Lecture 1: 操作系统概述
操作系统
操作系统 (Operating System) 是一个大型且复杂的软件系统,用于管理计算机的所有硬件资源,并使其易于使用。
功能:
- 引导系统: 启动机器至可用状态。
- API与系统调用: 应用通过API和系统调用与OS交互。
- 并发环境: 处理并发任务,优化资源利用。
- 用户交互: 通过GUI或CLI与用户交互。
操作系统主要任务:
- 资源管理和优化: 在进程间分配和管理资源,最大化资源利用率,提高系统吞吐量。
- 提供接口: 提供用户和应用程序接口。
- 并发协调: 协调并发活动和设备,处理I/O,保证同步和通信。
- 安全保护: 保护系统资源免受恶意或意外滥用。
内核 (Kernel)
内核是操作系统的核心,负责管理 CPU、内存、进程间通信和底层硬件等关键资源和服务,运行在特权模式下,是不同操作系统发行版的基础。
- 核心服务: 管理CPU、内存、进程间通信、底层硬件。
- 发行版组件: 包括文件系统、数据库、网络、GUI等。
云操作系统
云操作系统是指将数据和应用程序远程托管在第三方数据中心,通过租用资源并使用Web界面或API进行访问,比如Office 365。
Lecture 2: 进程管理
教授: 现在我们开始讲操作系统的第一部分——虚拟化。
学生: 尊敬的教授,什么是虚拟化?
教授: 想象我们有一个桃子。
学生: 桃子? (不可思议)
教授: 是的,一个桃子,我们称之为物理 (physical) 桃子。但有很多想吃这个桃子的人,我们希望向每个想吃的人提供一个属于他的桃子,这样才能皆大欢喜。我们把给每个人的桃子称为虚拟 (virtual) 桃子。我们通过某种方式,从这个物理桃子创造出许多虚拟核子。重要的是,在这种假象中,每个人看起来都有一个物理桃子,但实际上不是。
学生: 所以每个人都不知道他在和别人一起分享一个桃子吗?
教授: 是的。
学生: 但不管怎么样,实际情况就是只有一个桃子啊。
教授: 是的,所以呢?
学生: 所以,如果我和别人分享同一个桃子,我一定会发现这个问题。
教授: 是的!你说得没错。但吃的人多才有这样的问题。多数时间他们都在打盹或者做其他事情,所以,你可以在他们打盹的时候把他手中的桃子拿过来分给其他人,这样我们就创造了有许多虚拟桃子的假象,每人一个桃子!
学生: 这听起来就像糟糕的竞选口号。教授,您是在跟我讲计算机知识吗?
教授: 年轻人,看来需要给你一个更具体的例子。以最基本的计算机资源CPU 为例,假设一个计算机只有一个CPU (尽管现代计算机一般拥有2个、4个或者更多CPU) ,虚化要做的就是将这个CPU 虚拟成多个虚拟 CPU并分给每一个进程使用,因此,每个应用都以为自己在独占 CPU,但实际上只有一个CPU。这样操作系统就创造了美丽的假象——它虚拟化了CPU。
学生;听起来好神奇,能再多讲一些吗?它是如何工作的?
教授: 问得很及时,听上去你已经做好开始学习的准备了。
学生;是的,不过我还真有点担心您又要讲桃子的事情了。
教授;不用担心,毕竟我也不喜欢吃桃子。那我们开始学习吧……
进程、程序和处理器
进程 (Processes)
人们都常常希望同时运行多个程序。比如: 在使用电脑的时候,我们会同时运行浏览器、邮件、游戏、音乐播放器,等等。但是我们的电脑一般只有一个 CPU ,我们需要制造出一个几乎能提供无数 CPU 的假象。进程是一个程序的实例 (instance),是操作系统的一个抽象概念。其包含了一个执行上下文,包含了内核管理的、进程运行时所需的信息集合。
程序 (Program)
程序是一系列指令的集合,是将算法翻译成编程语言的结果,描述了明确的执行顺序。编译器将程序代码映射为特定处理器的机器指令,并存储在目标文件中,然后使用链接器链接上库文件就变成了可执行文件 (程序)。
处理器 (Processor)
处理器是执行进程的代理 (agent),通过执行存储在内存映像中的指令来运行进程。
时分共享
时分共享 (time sharing) 是操作系统共享资源所使用的最基本的技术之一。通过允许责源由一个实体使用一小段时间,然后由另一个实体使用一小段时间,如此下去,所谓的资源 (例如,CPU或网络链接) 可以被许多人共享。
时分共享的自然对应技术是空分共享,资源在空间上被划分给希望使用它的人。 例如,磁盘空间自然是一个空分共享资源,因为一旦将块分配给文件,在用户删除文件之前,不可能将它分配给其他文件。
进程抽象表示
进程状态
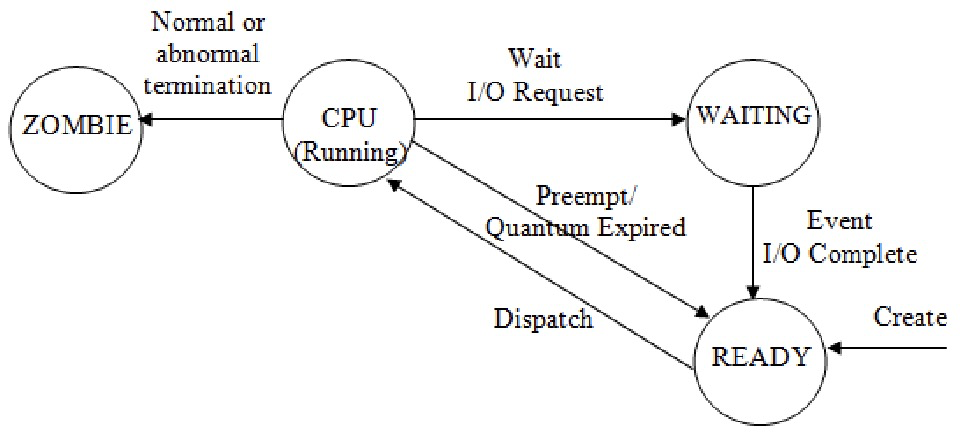
进程在运行过程中会处于不同的状态。以下是三种基本状态:
- 运行 (Running): 进程正在处理器上执行指令。
- 就绪 (Ready): 进程已准备好运行,但操作系统尚未选择它运行。
- 阻塞 (Blocked): 进程因为等待某个事件发生 (例如,I/O完成) 而暂停运行。 进程发起I/O请求时通常会进入阻塞状态。
- 僵尸 (Zombie): 进程处于已经退出但是尚未清理的状态,这种状态非常有用,因为它能允许其他进程 (通常是创建进程的父进程) 检查进程的返回代码,并且查看刚刚完成的进程是否正确运行。
进程控制块 (PCB)
操作系统是一个程序,和其他程序一样,它有一些关键的数据结构来跟踪各种相关的信息。它的最基础的任务就是进程管理,包含创建、控制、终止、管理执行环境等方面。操作系统还必须以某种方式跟踪被阻塞的进程。当 I/O 事件完成时,操作系统应确保唤醒正确的进程,让它准备好再次运行。因此我们需要一个数据结构 (PCB) 来维护这些数据。当一个进程停止时,它的寄存器将被保存到通过恢复这些寄存器,它被称为上下文切换 (context switch)。
例如 XV6 的proc结构如下:
// the registers xv6 will save and restore
// to stop and subsequently restart a process
struct context {
int eip;
int esp;
int ebx;
int ecx;
int edx;
int esi;
int edi;
int ebp;
};
// the different states a process can be in
enum proc_state { UNUSED, EMBRYO, SLEEPING, RUNNABLE, RUNNING, ZOMBIE };
// the information xv6 tracks about each process
// including its register context and state
struct proc {
char *mem; // Start of process memory
uint sz; // Size of process memory
char *kstack; // Bottom of kernel stack for this process
enum proc_state state; // Process state
int pid; // Process ID
struct proc *parent; // Parent process
void *chan; // If non-zero, sleeping on chan
int killed; // If non-zero, have been killed
struct file *ofile[NOFILE]; // Open files
struct inode *cwd; // Current directory
struct context context; // Switch here to run process
struct trapframe *tf; // Trap frame for the current interrupt
};生命周期
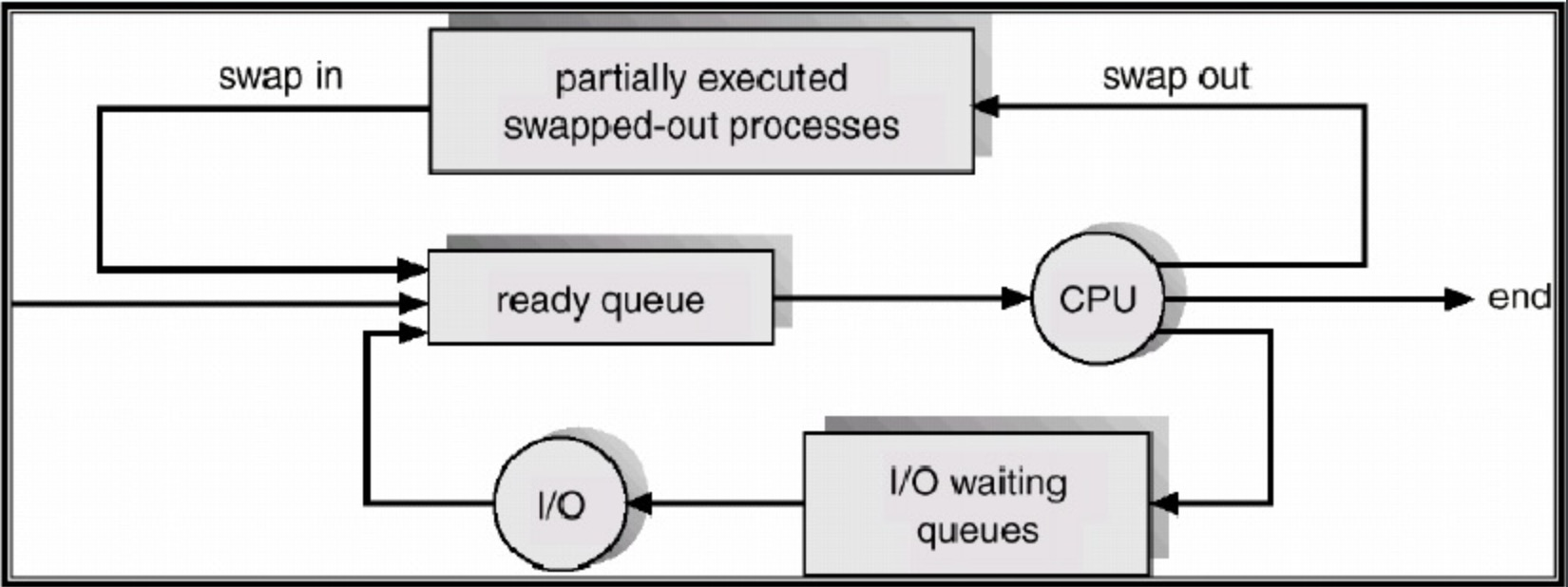
PCB可以在过程寿命中在不同队列之间移动,具体取决于其执行的优先级或状态。
通信
出于安全性和可靠性原因,与OS进行通信,无关过程之间的直接通信只能通过使用特定机制来实现。
-
进程间通信: 操作系统提供了进程间通信的函数,这些函数可以将消息 (message) 从一个进程映射到另一个进程。
-
与操作系统通信: 是通过系统调用 (system call) 机制完成的,对于程序来说,操作系统就是上帝,没有操作系统,程序连杀死自己都做不到!
处理器执行模式
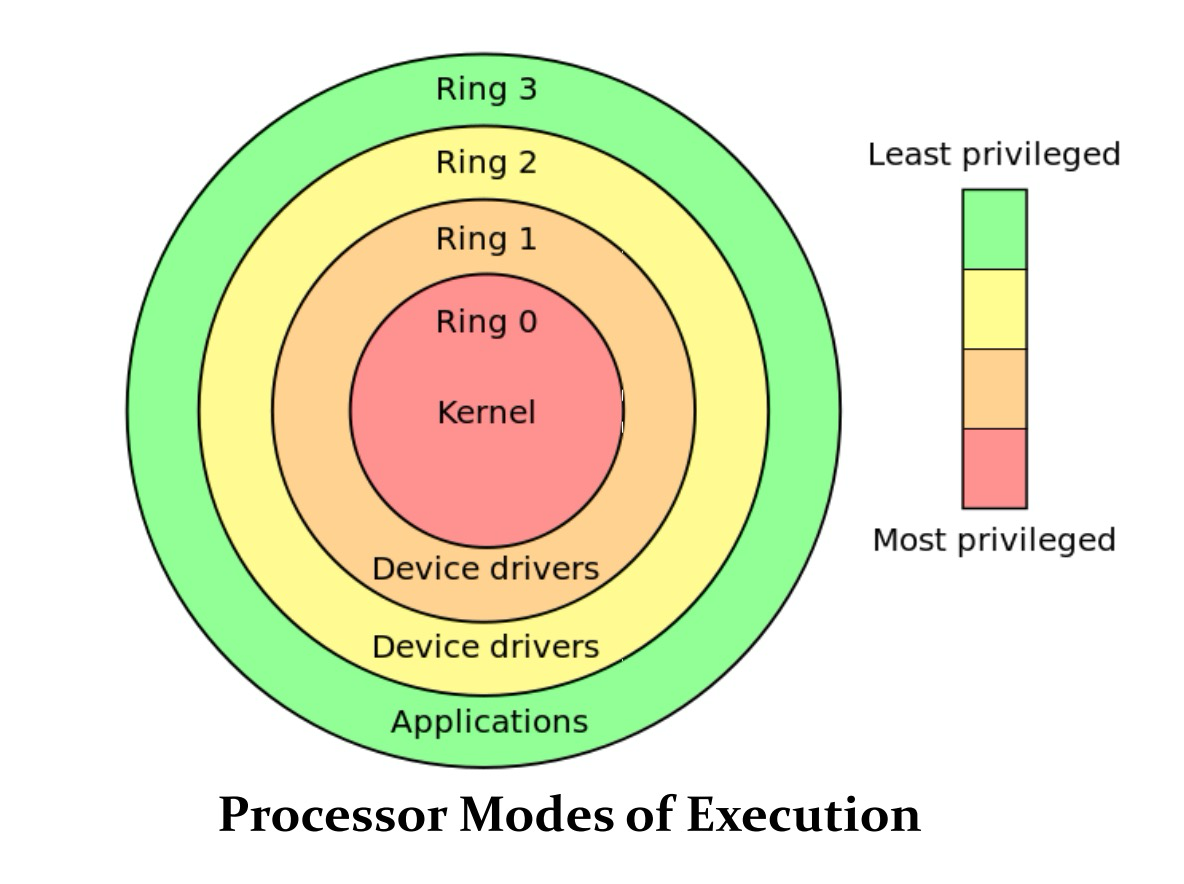
为了加强硬件保护,某些处理器指令受到限制,普通用户进程无法执行。
处理器以两种模式之一执行: 用户模式或监管模式。 当执行用户进程时,进程在用户模式下,并且只能执行其指令集的一个子集。 为了执行操作系统代码,必须以受控方式将处理器切换到监管模式,然后才能执行其完整指令集。
一种称为软件中断的特殊处理器指令可以切换到监管模式。
系统调用
进程自己只能计算,如果要访问硬件、与其他进程通信、创建新进程,必须要先跟操作系统通信,使用系统调用,等进程一觉醒来,自己要的东西就准备好了。
- 通常通过与用户空间进程链接的包装器库来访问。
- 包装器函数检查是否使用了正确的参数,并将调用软件中断机制。
- 系统调用的包装器 API 有助于应用程序代码在不同的内核和语言实现之间实现可移植性。
硬件中断
硬件中断可用来实现硬件与操作系统的通信。是硬件设备向操作系统发出异步事件通知的主要方式。设备无需等待操作系统主动查询 (轮询) ,而是主动告知。
-
高效设备管理: 硬件中断机制使得操作系统能够高效地管理大量的硬件设备。操作系统不必定期轮询每个设备的状态,而是只在设备需要关注时才会被中断。这大大提高了系统的效率。
-
防止CPU占用: 定时器 (Timer) 被用于防止某个用户程序进入死循环而持续占用 CPU 资源。在程序初始化时,定时器被设置为允许程序运行的最大时间。定时器每秒产生一个中断,当倒计时到零时,操作系统强制终止该程序的运行,保证了系统的公平性和稳定性。
Lecture 3: 进程调度--非抢占式调度
由于在计算机中,需要运行的进程的数量通常比处理器的数量多,而处理器同一时间只能执行一条指令。所以,进程与进程之间存在资源 (尤其是 CPU 时间) 的竞争。操作系统应当决定如何给这些进程分配资源。
从运行一个进程切换到运行另一个进程过程需要上下文切换
多处理器系统
多处理器系统,顾名思义,拥有多个 CPU (通常指多核 CPU,即把一块物理 CPU 分成多个核心) 。主要分为以下两种类型: 非对称多处理 (ASMP) 和对称多处理 (SMP) 。
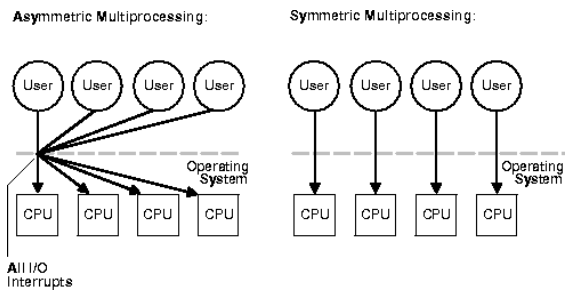
非对称多处理 (ASMP)
在 ASMP 架构中,每个处理器被分配特定的任务。其中,一个处理器作为**主处理器 (master) ,负责管理所有的 I/O 和中断,并向其他从处理器 (slave) **分配工作。
对称多处理 (SMP)
SMP 是一种更常见的架构。在 SMP 系统中,所有处理器都是对等的,没有主从之分。操作系统控制所有处理器,使它们执行相似的工作,并进行自我调度 (self schedule) 。处理器们通过总线共享物理内存,并拥有访问 I/O 设备的权限。
| 优点 | 非对称多处理 (ASMP) | 对称多处理 (SMP) |
|---|---|---|
| 优点 | 简化操作系统编程实现 | 所有处理器对等,更易于扩展和负载均衡 |
| 缺点 | 从处理器数量不足时,主处理器可能无法充分利用,导致性能受限 | 需要小心处理并行操作,保证共享数据完整性,避免数据竞争和不一致性 |
| 特点 | 每个处理器有特定任务,存在主从关系 | 所有处理器并行访问进程队列,自我调度 |
调度性能参数
吞吐量: 单位时间能完成的任务数量
周转时间: 从任务进入等待队列到任务执行完成之间的时间
响应时间: 从任务进入等待队列到任务第一次执行之间的时间
好的进程调度实现就是要平衡周转时间和响应时间
先到先服务调度 (FCFS)
FCFS (First-Come, First-Served) ,即先来先服务,是一种最简单、最基本的CPU调度算法。它的核心思想是按照进程到达就绪队列的先后顺序来分配CPU资源。
- 进程到达: 当一个进程进入就绪队列时,它会被放置在队列的末尾。
- CPU调度: CPU调度器从就绪队列的头部选择一个进程,并分配CPU资源给它。
- 执行: 被选中的进程开始执行,直到完成或发生阻塞 (例如等待I/O) 。
- 下一个进程: 当当前进程完成或阻塞时,CPU调度器再次从就绪队列的头部选择下一个进程,重复上述步骤。
简单来说,就是谁先来排队,谁就先获得服务。优点是容易实现,缺点是会造成护航效应 (一个CPU密集型的大进程独占CPU,导致I/O密集型的小进程等待I/O完成的时间延长) ,在交互型任务中是性能灾难。
最短作业调度 (SJF)
SJF (Shortest Job First) ,即短作业优先调度算法,是一种非抢占式的 CPU 调度算法。它的核心思想是优先选择就绪队列中执行时间最短的进程来执行,以尽可能地减少平均等待时间。
- 进程到达: 当一个进程进入就绪队列时,SJF算法会评估所有就绪进程的执行时间。
- 选择最短作业: CPU调度器从就绪队列中选择执行时间最短的进程,并分配CPU资源给它。
- 执行: 被选中的进程开始执行,直到完成或发生阻塞 (例如等待I/O) 。
- 下一个进程: 当当前进程完成或阻塞时,CPU调度器再次从就绪队列中选择执行时间最短的进程,重复上述步骤。
其关键在于每次调度时,都选择当前就绪队列中最短的作业来执行。相比于 FCFS,SJF 优化平均等待时间,但是SJF算法需要预先知道每个进程的执行时间,这在实际应用中很难实现。通常只能通过估计来近似,但估计可能不准确。
估计 CPU 突发长度
$t_{n+1} = a t_n + (1 - a) T_n$
- $t_n$: 第 n 个突发的长度 (即最近一次突发的实际长度) 。
- $T_n$: 前 n 个突发的平均长度。
- $t_{n+1}$: 对下一个突发 (n+1) 的长度的估计值。
- $a$: 一个权重因子,取值范围为 0 到 1。它用于调整近期活动和过去活动对估计值的影响程度。
最高响应比优先调度 (HRN)
HRN (Highest Response Ratio Next),即最高响应比优先调度算法,是对 SJF (短作业优先) 算法的一种改进,旨在解决 SJF 算法可能导致长作业“饥饿”的问题。它在每次选择下一个要执行的进程时,不是简单地选择执行时间最短的进程,而是计算每个就绪进程的**响应比 (Response Ratio) **,然后选择响应比最高的进程执行。
$响应比 = (等待时间 + 执行时间) / 执行时间$
- 进程到达: 进程进入就绪队列。
- 计算响应比: 每次需要进行进程调度时,计算当前就绪队列中所有进程的响应比。
- 选择最高响应比: 选择响应比最高的进程,并分配CPU资源给它。
- 执行: 被选中的进程开始执行,直到完成或发生阻塞。
- 下一个进程: 当当前进程完成或阻塞时,重复步骤2-4。
HRN算法通过引入等待时间,使得等待时间较长的作业的响应比会随着等待时间的增加而增大,从而提高了长作业被选中的概率,缓解了长作业饥饿的问题。对于执行时间短的作业,即使等待时间较短,其响应比也可能较高,因此HRN算法也能兼顾短作业。
Lecture 4: 进程调度--抢占式调度
轮转调度 (RR)
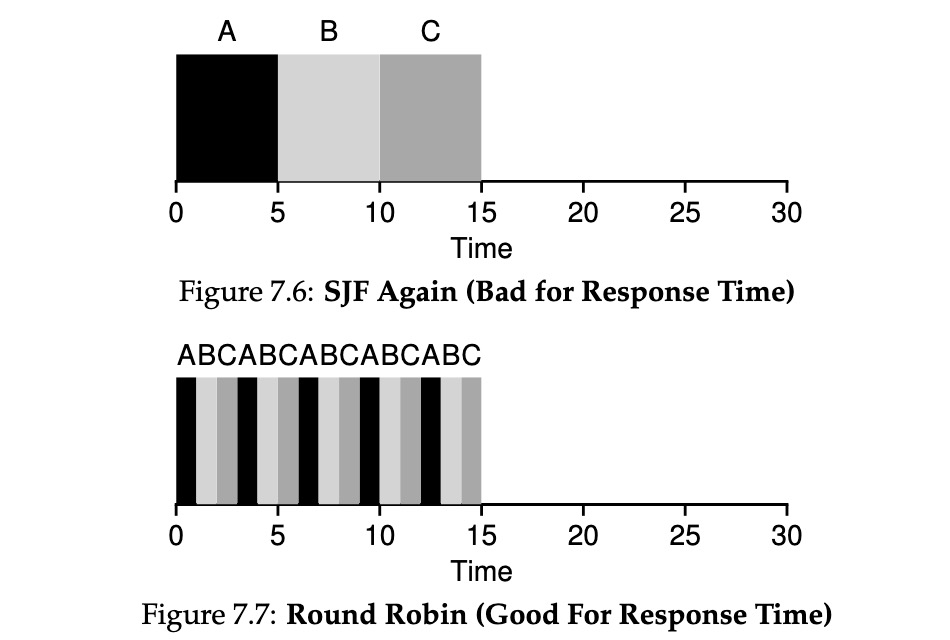
是 Round Robin 的缩写。RR 调度算法其实就是加上了抢占机制的 FCFS 调度算法,它可以让所有进程的响应时间都比较优,在分时系统和多任务系统上很重要。
定义一个较小的时间单元为**时间量 (time quantum) ,或称作调度量子 (scheduling quantum) **,通常是 10~100ms。所有进程都是轮流调用的。如果进程运行超过了时间片还没结束,那么就中断它,重新放回就绪队列的尾部,进行上下文切换。相比于 SJF,有效提升了其在响应式任务的性能表现。
多级反馈队列 (MLFQ)
MLFQ 是一种调度算法,旨在解决以下两个主要问题:
- 优化周转时间: 通过优先运行较短的作业来减少周转时间。但操作系统通常不知道作业的运行时间。
- 优化响应时间: 通过保持系统的交互性,最小化响应时间。轮询调度算法 (Round Robin) 可以减少响应时间,但对周转时间不利。
- 避免饥饿: 如果系统中有太多的互动任务,它们将结合使用以占用所有CPU时间,因此长期运行的工作将永远不会收到任何CPU时间,饿死了=( 。
其遵循以下调度规则:
- **规则 1: ** 如果 Priority(A) > Priority(B),则 A 运行 (B 不运行) 。
- **规则 2: ** 如果 Priority(A) = Priority(B),则 A 和 B 采用轮询调度 (Round Robin) 运行,使用给定队列的时间片 (量子长度) 。
- **规则 3: ** 当作业进入系统时,它被放置在最高优先级 (最顶层队列) 。
- **规则 4: ** 一旦作业在给定级别用完了它的时间配额 (无论它放弃了 CPU 多少次) ,它的优先级就会降低 (即,它向下移动一个队列) 。
- **规则 5: ** 经过一段时间 S 后,将系统中的所有作业移动到最顶层队列。
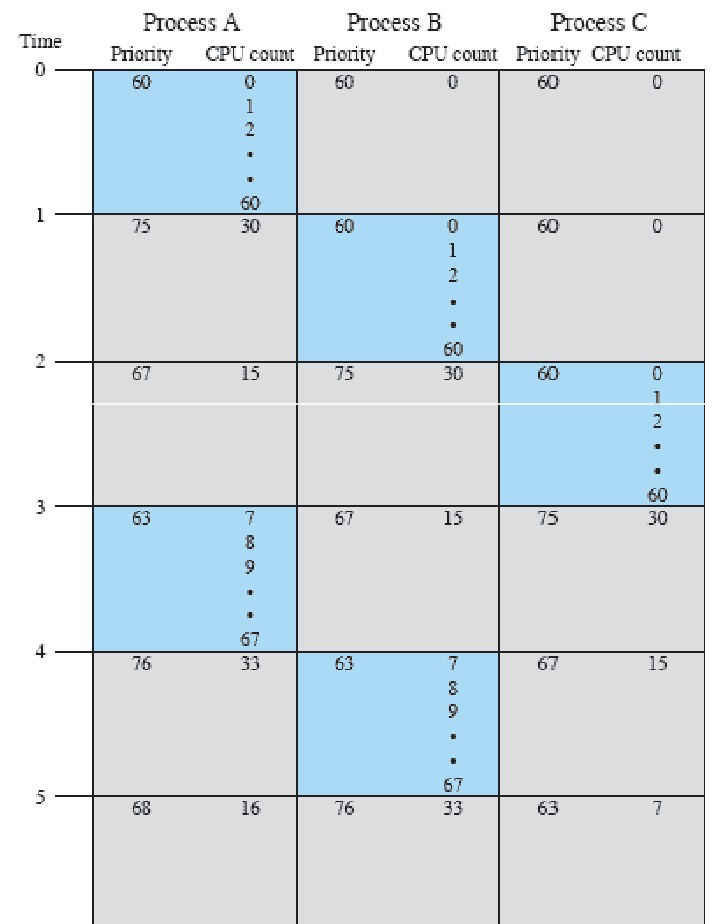
传统Unix调度器中进程优先级计算公式:
$P_j(i) = \text{Base}_j + \frac{\text{CPU}_j(i)}{2} + \text{nice}_j$
- $P_j(i)$ 表示第 j 个进程在第 i 个时间间隔的优先级。
- $\text{Base}_j$ 表示第 j 个进程的基本优先级。
- $\text{CPU}_j(i)$ 表示第 j 个进程在第 i 个时间间隔的CPU使用情况。
- $\text{nice}_j$ 表示第 j 个进程的nice值。
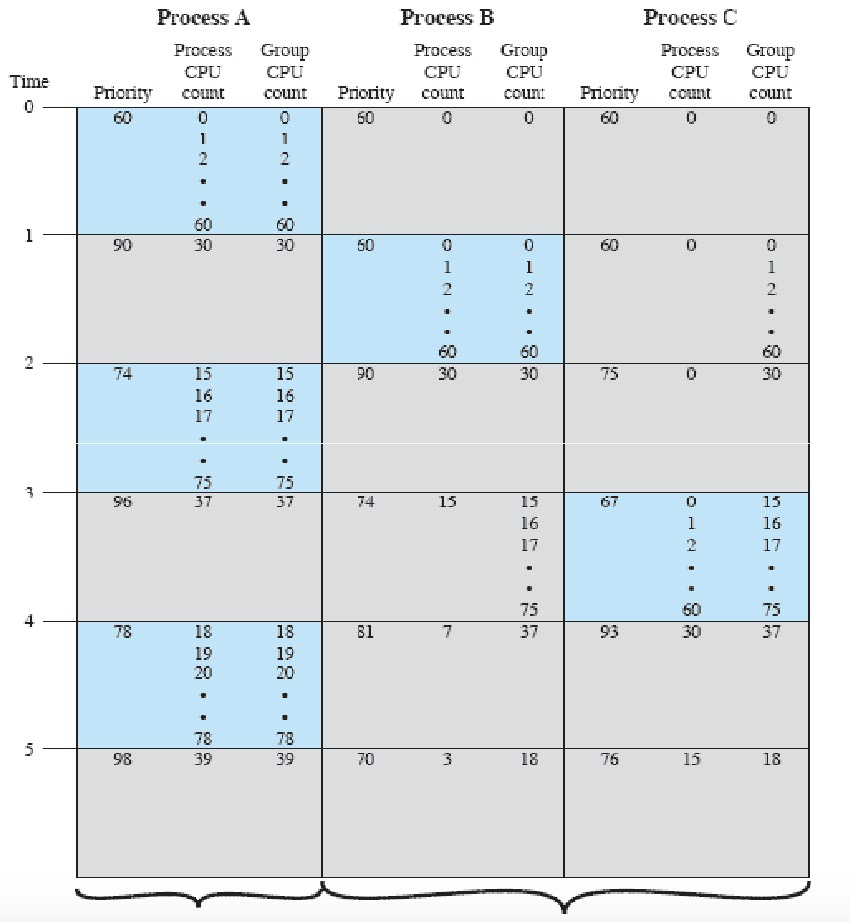
公平共享调度
NUIX 是多用户操作系统,我们引入公平共享调度,旨在确保在多用户多任务系统中,每个用户或每个应用能够获得公平的 CPU 时间分配,而不仅仅是在所有进程之间实现公平。
公平共享调度通常需要修改进程优先级计算方式,以便为每个进程组分配一定比例的处理器时间。例如,如果有 k 个独立的组,每个组具有不同的权重 $W_k$,则进程的优先级计算公式为:
$P_j(i) = \text{Base}_j + \frac{\text{CPU}_j(i)}{2} + \frac{\text{GCPU}_k(i)}{4 \times W_k}$
- $P_j(i)$: 进程 j 在时间间隔 i 的优先级。
- $\text{Base}_j$: 进程 j 的基本优先级。
- $\text{CPU}_j(i)$: 进程 j 在时间间隔 i 的 CPU 使用情况。
- $\text{GCPU}_k(i)$: 第 k 个组在时间间隔 i 的 CPU 使用情况。
- $W_k$: 分配给第 k 个组的 CPU 时间权重,满足 $0 < W_k \le 1$,且所有 $W_k$ 的总和等于 1。
其中组 CPU 使用情况采用类似的衰减公式来计算:
$\text{GCPU}_k(i) = \frac{\text{GCPU}_k(i-1)}{2}$
- $\text{GCPU}_k(i)$ 表示第 k 个进程组在第 i 个时间间隔的CPU使用情况。
- $\text{GCPU}_k(i-1)$ 表示第 k 个进程组在前一个时间间隔的CPU使用情况。
Lecture 5: 进程调度--多处理器调度
在单 CPU 环境下,多进程处理容易遭遇性能瓶颈。增加处理器数量似乎是提高系统吞吐量的直接方法,但实际效果往往不如预期。这主要是因为调度问题变得更加复杂,并且不存在能完美优化所有场景下处理器利用率的“万能”方案。总线、I/O 操作、共享内存、操作系统代码,以及维护缓存一致性等因素,都可能导致性能下降。
排队论
**排队论(Queuing Theory)**是研究等待队列或排队现象的数学理论。其目的是在各种实际服务系统中,通过对服务对象数量的控制和队列的合理组织,实现最大化吞吐量和减少排队时间。
在建模和管理任何系统的性能时,必须考虑以下几个关键因素:
- 到达模式:任务或客户到达系统的模式。
- 队列和调度策略:任务如何排队以及如何被调度。
- 服务能力:系统处理任务的能力。
对于计算机系统,文档假设任务的到达是随机的,并且是独立的。虽然实际情况可能更复杂,例如任务可能成批到达,或者在某些时段集中到达,但在建模时,通常假设任务到达是完全随机的。平均到达率用 λ(lambda)表示,代表在观察期内到达系统的平均任务数。排队论的目标之一是设计能够应对这些波动的系统。
泊松分布(Poisson Distribution)
泊松分布描述了在给定的时间间隔内,随机且独立事件发生的概率。其概率质量函数(PMF)为:
$P(k \text{ events in interval}) = \frac{\lambda^k e^{-\lambda}}{k!}$
- $λ$ 是单位时间(或间隔)内事件发生的平均次数。
- $k$ 是事件在指定间隔内发生的次数。
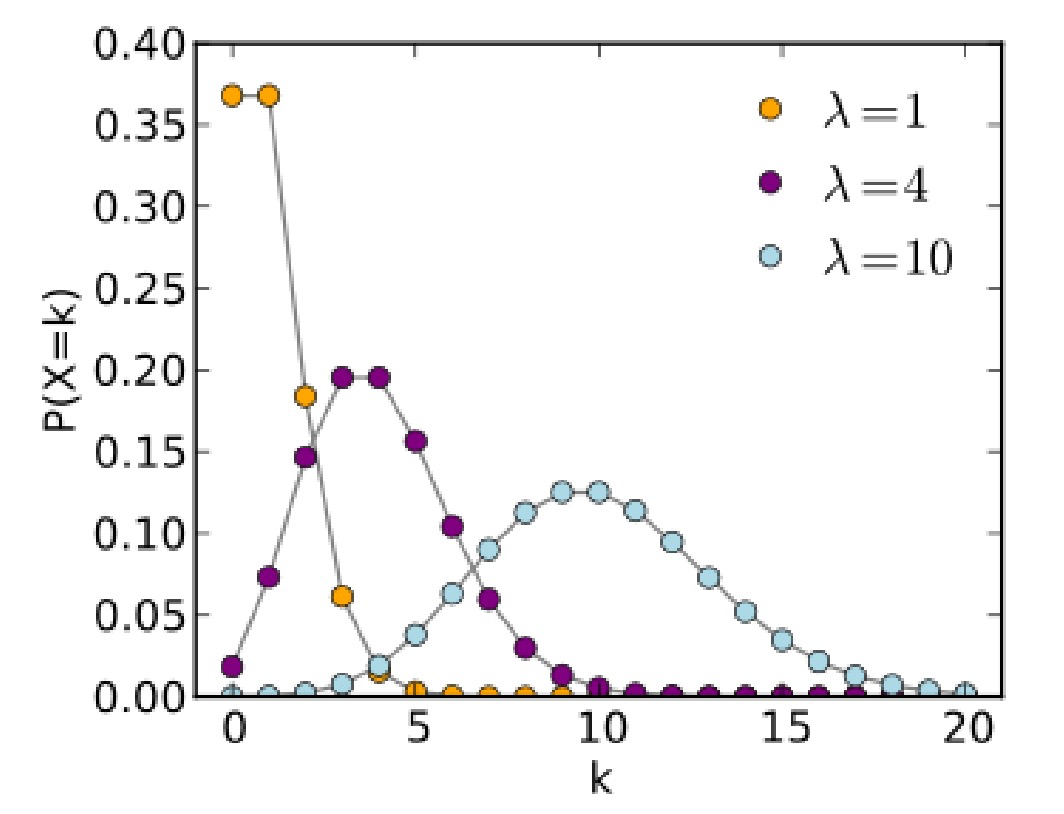
对于不同的平均到达率 λ,纵轴表示在给定间隔内发生 k 个事件的概率。
多处理器的服务能力
**无共享队列的多处理器系统:**如果每个处理器各自独立工作,不共享任务队列,那么单个处理器的处理能力可表示为:
$T = \frac{1}{\mu - \lambda}$
- $T$:单个处理器的平均响应时间或周转时间。
- $μ$:单个处理器的平均服务速率。
- $λ$:到达该处理器的任务平均速率。
共享队列的多处理器系统:如果所有处理器共享一个统一的任务队列,那么理想情况下每个处理器的处理能力可表示为:
$T_l = \frac{1}{n\mu - n\lambda}$
- $T_l$: 理想状态下每个处理器的平均响应时间或周转时间。
- $n$: 处理器的数量。
- $μ$: 单个处理器的平均服务速率。
- $λ$: 系统总的任务平均到达率。
其他系统
分布式系统
分布式系统由通过局域网连接的物理上分散的计算机系统集合组成。由于网络环境,调度更加复杂,因为系统信息并非集中管理,而是分散在网络的各个节点上。
实时系统
一些计算机系统是为特定的工业过程控制应用而设计的。考虑一条生产线,原材料从线的一端供应,成品从另一端出来。
实时系统是指其正确性不仅取决于计算结果的正确性,还取决于结果产生的时间,必须在严格的时间限制(截止时间)内响应事件,否则可能导致系统故障(硬实时系统)或降低服务质量(软实时系统)。