,如果用户输入的是正常的产品名称,比如product1,那么生成的SQL查询将是正常的:
SELECT * FROM products WHERE name = 'product1'但是,如果用户输入恶意代码,例如' OR '1'='1,则生成的SQL查询变为:
SELECT * FROM products WHERE name = '' OR '1'='1'这将导致查询返回表中所有的记录,因为 '1'='1' 总是为真。
防御方法:
- 使用
prepared queries - 检查用户输入内容是否合法,例如让用户只能输入字母和数字
- 检查输入内容是否包含 SQL 关键字
JOIN 类型
INNER JOIN: 只返回两个表中满足连接条件的匹配行LEFT JOIN: 返回左表中的所有记录,对于右表中没有匹配的记录,结果集中会包含 NULL 值RIGHT JOIN: 同上FULL JOIN: 返回两个表中的所有记录,对于没有匹配的记录,结果集中会包含 NULL 值CARTESIAN JOIN: 返回两个表的笛卡尔积,即第一个表的每一行与第二个表的每一行组合,也就是全组合
数据库标准化
标准化数据表,有以下功效:
- 减少重复数据 (save typing repetitive data)
- 增加询问、排序等操作的灵活性 (increase flexibility)
- 避免频繁的表重构 (avoid frequent restructuring)
- 减少硬盘空间占用 (less disk consuming)
例子:
比如这个表,有一大堆的重复数据
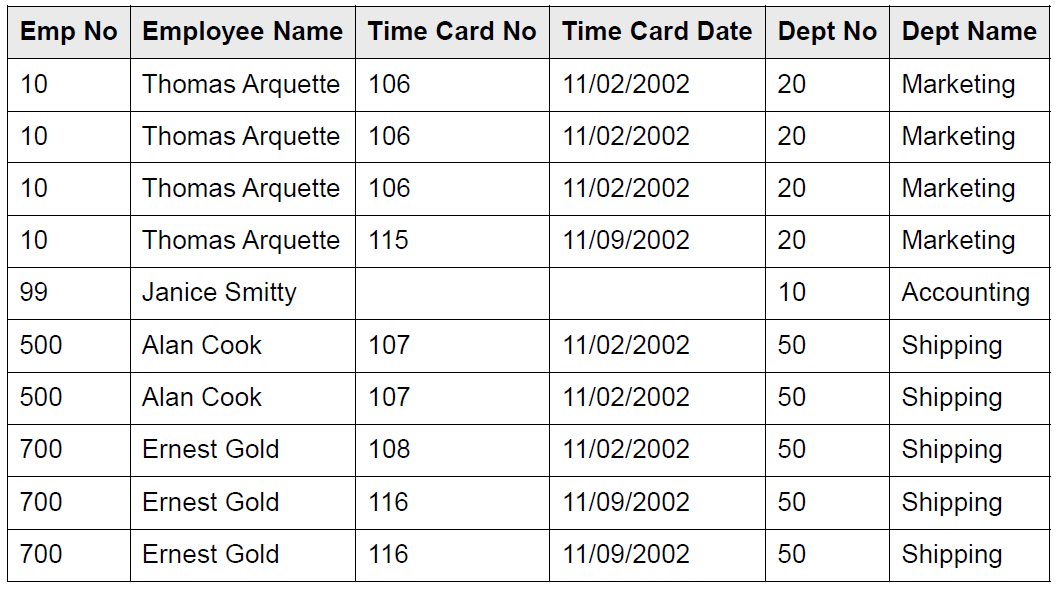
为了避免重复,可以考虑把这个大的表,拆分成三个小的表,然后这三个表通过主键(外键)联系起来

First normal form(一阶范式)
- 每个 field 只包含最小单位的有意义的值。比如,姓名拆成姓和名。
- 表不包含重复的 groups of fields,同一个 field 不包含重复的数据
对于第一个条件(每个列不能包含多个值),可以这样修改(上表不满足条件,下表满足)

但是虽然下面那张表满足了第一个条件,仍然不满足第二个条件。比如如果新增了一个 WH E,所有的行都要发生改动。相当于,repeating fields. 所以应该进一步改成这样:

但是主键也要修改。之前的主键是 PART 一个属性,现在的主键是 (Part, WH) 二元组。
Second normal form(二阶范式)
二阶范式,是一阶的加强版。
- usually used in tables with a multiple-fieled primary key(composite key)
- 每一个 non-key field 都跟整个主键有关系
- 每一个与主键无关的东西,都放在别的表里面
主要就是,用多个表,消除表当中的冗余数据(redundant data)
像这个表,不满足二阶范式。
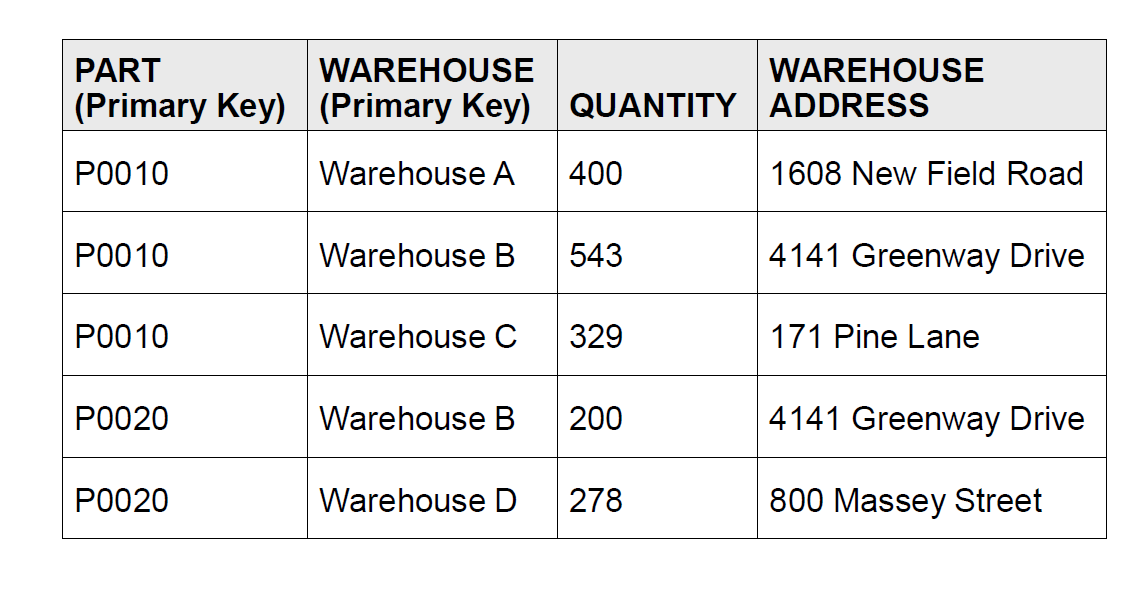
发现 WH B 出现了两次,且对应的地址(address)相等。这就意味着表格出现了冗余数据,要拆表。所有的 WH 只要编号相同,地址应当也是相同的。所以可以把地址拆出去,用 WH 作为主键连接:
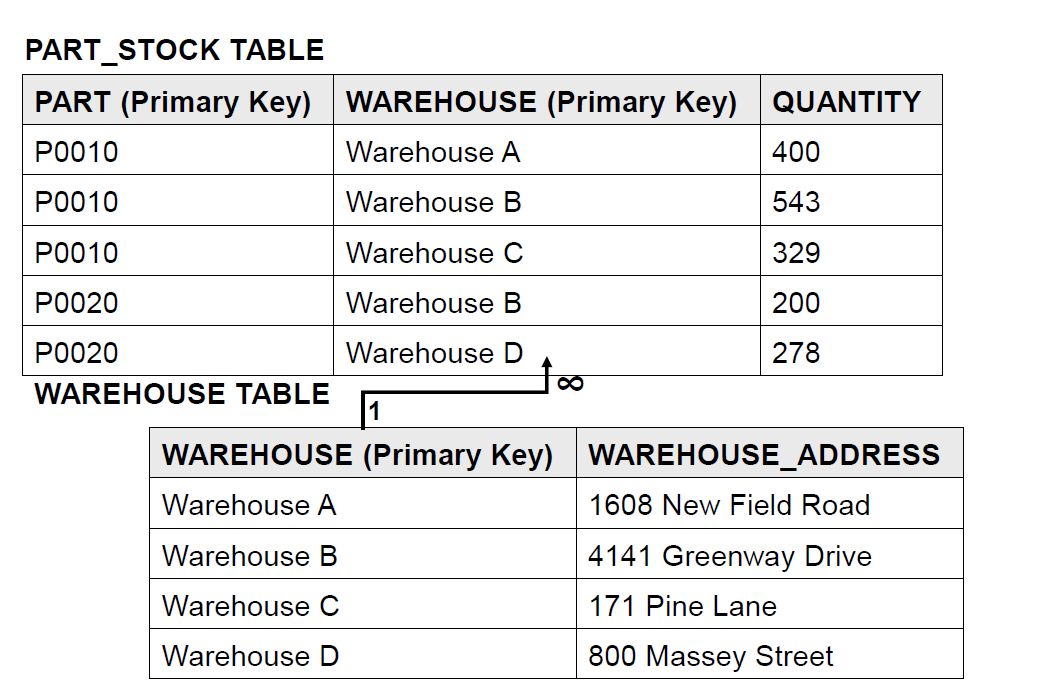
这样,就满足二阶范式了。
Third normal form(三阶范式)
三阶范式,仅考虑主键只有一列的表。
- 表当中,通常使用 single-field primary key
- 记录 do not depend on anything other than 主键
- 每一个 non-key field is a fact about the key
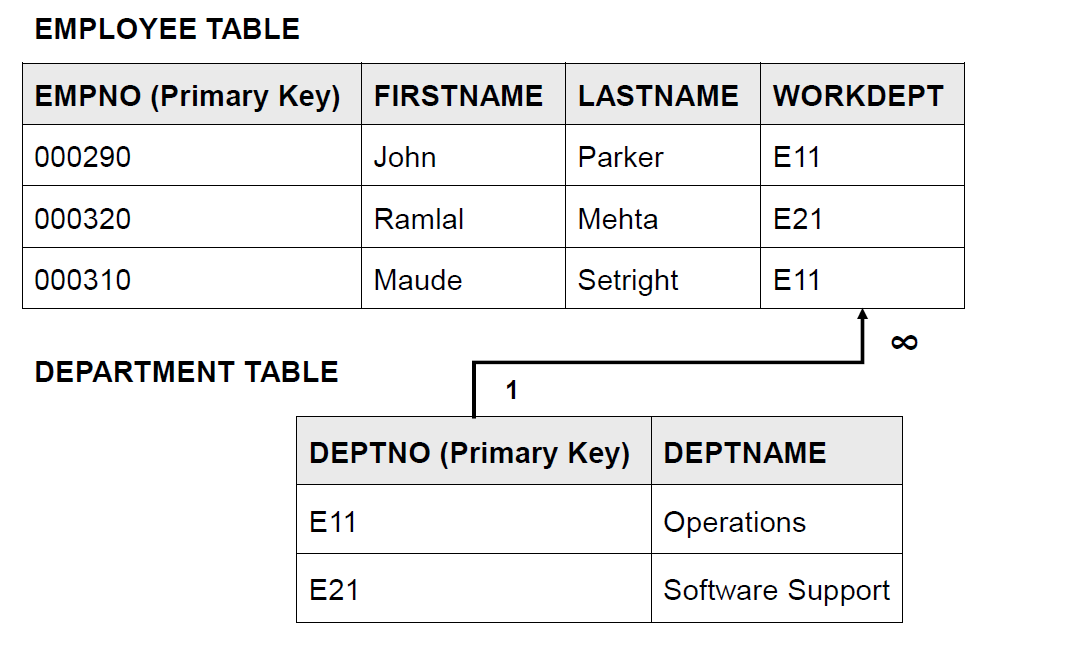
来看一个不满足三阶范式的例子

在这个表当中,DeptName 跟主键 EmpNo 好像没啥关系,只跟 WorkDept 有关。所以 DeptName 应该拆到别的表当中去。
语法部分
CREATE 语句
CREATE TABLE <table name> (
<column name> <data type> [(<size>)] <column constraint>,
...
<keys>
);数据类型 (<data type>)
INTEGER: 存储整数值DATE: 存储日期(年-月-日)TIME: 存储时间(时:分:秒)TIMESTAMP: 存储日期和时间(年-月-日 时:分:秒)VARCHAR(N): 存储可变长度字符串,N为最大长度
列约束 (<column constraint>)
UNIQUE: 确保列值唯一,不允许重复NOT NULL: 列不允许NULL值PRIMARY KEY: 唯一标识表中每一行记录,结合了UNIQUE和NOT NULLREFERENCES <table name>(<column name>) [ON DELETE CASCADE ON UPDATE CASCADE]: 定义外键约束,维护参照完整性, 考虑级联删除、级联更新DEFAULT <data value>: 指定默认值CHECK <condition>: 确保列值满足特定条件
键定义 (<keys>)
CONSTRAINT table_name_pkey PRIMARY KEY (id): 主键约束,确保唯一性和非空性CONSTRAINT table_name_fkey FOREIGN KEY (column_name) REFERENCES other_table(other_column): 外键约束,建立表间引用关系CONSTRAINT unique_constraint UNIQUE (column1, column2, ...): 确保列组合值唯一CONSTRAINT check_constraint CHECK (condition): 确保值满足特定条件
SELECT 语句
SELECT <column name1>, [<column name2>, ...]
FROM <table name>
[WHERE <expr>];
[count()] -- 返回行数
[ORDER BY <column name> <method>(asc, desc)] -- 排序方式实用函数
-
char_length(colName):计算字符串长度 -
power(a, b):计算 $a^b$ -
log(x):计算 $\log_{10}x$ -
BETWEEN ... AND ...:表示一个区间,如a between x and y意味着 $x≤a≤y$ -
... IN (...):表示在一个集合中,例如col in (4,5,6)等价于(col = 4) or (col = 5) or (col = 6)
时间和日期处理
now():返回当前带时区的时间戳date_part(text, timestamp):从时间戳提取特定信息extract(field from timestamp):从时间戳中提取特定信息
field可以是century, day, decade, dow(星期天是第0天), doy(一年的第几天) ···
匹配语法
-
LIKE: 使用通配符进行模式匹配,如where <col name> LIKE 'A%' -
SIMILAR TO: 支持更复杂的模式匹配,包括字符类 -
~/~*: POSIX正则表达式匹配,*表示不区分大小写
Note
正则表达式要记得使用^来表示开始和使用$来表示结尾
可参考 [官方文档](https://www.postgresql.org/docs/current/functions-matching.htm)
GROUP BY 和 ORDER BY 关键字
把所有属性值相同的行放在一起,再按照这个值排序,统计每个属性有多少行
SELECT <colName1>, <colName2>, COUNT(*)
FROM <tableName>
[WHERE <condition>]
GROUP BY <colName1>, <colName2>
HAVING <aggFunc()> <condition> -- HAVING 语法, 用aggregate函数
ORDER BY <colName1>, <colName2>;列别名和表别名
SELECT Guest.dob AS "date of brith"
FROM <tableName> AS "Guest";
ORDER BY Guest.dob DESC;Note
这里需要双引号,字符串,时间戳等都是单引号
aggregate 函数
SELECT Region as RegionName, SUM(Pop2015) as TotalPopulation2015
FROM PopulationEU
GROUP BY Region
ORDER BY TotalPopulation2015 desc;例子:
MIN()MAX()AVG()SUM()STDDEV()
INSERT 语句
INSERT INTO <tableName> (<column list>) VALUES (<value list>);DROP TABLE 删除表
DROP TABLE IF EXISTS <tableName>;DELETE 语句
DELETE FROM <tableName> WHERE <conditions>; # 删满足条件的
DELETE FROM <tableName>; # 全部删除ALTER TABLE修改表
ALTER TABLE <tableName> RENAME TO <newName>; -- 改表名
ALTER TABLE <tableName> RENAME COLUMN <oldColName> TO <newColName>; -- 改列名
ALTER TABLE <tableName> DROP COLUMN <colName>; -- 删除列
ALTER TABLE <tableName> ADD COLUMN <colName> <colType>; -- 新增列
ALTER TABLE <tableName> ALTER COLUMN <colName> TYPE <newColType>; -- 修改列的类型
ALTER TABLE <tableName> ADD PRIMARY KEY <colName>; -- 增加主键UPDATE 命令
UPDATE <tableName>
SET
<colName1> = {<expr1>},
<colName2> = {<expr2>},
<colName3> = {<expr3>},
...
[WHERE <coldition>];事务控制
BEGIN TRANSACTION;
-- blabla
COMMIT;
END TRANSACTION;
-- 正常执行
BEGIN;
-- blabla
ROLLBACK;
-- 回滚JOIN 语句
SELECT table1.<colName>, table1.<colName>, ···
FROM <tableName1> AS table1
JOIN <tableName2> AS table2 ON table2.<colName> = table1.<colName>
JOIN <tableName3> AS table3 ON table3.<colName> = table1.<colName>;视图创建
CREATE VIEW viewname AS
SELECT field1, field2, field3, ..., FROM table1, table2
WHERE ;SQL 表集合
SELECT DISTINCT salary FROM tableName; -- 去除重复
(SELECT DISTINCT Pnumber
FROM PROJECT, DEPARTMENT, EMPLOYEE
WHERE Dnum = Dnumber AND Mgr_ssn = Ssn
AND Lname = 'Smith')
UNION
(SELECT DISTINCT Pnumber
FROM PROJECT, WORKS_ON, EMPLOYEE
WHERE Pnumber = Pno AND Essn = Ssn
AND Lname = 'Smith'); -- 并集
SELECT emp_name, salary
FROM employees e1
WHERE salary > ALL (
SELECT AVG(salary)
FROM employees e2
WHERE e2.department = e1.department
GROUP BY department
); -- 比较运算符