Lecture 1: CPU
计算机架构
计算机主要采用两种架构:
- 冯诺依曼架构:使用同一个存储器,经由同一个总线传输指令和数据.
- 哈佛架构:使用独立的指令存储器和数据存储器,提升执行效率.
Note
现代高性能CPU通常结合冯诺依曼和哈佛架构的特点,例如通过“拆分缓存”设计来优化性能。
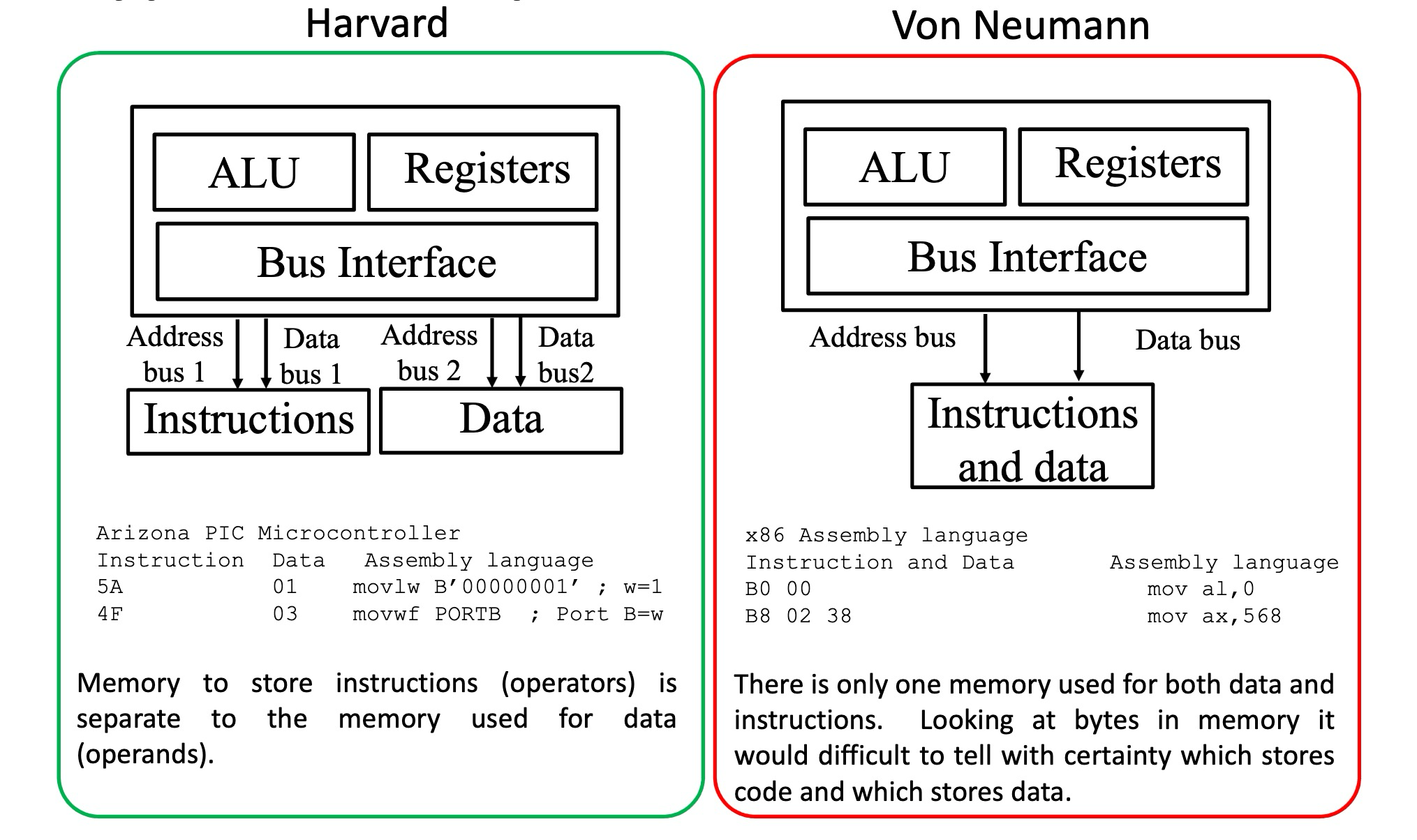
具体而言,冯诺依曼架构和哈佛架构的区别体现在以下几点:
- 存储器结构:冯诺依曼架构使用统一存储器,而哈佛架构使用独立的指令和数据存储器.
- 总线设计:冯诺依曼架构使用单条总线,哈佛架构使用多条独立总线.
8086的硬件组成
8086 CPU主要由以下两部分组成:
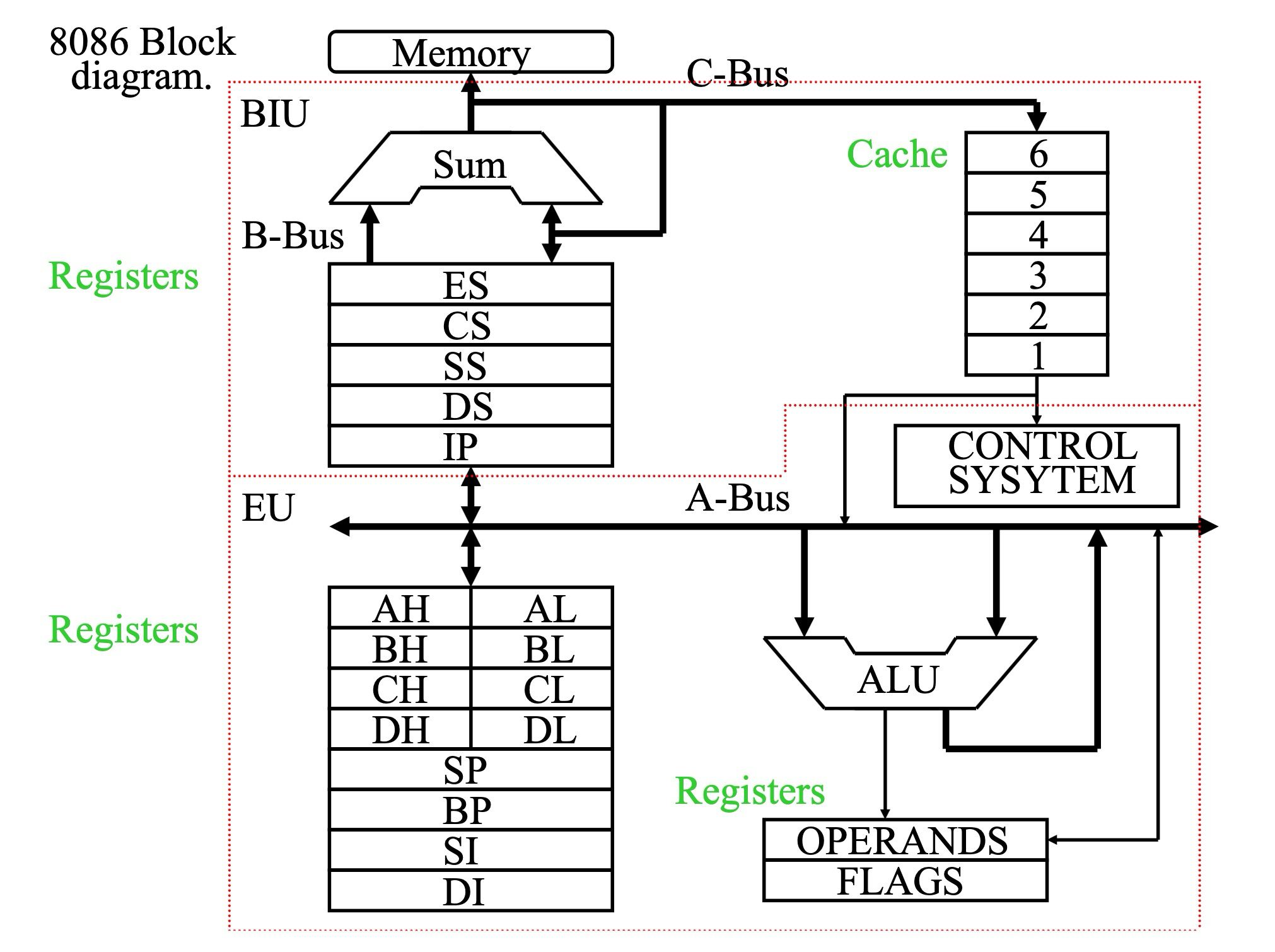
BIU: 总线接口单元
- 功能:负责发送地址,从内存中获取指令,并执行端口和内存的读写操作.
- 特点:BIU通过总线与外部设备通信,是CPU与内存之间的桥梁.
EU: 执行单元
- 功能:解码指令并执行指令,包含算术逻辑单元 (ALU) 和控制电路.
- 特点:EU是CPU的核心执行模块,负责完成具体的计算任务.
指令周期是8086 CPU的基本工作单位,具体流程如下:
- Fetch:从内存中获取指令.
- Decode:对指令进行解码.
- Execute:执行解码后的指令.
Note
8086 CPU的指令周期通常占用4个时钟周期,因此1GHz的处理器每秒约可执行2.5亿条指令。
ALU: 算术逻辑单元
8086的ALU支持以下基本操作:
- 算术运算:
- ADD:加法
- SUB:减法
- INC:自增
- DEC:自减
- 逻辑运算:
- AND:逻辑与
- OR:逻辑或
- XOR:逻辑异或
- NOT:取反
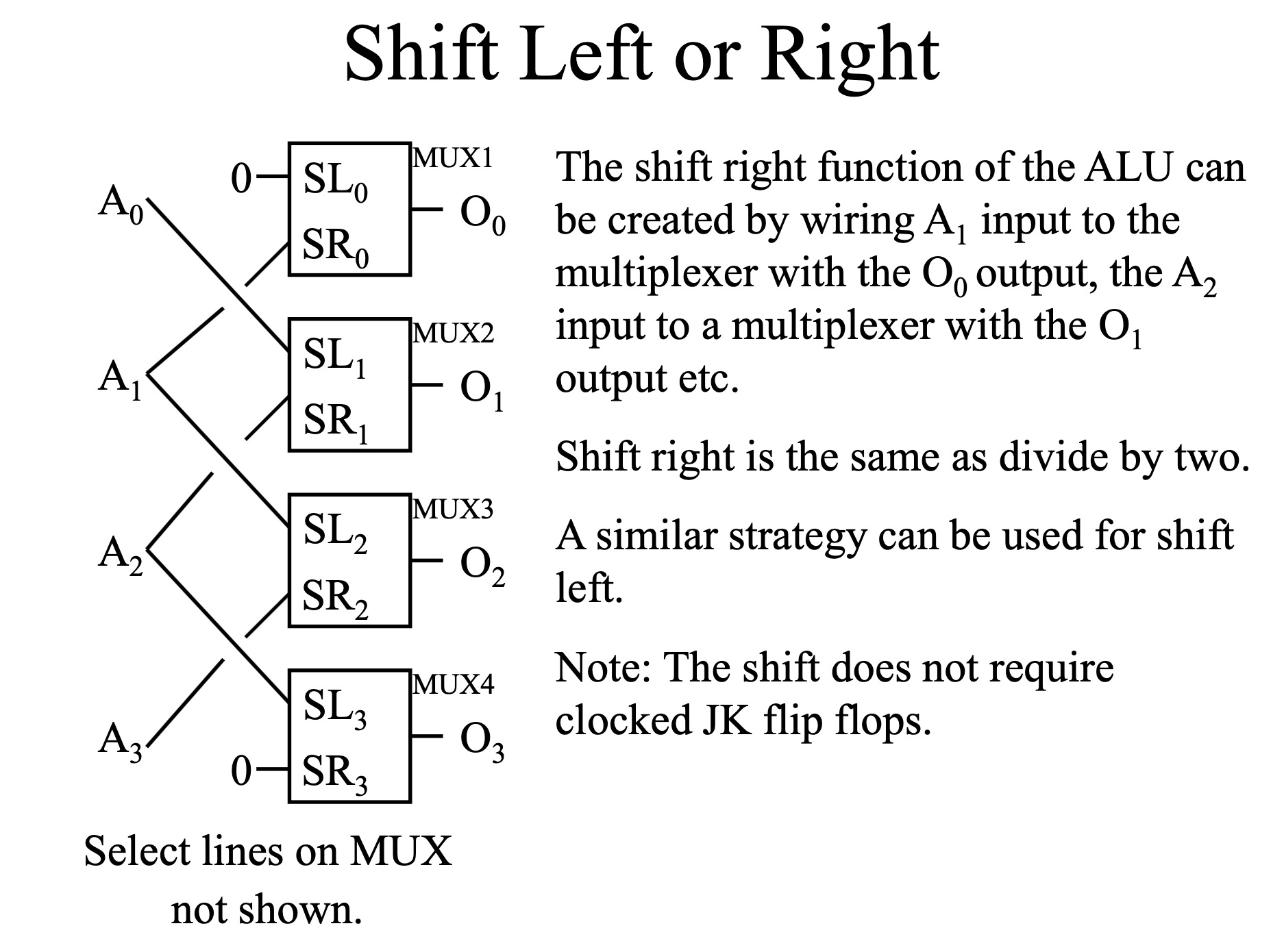
此外,ALU还支持移位操作,具体包括:
- 逻辑移位:在移位操作中,空出的位置填充逻辑0.
- 算术移位:在移位操作中,空出的位置填充符号位 (最高位) .
Note
移位操作在二进制运算中非常重要,常用于快速实现乘除法。

左移和右移的实现方法如下:
- 左移:将二进制数的所有位向左移动一位,最低位填充0.
- 右移:将二进制数的所有位向右移动一位,最高位填充符号位 (逻辑移位时填充0,算术移位时填充符号位) .
Lecture 2: Assembly Language (Ⅰ)
寄存器们
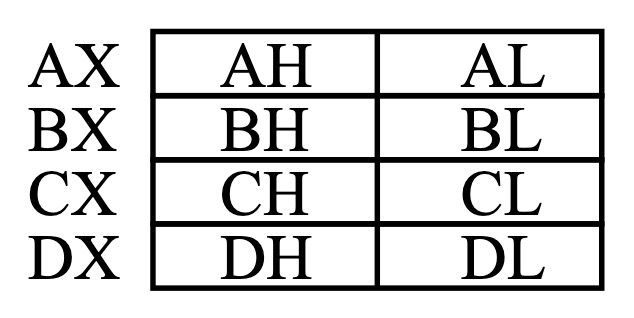
通用寄存器
- 通用寄存器:8086有8个通用寄存器,可以将它们视为8个变量,某些指令可以成对使用寄存器,从而提供16位操作。当用作寄存器对时,它们被赋予集体名称AX、BX、CX、DX。
指针和变址寄存器
- SP (堆栈指针):指向堆栈顶部。
- BP (基址指针):用于访问堆栈中的参数和局部变量。
- SI (源变址寄存器):用于字符串操作中的源地址。
- DI (目的变址寄存器):用于字符串操作中的目的地址。
段寄存器
- CS (代码段):指向当前代码段。
- DS (数据段):指向当前数据段。
- SS (堆栈段):指向当前堆栈段。
- ES (附加段):指向附加数据段。
控制寄存器
- IP (指令指针):指向下一条要执行的指令。
- FLAGS (标志寄存器):存储状态和控制标志。
标志位寄存器
8086在特殊的16位标志寄存器中跟踪某些计算的结果:
- U: Undefined (未定义)
- OF: Overflow flag (溢出标志)
- DF: String direction flag (字符串方向标志)
- IF: Interrupt enable flag (中断启用标志)
- TF: Single step trap flag (单步陷阱标志)
- SF: Sign flag (符号标志, 结果的最高有效位)
- ZF: Zero flag, set if result=0 (零标志, 如果结果为零则设置)
- AF: BCD Carry flag (BCD 进位标志)
- PF: Parity flag (奇偶校验标志)
- CF: Carry flag (进位标志)

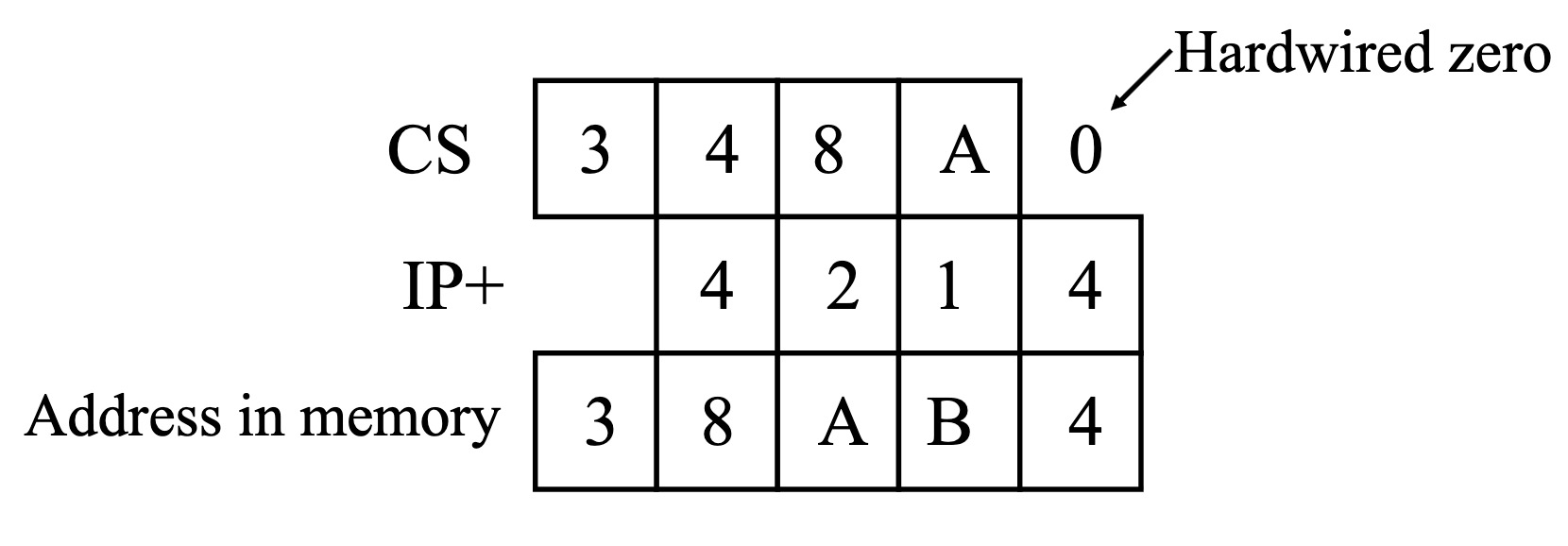
8086的分段内存模型
分段内存模型概述
- 因为8086的寄存器只有16位,为了让它能访问20位的地址,需要使用CS寄存器给出代码段地址,IP寄存器给出偏移距离,然后计算出指令的内存地址位置。
数据段寄存器 (DS)
- DS (Data Segment Register):指向程序的数据所在的内存段。DS寄存器存储程序数据段的起始地址。访问数据时,需要指定一个偏移量,指明数据在数据段内的位置,通过DS:偏移量配合工作。
Note
偏移量的来源包括:
- 直接寻址:偏移量可以是指令中直接给出的一个常量 (例如
mov ax, [0x1234]) 。 - 寄存器寻址:偏移量可以使用通用寄存器 (例如
BX,SI,DI) (例如mov ax, [bx]) 。 - 寄存器 + 常量:偏移量可以是寄存器值 + 常量 (例如
mov ax, [bx+0x10]) 。
堆栈段寄存器 (SS)
- SS (Stack Segment Register):指向堆栈所在的内存段。SS寄存器存储堆栈段的起始地址。
- SP寄存器:指向当前栈顶的地址,它始终指向栈中最后一个被压入 (pushed) 的值的位置。
- BP寄存器:通常指向当前栈帧的基地址,主要用途是:
- 在函数调用过程中,BP作为访问函数局部变量、函数参数的基址。
- 方便函数内部访问栈上的数据。
- 可以在函数返回时恢复栈帧。
附加段寄存器 (ES)
- ES (Extra Segment Register):用于字符串操作的额外数据段,通常作为目标段使用,通过ES:DI配合工作。
MASM 程序结构
程序结构
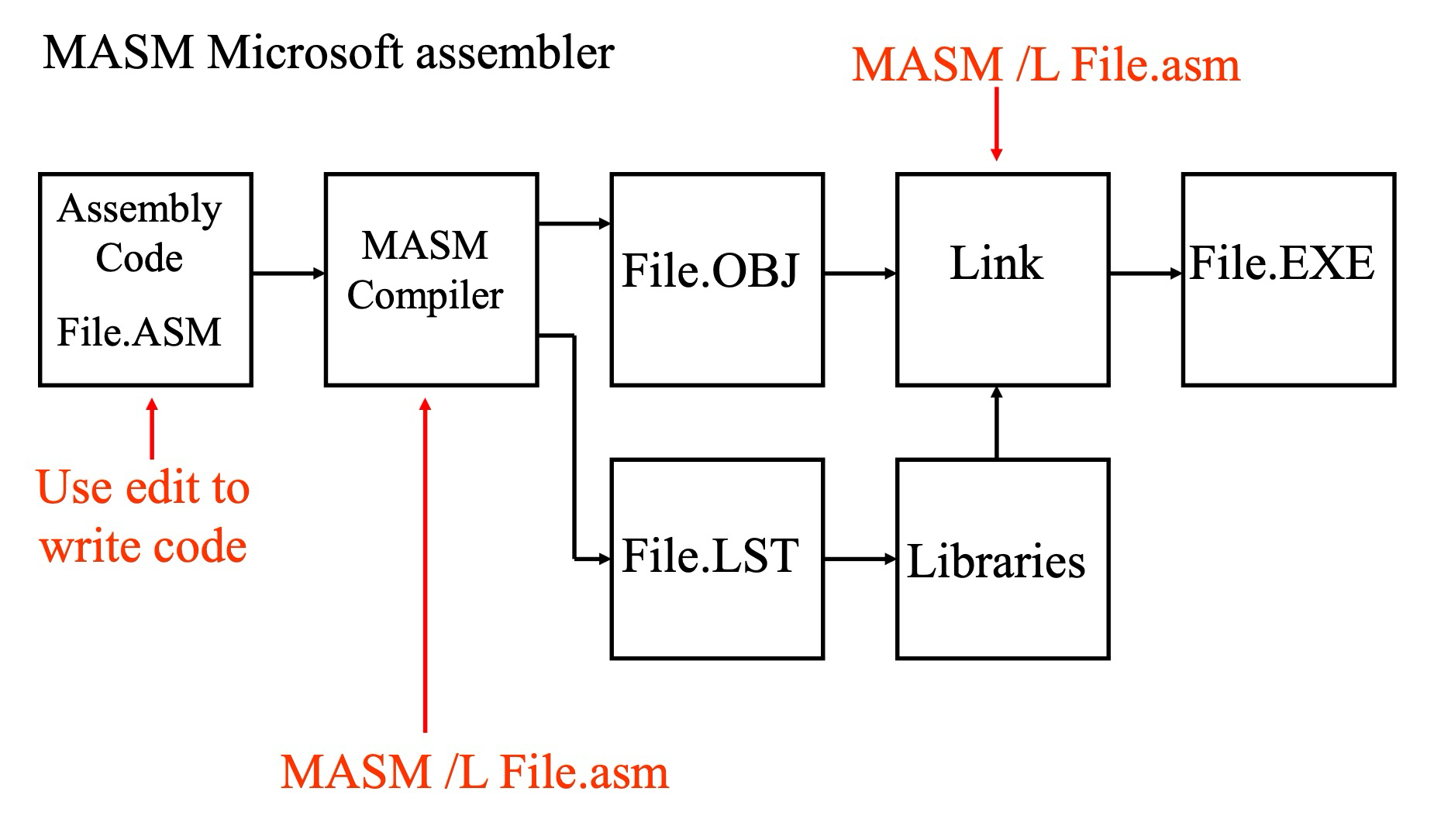
编译过程
运算符和操作数
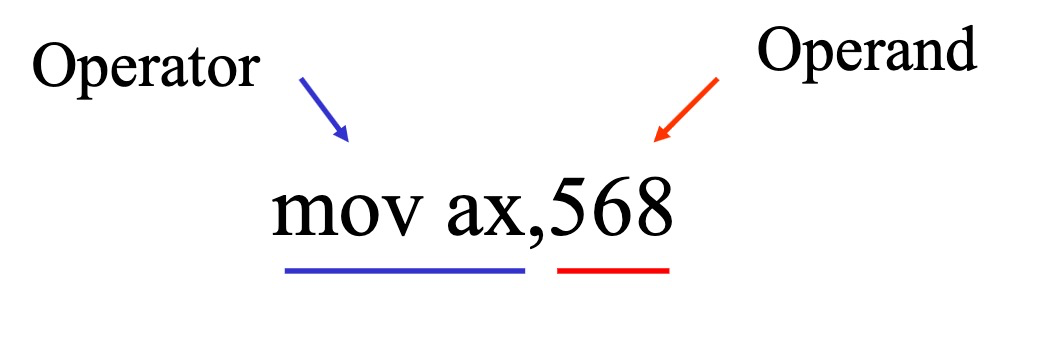
Note
这里的Operand也可以称作立即数。
Hello, world !
详细实现
.MODEL medium
.STACK
.DATA
msg1 db "Hello, world.$"
.CODE
.STARTUP
mov ax,@data ; 将 ax 寄存器的值设置为 @data 段的值
mov ds,ax ; 将 DS 寄存器的值设置为 @data 段的值
lea bx,msg1 ; 获得msg1的偏移地址, 在这个情况下(DS<<4+BX)就是实际的存储msg1的地址
back:
mov dl,[bx] ; 间接寻址, 获取bx寄存器对应的内存地址的第一个值到dx寄存器
cmp dl,'$' ; 将 dl 寄存器中的字符与字符 $ 进行比较
jz done ; 如果 dl 寄存器中的字符和$相等 (即 ZF 标志位为 1 ), 则跳转到done执行
mov ah,02h ; 设置 DOS 中断 21h 的功能号为 02h, 表示调用显示字符的功能
int 21h ; 调用 DOS 中断 21h, 将 dl 寄存器中的字符显示在屏幕上
inc bx ; 将 bx 寄存器的值加 1, 指向字符串 msg1 的下一个字符
jmp back ; 无条件跳转到 back 标签处
done:
nop ; 空操作指令
.EXIT
END简洁实现
.MODEL small
.STACK
.DATA
msg DB 'Hello, World!$' ; 定义字符串,以$结尾
.CODE
.STARTUP
mov ax, @data
mov ds, ax
mov ah, 09h ; 打印字符串
lea dx, msg
int 21h
.EXIT
END常用 21h 功能号
- 01h: 从键盘读取一个字符, 并将字符存入 AL 寄存器
- 02h: 在屏幕上输出 DL 寄存器中的字符
- 09h: 在屏幕上输出以 DS:DX 指向的、以 $ 结尾的字符串
- 0Ah: 从键盘读取一个字符串
- 3Ch: 创建一个文件
- 3Dh: 打开一个文件
- 3Eh: 关闭一个文件
- 3Fh: 从文件中读取数据
- 40h: 向文件中写入数据
- 4Ch: 退出程序
重要ASCII码
- 0x0A: Line Feed (LF), 换行,等价于
\n - 0x0D: Carriage Return (CR), 回车,等价于
\r
Lecture 3: Assembly Language (Ⅱ)
寻址模式
立即寻址
- 立即寻址是指运算数以字面量形式写在指令里面,如
mov ax, 10。这里的运算数也称作立即数。 - 立即数直接嵌入指令中,无需额外的寻址操作,因此执行速度快。
寄存器寻址
- 寄存器寻址指运算数保存在某个通用寄存器当中,如
mov ax, bx。 - 寄存器的访问是在CPU内部的,速度非常快,因此这种寻址方式效率高。
直接寻址
- 直接寻址如
mov ax, Count,把data段当中的变量Count作为操作数。 - 实际上,变量
Count在汇编器的眼里,只是对应数据所在的地址。因此,这相当于把Count所在地址的值赋给ax。 - 如果要指定其他的段,可以写作
mov ax, ES:Count,即表示在额外段上的内容。
寄存器间接寻址
- 寄存器间接寻址是把偏移地址存在寄存器 (通常是索引寄存器BX, BP, SI或DI) 当中。如果是BP,对应的段就是栈段,否则是数据段。
- 这种寻址方式与高级语言中的数组访问类似:
mov ax, [bx]表示ax = array[bx]mov [bx], ax表示array[bx] = ax
8086 指令格式

Byte 1
- Opcode (操作码): 决定指令的具体动作 (如
MOV) 。 - D (方向旗标): 指明数据传输的方向,是从源到目标,还是从目标到源。
Byte 2
- W (字/字节): 指定数据大小,16位字还是8位字节。
- Mod (寻址模式): 确定操作数地址的获取方式。
- Reg (寄存器): 指示一个寄存器。
- R/M (寄存器/内存): 指示另一个操作数是寄存器还是内存。
Low Byte/High Byte
- 可选字段,用于存放立即数或内存地址偏移量。
8086 寄存器编号
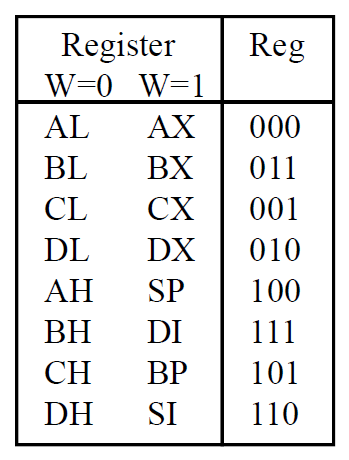
8086 寻址模式
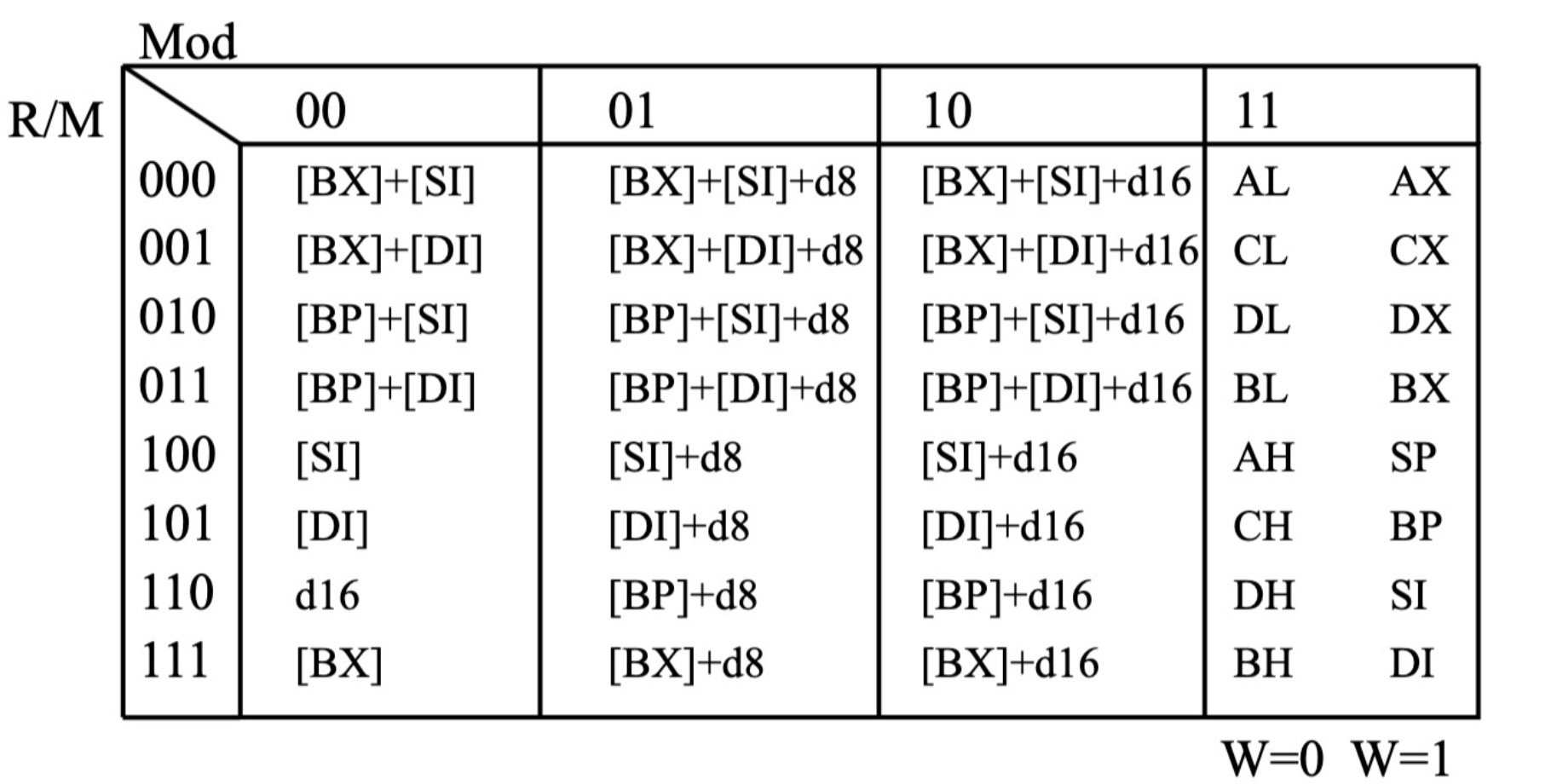
寻址模式详解
- Mod=00: 没有偏移量,或只是使用寄存器进行内存间接寻址。
- Mod=01: 8位偏移量 (d8) ,需要额外的1个字节来存储偏移量。
- Mod=10: 16位偏移量 (d16) ,需要额外的2个字节来存储偏移量。
- Mod=11: 寄存器寻址,直接使用寄存器作为操作数,不涉及内存访问。
示例
mov SP, BX的二进制指令是:
| opcode | D | W | Mod | Reg | R/M |
|---|---|---|---|---|---|
| 100010 | 1 | 1 | 11 | 100 | 011 |
mov |
to register | word | 寄存器寻址模式 | to SP | to BX |
Lecture 4: Assembly Language (Ⅲ)
算数运算命令
| 指令 | 代码 | 作用 |
|---|---|---|
| ADD | ADD AX, BX |
加法运算, 将 AX 和 BX 相加, 结果存入 AX |
| ADC | ADC AX, BX |
带进位的加法运算, 将 AX, BX, CF 相加, 结果存入 AX |
| SUB | SUB AX, BX |
减法运算, 将 AX 减去 BX, 结果存入 AX |
| MUL | MUL BX |
无符号乘法, 将 AX 和 BX 相乘, 结果存入 DX:AX |
| IMUL | IMUL BX |
有符号乘法, 将 AX 和 BX 相乘, 结果存入 DX:AX |
| DIV | DIV BX |
无符号除法, 将 DX:AX 除以 BX, 商存入 AX, 余数存入 DX |
| IDIV | IDIV BX |
有符号除法, 将 DX:AX 除以 BX, 商存入 AX, 余数存入 DX |
Note
DIV 与 IDIV在除数是word(16bit)的时候, 被除数是 32 位的 DX:AX,DX的值可能会产生意想不到的结果
MUL 与 IMUL在乘数是word(16bit)的时候, 结果是32位的, 低 16 位保存在 AX 里面, 高 16 位保存到 DX 里面, 导致DX寄存器的值被覆盖
十进制算数

ASCII调整指令
mov al, '9' ; AL = 39h ('9'的ASCII码)
add al, '8' ; AL = 39h + 38h = 71h
aaa ; 调整AL为09h, AH += 1 (AH = 01h)
; 结果: AL = 09h, AH = 01h (表示BCD格式的17)
mov ax, 0507h ; AH = 05h, AL = 07h (表示未压缩BCD的57)
aad ; AX = 0037h (37的二进制形式)
mov bl, 6 ; BL = 6
div bl ; AX / BL, AL = 6 (商), AH = 1 (余数)
; 结果: AL = 06h, AH = 01hBCD调整指令
mov al, 59h ; AL = 59h (59的压缩BCD格式)
add al, 27h ; AL = 59h + 27h = 80h
daa ; 调整AL为86h (86的压缩BCD格式)
; 结果: AL = 86h
mov al, 47h ; AL = 47h (47的压缩BCD格式)
sub al, 59h ; AL = 47h - 59h = EEh (借位发生)
das ; 调整AL为88h (88的压缩BCD格式)
; 结果: AL = 88h逻辑指令
| 指令 | 示例 | 含义 |
|---|---|---|
AND |
AND A, B |
按位与 |
OR |
OR A, B |
按位或 |
XOR |
XOR A, B |
异或 |
BT |
BT Base, Offset |
指定地址的值赋给 CF |
BTC |
BTC Base, Offset |
指定地址位的值赋给 CF, 该位取反 |
BTR |
BTR Base, Offset |
指定地址位的值赋给 CF, 该位设零 |
BTS |
BTS Base, Offset |
指定地址位的值赋给 CF, 该位设一 |
BSF |
BSF A, B |
B 最低的 1 是第几位, 赋给 A |
BSR |
BSR A, B |
B 最高的 1 是第几位, 赋给 A |
逻辑偏移
| 指令 | 示例 | 含义 |
|---|---|---|
| SHL | SHL AX, 1 |
将AX寄存器的内容逻辑左移1位, 空出的位用0填充 |
| SHR | SHR BX, 2 |
将BX寄存器的内容逻辑右移2位, 空出的位用0填充 |
| SAL | SAL CX, 1 |
将CX寄存器的内容算术左移1位, 空出的位用0填充 (与SHL相同 ) |
| SAR | SAR DX, 3 |
将DX寄存器的内容算术右移3位, 空出的位用符号位填充 |
| ROL | ROL AL, 1 |
将AL寄存器的内容循环左移1位, 移出的位重新填充到右侧 |
| ROR | ROR BL, 2 |
将BL寄存器的内容循环右移2位, 移出的位重新填充到左侧 |
| RCL | RCL AX, 1 |
将AX寄存器的内容带进位循环左移1位, 进位标志 (CF) 参与循环 |
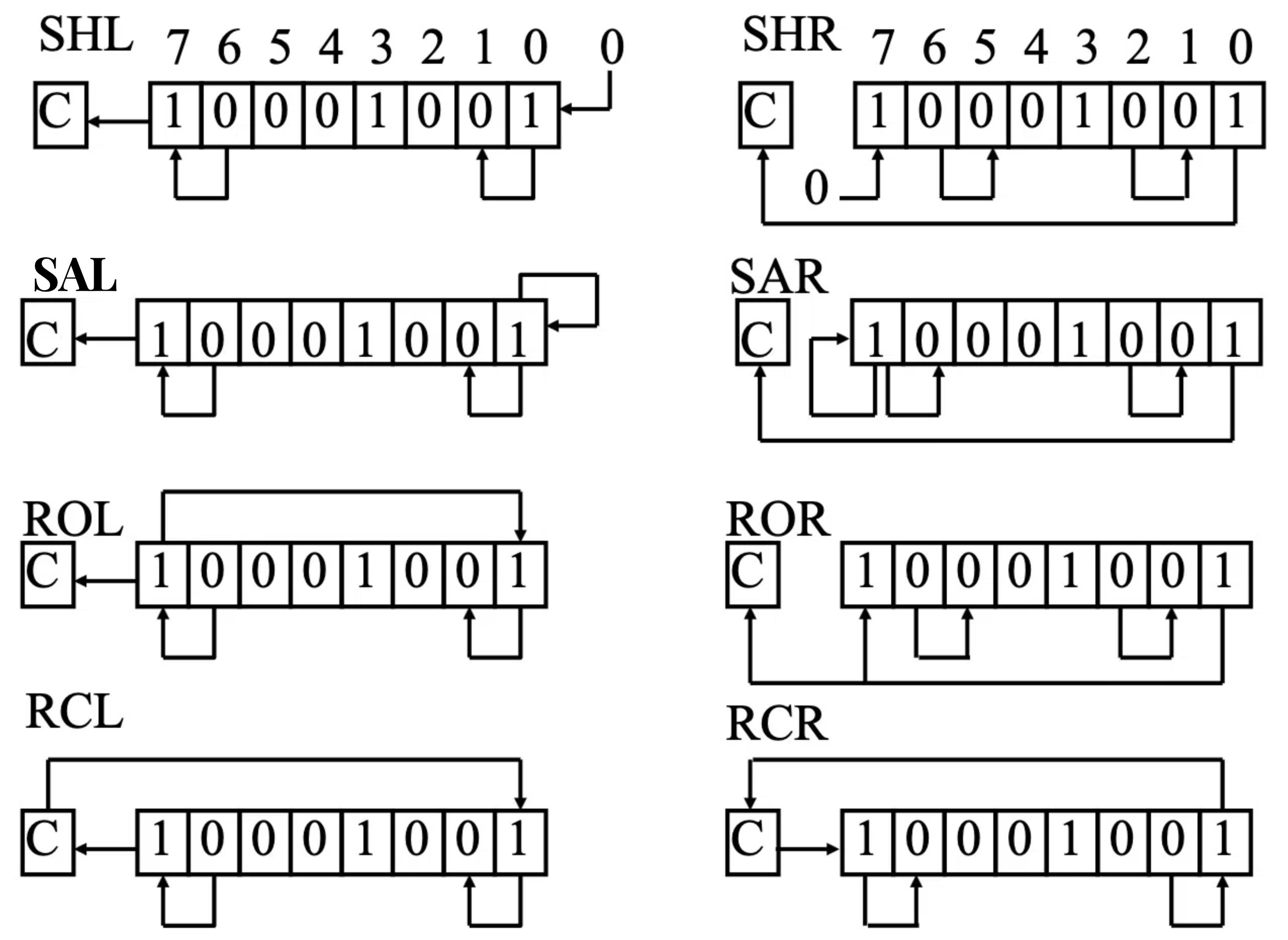
Note
逻辑右移 (SHR )用0填充空出的高位, 而算术右移 (SAR )用符号位填充空出的高位
标志位指令
| 指令 | 含义 |
|---|---|
CLC |
进位标志置零 |
STC |
进位标志设一 |
CMC |
进位标志取反 |
CLD |
方向标志置零 |
STD |
方向标志设一 |
CLI |
IF 置零, 关闭中断 |
STI |
IF 设一, 打开中断 |
比较指令
CMP 命令(Compare,比较)是 8086 汇编语言中的一个非常重要的指令。它用于 比较两个操作数的大小关系,但 不会修改任何操作数的值。 CMP 命令的 “结果” 不是直接返回一个数值,而是 设置 CPU 的标志寄存器 (Flags Register) 中的某些标志位。 这些标志位反映了比较的结果,然后可以被后续的条件跳转指令(如 JE, JNE, JL, JG 等)使用,以实现程序的分支控制。
CMP 指令的基本格式:
cmp destination, sourceCMP 指令的操作:
CMP destination, source 指令 在内部执行的操作是 destination - source (目的操作数减去源操作数)。 但是,减法的结果不会被存储到任何寄存器或内存位置,而是直接被丢弃。 CMP 指令的 唯一作用 就是根据这次减法运算的结果 设置标志寄存器中的标志位。
CMP 指令影响的标志位 (Flags):
CMP 指令主要影响以下几个标志位:
-
零标志位 (Zero Flag, ZF):
- ZF = 1: 如果
destination - source = 0,即destination等于source,则 ZF 被设置为 1。 - ZF = 0: 如果
destination - source ≠ 0,即destination不等于source,则 ZF 被设置为 0。
- ZF = 1: 如果
-
符号标志位 (Sign Flag, SF):
- SF = 1: 如果
destination - source的结果为 负数 (结果的最高位为 1,在有符号数表示中),则 SF 被设置为 1。 这通常意味着在 有符号数比较 中,destination小于source。 - SF = 0: 如果
destination - source的结果为 非负数 (结果的最高位为 0),则 SF 被设置为 0。 这通常意味着在 有符号数比较 中,destination大于等于source。
- SF = 1: 如果
-
进位标志位 (Carry Flag, CF):
- CF = 1: 如果在 无符号数减法 中,发生了 借位 (borrow),则 CF 被设置为 1。 这通常意味着在 无符号数比较 中,
destination小于source。 - CF = 0: 如果在 无符号数减法 中,没有发生借位,则 CF 被设置为 0。 这通常意味着在 无符号数比较 中,
destination大于等于source。
- CF = 1: 如果在 无符号数减法 中,发生了 借位 (borrow),则 CF 被设置为 1。 这通常意味着在 无符号数比较 中,
-
溢出标志位 (Overflow Flag, OF):
- OF = 1: 如果在 有符号数减法 中,发生了 溢出 (结果超出了有符号数的表示范围),则 OF 被设置为 1。 溢出标志用于判断 有符号数运算结果是否溢出。 在比较有符号数大小时,OF 需要和 SF 一起考虑。
- OF = 0: 如果在 有符号数减法 中,没有发生溢出,则 OF 被设置为 0。
分支控制
条件跳转是短跳转, 操作数是一个字节, 允许向后跳转 -128 或向前跳转 +127
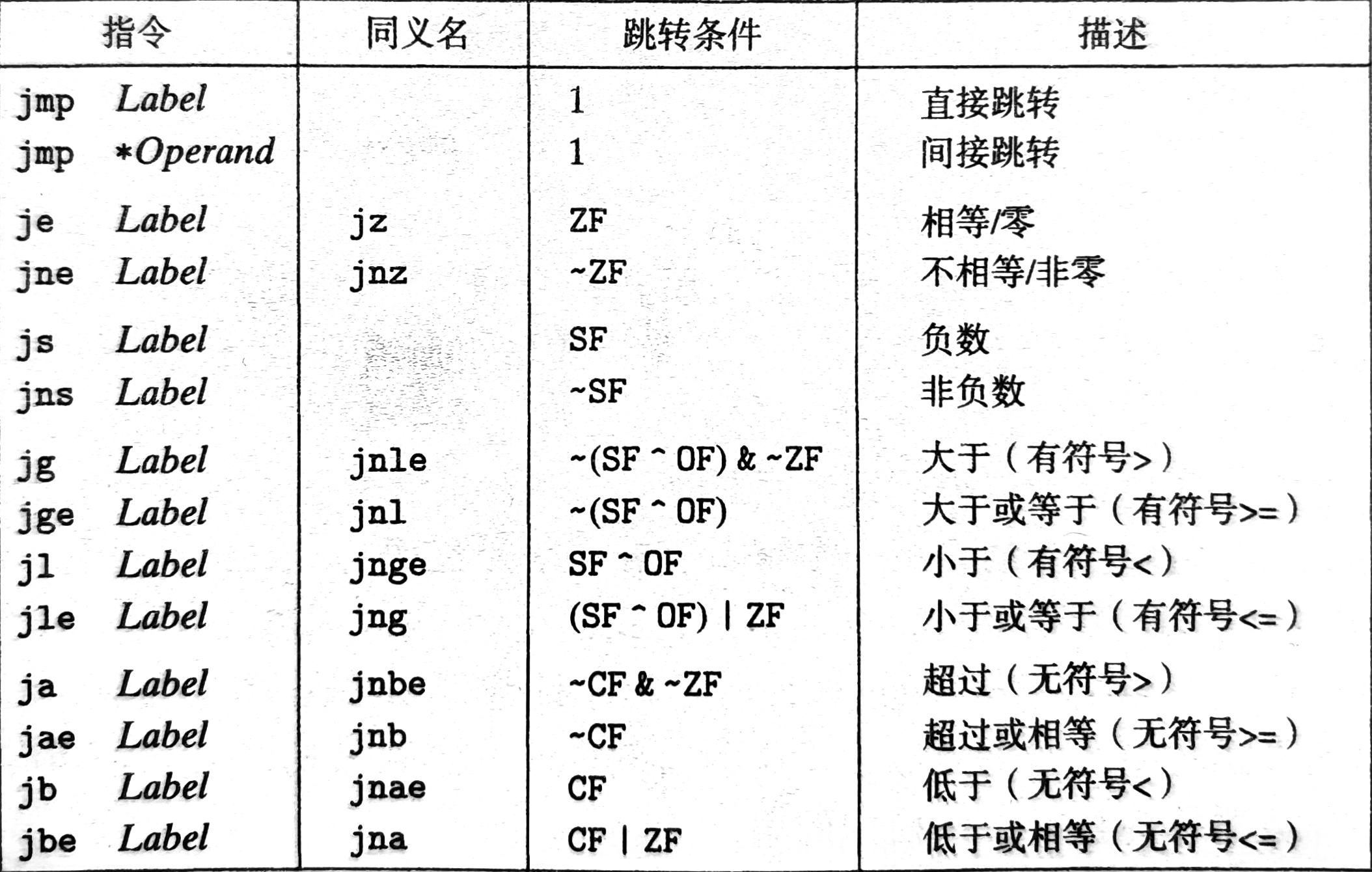
编码方式
最常用都是PC相对的 (PC-relative) 。也就是,它们会将目标指令的地址与紧跟在跳转指令后面那条指令的地址之间的差作为编码。这些地址偏移量可以编 码为1、2或4个字节,第二种编码方法是给出“绝对”地址,用4个字节直接指定目标 汇编器和链接器会选择适当的跳转目的编码。
例如源汇编代码 (x86-64,AT&T) 是:
movq %rdi, %rax
jmp .L3
.L2: sarq %rax
.L3: testq %rax, %rax
jg .L2
rep; ret下面是链接后的程序反汇编版本:
4004d0: 48 89 f8 mov %rdi,%rax
4004d3: eb 03 jmp 4004d8 <loop+0x8>
4004d5: 48 d1 f8 sar %rax
4004d8: 48 85 c0 test %rax,%rax
4004db: 7f f8 jg 4004d5 <loop+0x5>
4004dd: f3 c3 repz retq反汇编器产生的注释中,第2行中跳转指令的跳转目标指明为0xB,第5行中跳转指令的跳转目标是0x5(反汇编器以十六进制格式给出所有的数字)。不过,观察指令的字节编码,会看到第一条跳转指令的目标偏移量(在第二个字节中)为0x03。把它加上0x5,也就是下一条指令的地址,就得到跳转目标地址0x8,也就是第4行指令的地址。类似地,第二个跳转指令的目标偏移量用单字节、补码表示编码为0xf8(十进制-8)。将这个数加上0xD(十进制13),即第6行指令的地址,我们得到0x5,即第3行指令的地址。**当执行PC相对寻址时,程序计数器的值是跳转指令之后的那条指令的地址,而不是跳转指令本身的地址。**这种惯例可以追溯到早期的实现,当时的处理器会在更新程序计数器之后作为执行一条指令的第一步。
循环
主要有三种:
-
LOOP, 相当于do { // 循环体代码 CX--; } while (CX != 0);
-
LOOPZ, 相当于do { // 循环体代码 CX--; } while (CX != 0 && ZF == 1);
-
LOOPNZ, 相当于do { // 循环体代码 CX--; } while (CX != 0 && ZF == 0);
延迟
通过调整运行的语句来延迟特定的时间,和CPU的频率有关
短延迟
对于如下程序
mov cx, N ; 消耗 4 时钟周期, 这里 N 是字面量, 但是取值还未确定
tag:
nop ; 消耗 3 时钟周期
nop ; 消耗 3 时钟周期
loop tag ; 消耗 17 个时钟周期, 退出循环时仅 5 个时钟周期总延迟时间的计算公式为: $C = 4 + N \times 23 - 12$
假设需要延迟 1000 个时钟周期, 可以通过以下步骤计算循环次数 ( N ):
$1000 = 4 + N \times 23 - 12$
解方程得到:
$N = \frac{1000 - 4 + 12}{23} \approx 43.65$
因此, 设置 ( N = 44 ) 即可实现大约 1000 个时钟周期的延迟
长延迟
考虑如下程序
.STARTUP
mov ah,02
mov dl,'S'
int 021h
mov bx, 30000 ;4
back2:
mov cx, 30000 ;4
back1:
nop ;3
loop back1
dec bx
jnz back2
mov ah,02
mov dl,'F'
int 021h
EXIT延迟计算公式为:
$C_{T}=C_{0}+N(C_{BK}){-12}$
先计算内循环:
$\begin{flalign*}
&C_T = C_0 + N(C_{_{BK}}) - 12 \
&C_T = 4 + 3000(20) - 12 \
&C_T = 599992
\end{flalign*}$
然后计算外循环:
$\begin{flalign*}
&C_T = C_0 + N(C_{BK}) - 12 \
&C_T = 4 + 30000(59992 + 2 + 16) - 12 \
&C_T = 1.8 \times 10^{10} \text{ Clock cycles}
\end{flalign*}$
实际上程序只花了15s来运行, 计算出来的时钟频率是1200MHz, 是目标机器的时钟频率(300MHz)的4倍,原因是现代处理器使用 指令并行 技术
打印数字
基于栈的实现:
.MODEL medium
.STACK
.DATA
ten db 10
.CODE
.STARTUP
mov ax, 12345
call Print
.EXIT
Print:
push bx ; 函数调用, 储存原来寄存器的值, 固定操作
push cx
push dx
mov cx, 5 ; 初始化循环计数器为 5
mov bx, 10000
again:
mov dx, 0h ; 除法前清空 dx
div bx ; dx:ax /= bx
or al, 030h ; 数字转 ASCII
push dx ; 保存余数
mov dl, al ; 传参给 21h 中断
mov ah, 02h ; 输出字符模式
int 021h
mov dx, 0h ; 除法前清空 dx
mov ax, bx ; bx /= 10
div ten
mov bx, ax
pop ax
loop again ; cx 自动减 1, 不为 0 则跳转
pop dx ; 函数调用结束, 恢复原来寄存器的值, 固定操作
pop cx
pop bx
ret
ENDLecture 5: 汇编语言 (Ⅳ)
打印负数
负数打印的原理
- 符号判断:程序首先检查数值符号位,判断是否为负数。
- 负号输出:若为负数,则先输出负号
-。 - 取绝对值:对负数取反加一,转换为正数进行打印处理。
打印负数的汇编代码实现
.MODEL medium
.STACK
.DATA
ten word 10
.CODE
.STARTUP
mov ax, 32768 ; 将要打印的数值 (示例为 -32768 的补码表示) 放入 AX 寄存器
call Print ; 调用 Print 子程序进行打印
.EXIT
; Print 子程序:负责将 AX 寄存器中的数值以十进制形式打印到屏幕
Print:
push bx ; 保护寄存器 BX, CX, DX 的值
push cx
push dx
mov cx, 5 ; 设置循环次数为 5,用于打印五位十进制数
mov bx, 10000 ; BX 寄存器设置为 10000,用于取出万位数字
test ax, 8000h ; 检测 AX 寄存器的最高位 (符号位)
jz Positive ; 如果符号位为 0 (正数),跳转到 Positive 标签
; 如果是负数,执行以下代码:
push ax ; 暂时保存 AX 的值
mov ah, 02h ; 设置 DOS 功能号为 02h (显示字符)
mov dl, '-' ; 将 '-' 字符的 ASCII 码放入 DL 寄存器
int 021h ; 调用 DOS 中断 21h,显示 '-' 字符
pop ax ; 恢复 AX 寄存器的值 (负数)
not ax ; AX 取反 (按位非)
add ax, 1 ; AX 加 1,得到负数的绝对值 (补码转原码)
jmp Positive ; 跳转到 Positive 标签,打印绝对值
; Positive 标签:处理正数和负数的绝对值打印
Positive:
mov dx, 0h ; DX 寄存器清零,为除法运算做准备
div bx ; AX 除以 BX (10000),商在 AX,余数在 DX。这里用于取出万位数字,但第一次循环BX是10000,实际是取最高位
or al, 030h ; 将 AL 寄存器的值与 30h (字符 '0' 的 ASCII 码) 进行按位或运算,将数字转换为 ASCII 字符
push dx ; 余数 DX 入栈,暂存个位/十位/百位/千位数字,后续会依次出栈打印
mov dl, al ; 将个位数字的 ASCII 码放入 DL 寄存器
mov ah, 02h ; 设置 DOS 功能号为 02h (显示字符)
int 021h ; 调用 DOS 中断 21h,显示当前数字字符
mov dx, 0h ; DX 寄存器清零,为下一次除法运算做准备
mov ax, bx ; 将 BX 的值 (当前的除数,初始为 10000) 复制到 AX
div ten ; AX 除以 ten (10),结果商在 AX,余数在 DX。用于将除数降一位 (10000 -> 1000 -> 100 -> 10 -> 1)
mov bx, ax ; 将新的除数 (缩小 10 倍) 更新到 BX 寄存器
pop ax ; 从栈中弹出之前暂存的余数到 AX,为下一次循环做准备 (实际上这里pop出来的是上一次div的余数,但是后面又被mov dx, 0h覆盖了,应该pop到dx才对,这里代码有误)
loop Positive ; 循环 CX 次,打印剩余的数字
pop dx ; 恢复寄存器 DX, CX, BX 的值
pop cx
pop bx
ret ; 子程序返回
END字符串
字符串的定义
字符串 (String) 是一组用于描述文本的 ASCII(美国信息交换标准代码) 字符序列。在汇编语言中,字符串通常以不同的方式进行定义和存储,常见的表示方法包括:
- NULL 结尾字符串:以 NULL 字节 (数值为 0 的字节) 作为字符串的结束符。例如
"Charles Markham /0"。这种方式简单直观,但需要遍历字符串才能确定其长度。 - 长度前缀字符串:字符串的第一个字节用于存储字符串的长度,后续字节存储字符串的内容。例如
"/15 Charles Markham",其中/15表示字符串长度为 15。这种方式可以快速获取字符串长度,但限制了字符串的最大长度 (因为长度信息通常只用一个字节存储) 。
字符串的存储方式
- 连续内存空间:字符串的字符在内存中是连续存储的,以便于程序进行访问和操作。
- ASCII 编码:每个字符都使用 ASCII 编码表示,占用一个字节的存储空间。
字符串操作
LEA 命令:加载有效地址
LEA (Load Effective Address) 命令用于将有效地址加载到指定的寄存器中,常用于获取变量或内存地址。
-
功能:将源操作数 (通常是内存地址) 的有效地址传送给目的操作数 (寄存器) 。
-
示例:
msg1 db "Hello, world.$" ; 定义字符串 msg1 lea SI, msg1 ; 将 msg1 的有效地址加载到 SI 寄存器
说明:上述代码中,
lea SI, msg1将msg1字符串在内存中的起始地址加载到 SI(源变址寄存器) 寄存器中。此时,SI 寄存器就指向了字符串msg1的首地址。
MOVSB 命令:移动字符串字节
MOVSB (Move String Byte) 命令用于将数据从源地址复制到目标地址,以字节为单位进行操作。
-
功能:将 DS:SI 寄存器指向的内存地址中的一个字节数据复制到 ES:DI 寄存器指向的内存地址。
-
寄存器影响:执行
MOVSB指令后,SI(源变址寄存器) 和 DI(目的变址寄存器) 寄存器的值会自动递增或递减,递增或递减的方向由 DF(方向标志位) 决定。- 当 DF = 0 时,SI 和 DI 递增 (正向复制) 。
- 当 DF = 1 时,SI 和 DI 递减 (反向复制) 。
-
应用场景:常用于字符串复制、内存块移动等操作。
-
示例:
msg1 db "Hello$" ; 源字符串 msg1 msg2 db " $" ; 目标字符串 msg2,预留空间 lea SI, msg1 ; SI 指向源字符串 msg1 的首地址 lea DI, msg2 ; DI 指向目标字符串 msg2 的首地址 mov cx, 5 ; 设置循环次数为 5,表示要复制的字节个数 cld ; 清除方向标志位 DF,设置正向复制 (SI, DI 递增) rep movsb ; 重复执行 MOVSB 指令 CX 次,完成字符串复制
说明:这段代码使用
MOVSB命令将msg1的前 5 个字节复制到msg2中。rep(repeat) 前缀使得MOVSB指令重复执行CX次,cld(clear direction flag) 指令清除方向标志位 DF,确保复制过程地址递增。
CMPSB 命令:比较字符串字节
CMPSB (Compare String Byte) 命令用于比较两个字符串中的字节。
-
功能:比较 DS:SI 寄存器指向的字节和 ES:DI 寄存器指向的字节。
-
标志位影响:根据比较结果设置 标志寄存器 中的标志位,例如 ZF(零标志位)、SF(符号标志位) 等。
- 若两个字节相等,则 ZF = 1。
- 若不相等,则 ZF = 0。
-
寄存器影响:执行
CMPSB指令后,SI 和 DI 寄存器的值也会根据 DF 的值自动递增或递减。 -
应用场景:常用于字符串比较、查找等操作。
-
示例:
msg1 db "Hello$" ; 第一个字符串 msg1 msg2 db "Hello$" ; 第二个字符串 msg2 lea SI, msg1 ; SI 指向字符串 msg1 的首地址 lea DI, msg2 ; DI 指向字符串 msg2 的首地址 mov cx, 5 ; 设置循环次数为 5,表示要比较的字节个数 cld ; 清除方向标志位 DF,设置正向比较 (SI, DI 递增) rep cmpsb ; 重复执行 CMPSB 指令 CX 次,比较字符串 jz equal ; 如果 ZF = 1 (比较结果相等),跳转到 equal 标签 jmp not_equal ; 如果 ZF = 0 (比较结果不相等),跳转到 not_equal 标签 equal: ; 字符串相等时执行的代码 not_equal: ; 字符串不相等时执行的代码
说明:这段代码使用
CMPSB命令比较msg1和msg2的前 5 个字节。rep cmpsb会重复比较CX次,并根据比较结果设置标志位。jz(jump if zero) 指令检查 ZF 标志位,判断比较结果是否相等。
Note
REP(Repeat) 修饰符可以放在多种字符串指令 (如 MOVSB, CMPSB, STOSB, LODSB 等) 的前面,用于重复执行该指令 CX 次.REP 代表 重复字符串前缀,它可以简化循环控制,提高字符串操作的效率。
CISC 与 RISC 指令集对比
MOVSB 和 CMPSB 等字符串操作指令是 CISC(复杂指令集计算机) 架构的特点之一。为了更好理解 CISC 的特点,以下进行 CISC 和 RISC(精简指令集计算机) 的对比:
-
CISC (复杂指令集计算机):
-
定义:复杂指令集计算机 (Complex Instruction Set Computer) 是一种微处理器指令集架构,其特点是指令数量众多且功能复杂,每条指令可以执行多个低级操作,例如从存储器读取、存储、计算等,都集成在一条指令中。
-
特点:
- 指令数目多而复杂。
- 每条指令的长度不固定。
- 计算机需要进行指令解码和判读,增加了硬件设计的复杂性和性能开销。
-
代表架构:x86、AMD Opteron 等。维基百科对 CISC 的描述如下:
复杂指令集计算机 (英语: Complex Instruction Set Computer;缩写: CISC) 是一种微处理器指令集架构, 每个指令可执行若干低端操作, 诸如从存储器读取、存储、和计算操作, 全部集于单一指令之中与之相对的是精简指令集
复杂指令集的特点是指令数目多而复杂, 每条指令字长并不相等, 电脑必须加以判读, 并为此付出了性能的代价
属于复杂指令集的处理器有 CDC 6600、System/360、VAX、PDP-11、Motorola 68000家族、x86、AMD Opteron 等
-
-
RISC (精简指令集计算机):
- 定义:精简指令集计算机 (Reduced Instruction Set Computer) 架构,其特点是指令集精简,指令数量较少,每条指令只完成单一、基本的操作。复杂的操作通常由多条简单指令组合完成。
- 特点:
- 指令数量少且简单。
- 指令长度固定。
- 硬件设计相对简单,指令执行效率高。
- 代表架构:ARM、MIPS 等。
浮点数
浮点数的概念
浮点数 (Floating-point Number) 是一种用科学计数法表示实数的方式,用于在计算机中存储和处理小数或非常大/小的数值。浮点数表示方法通常包含三个关键组成部分:
- 符号位 (Sign):用于表示数值的正负,通常 0 表示正数,1 表示负数。
- 指数位 (Exponent):用于表示数值的数量级或小数点的位置。指数位决定了数值的大小范围。
- 尾数位 (Mantissa 或 Fraction):用于表示数值的精度,即小数点后的有效数字。尾数位决定了数值的精确程度。

浮点数的通用表示形式
浮点数的通用数学表示形式为:
$\text{Value} = (-1)^{\text{Sign}} \times \text{Mantissa} \times 2^{\text{Exponent}}$
规格化浮点数
规格化浮点数 (Normalized Floating-point Number) 是 IEEE 754 标准 中最常用的一种浮点数表示形式。
- 特点:尾数位 (Mantissa) 的最高位隐含为 1,即尾数的整数部分总是 1。由于最高位固定为 1,因此在存储时可以省略这一位,从而节省一个比特的存储空间,提高精度。
规格化浮点数的表示方法
- 尾数 (Mantissa):只存储小数部分,整数部分的
1是隐含的。 - 指数 (Exponent):存储经过偏移量 (Bias) 调整后的指数值。对于单精度浮点数,偏移量 Bias 通常为 127;对于双精度浮点数,偏移量 Bias 通常为 1023。指数位不能全为 0 或全为 1 (这两种情况有特殊用途,见下文) 。
- 单精度浮点数指数范围:1 到 254 (实际指数范围为 -126 到 127)
- 双精度浮点数指数范围:1 到 2046 (实际指数范围为 -1022 到 1023)
规格化浮点数的计算公式
$\text{Value} = (-1)^{\text{Sign}} \times 1.\text{Mantissa} \times 2^{\text{Exponent} - \text{Bias}}$
规格化浮点数示例
单精度浮点数示例:
假设有一个单精度浮点数,其二进制表示为:
- 符号位 (Sign):
0(表示正数) - 指数位 (Exponent):
10000001(二进制) = 129 (十进制)。偏移量 Bias = 127,实际指数 = 129 - 127 = 2。 - 尾数位 (Mantissa):
10100000000000000000000(二进制)。隐含前导1,实际尾数为1.101(二进制)。
计算数值:
$\text{Value} = 1.101_2 \times 2^{2} = 110.1_2 = 6.5_{10}$
非规格化浮点数
非规格化浮点数 (Denormalized Floating-point Number) 用于表示非常接近于零的数值,其特点是尾数部分的最高位不隐含为 1,而是显式表示。
- 应用场景:用于解决规格化浮点数无法表示零值以及接近零的小数值的问题,扩展了浮点数可以表示的数值范围,使其更接近零。
非规格化浮点数的表示方法
- 尾数 (Mantissa):没有隐含的前导 1,实际存储的就是完整的小数部分。
- 指数 (Exponent):指数位全为 0。
- 单精度浮点数指数位:
00000000(二进制) = 0 (十进制) - 双精度浮点数指数位:
00000000000(二进制) = 0 (十进制)
- 单精度浮点数指数位:
非规格化浮点数的计算公式
$\text{Value} = (-1)^{\text{Sign}} \times 0.\text{Mantissa} \times 2^{1 - \text{Bias}}$
Note
非规格化浮点数的指数部分固定为 1 - Bias,而不是 0 - Bias,这是 IEEE 754 标准的规定,目的是为了平滑地过渡到规格化浮点数。
非规格化浮点数示例
单精度浮点数示例:
假设有一个单精度非规格化浮点数,其二进制表示为:
- 符号位 (Sign):
0(表示正数) - 指数位 (Exponent):
00000000(二进制) = 0 (十进制)。偏移量 Bias = 127,实际指数固定为1 - 127 = -126。 - 尾数位 (Mantissa):
00000000000000000000001(二进制)。没有隐含前导1,实际尾数为0.00000000000000000000001(二进制)。
计算数值:
$\text{Value} = 0.00000000000000000000001_2 \times 2^{-126} \approx 1.4 \times 10^{-45}$
浮点数的计算
浮点数加减运算的原则
浮点数加减运算 遵循 先对齐,再计算 的原则。
- 对齐:指的是对齐指数位。当两个浮点数进行加减运算时,如果它们的指数位 (Exponent) 不相同,需要先进行对阶操作,将它们的指数位对齐到相同的数量级。
- 对阶原则:通常将较小的指数对齐到较大的指数。
- 对阶方法:将较小指数的浮点数的尾数位右移,每右移一位,指数位加 1,直到两个浮点数的指数位相同。尾数右移会降低精度,因此对阶操作可能会导致精度损失。
浮点数加法运算示例
例如,计算 0.5 与 0.125 的和。
-
浮点数表示:
- 0.5 的浮点数表示:$(-1)^0 \times 1.0 \times 2^{-1}$
- 0.125 的浮点数表示:$(-1)^0 \times 1.0 \times 2^{-3}$
-
对阶:
- 比较指数位:0.5 的指数为 -1,0.125 的指数为 -3。0.5 的指数较大。
- 对齐指数位:将 0.125 的指数对齐到 -1,需要将指数增加 2 (从 -3 增加到 -1),尾数位右移 2 位。
- 对阶后的 0.125 表示:$(-1)^0 \times 0.01 \times 2^{-1}$ (尾数 1.0 右移两位变为 0.01)
-
尾数相加:
- 将对阶后的两个浮点数的尾数部分相加:$1.0 + 0.01 = 1.01$
-
结果规格化 (本例中已规格化):
- 最终结果的浮点数表示:$(-1)^0 \times 1.01 \times 2^{-1}$
-
结果转换为十进制:
- $(-1)^0 \times 1.01_2 \times 2^{-1} = 1.01_2 \times 2^{-1} = 0.101_2 = 0.625_{10}$ (此处计算有误,应为0.5 + 0.125 = 0.625,但示例中0.5+0.125=0.625的二进制表示应为0.101,而示例结果1.01 * 2^-1 = 1.01/2 = 0.505,计算过程需要修正)
修正后的计算结果:
- $1.01_2 \times 2^{-1} = 1.01_2 / 2 = 0.101_2 = 0.5_{10} + 0.125_{10} = 0.625_{10}$
- 二进制
0.101转换为十进制为1*2^-1 + 0*2^-2 + 1*2^-3 = 0.5 + 0 + 0.125 = 0.625。
因此,0.5 + 0.125 = 0.625 的浮点数表示为 $(-1)^0 \times 1.01 \times 2^{-1}$。
8087 数学协处理器
处理器都有 CP 了 (╯‵□′)╯︵┻━┻
8087 协处理器的概述
8087 协处理器 (8087 Coprocessor) 是一种数学协处理器,也常被称为 浮点处理器 (Floating-Point Processor) 或 数字数据处理器 (Numeric Data Processor, NDP)。
- 作用:8087 不是一个独立的 CPU(中央处理器),而是作为 CPU 的辅助单元,专门用于加速浮点数运算。它与 Intel 8086、8088 等 CPU 协同工作,扩展了 CPU 的数值计算能力,尤其是在浮点数运算方面。
- 历史背景:在早期计算机系统中,CPU 的浮点运算能力相对较弱,为了提高浮点运算性能,出现了数学协处理器。8087 是 Intel 公司为 8086/8088 处理器设计的协处理器,显著提升了当时计算机的科学计算能力。
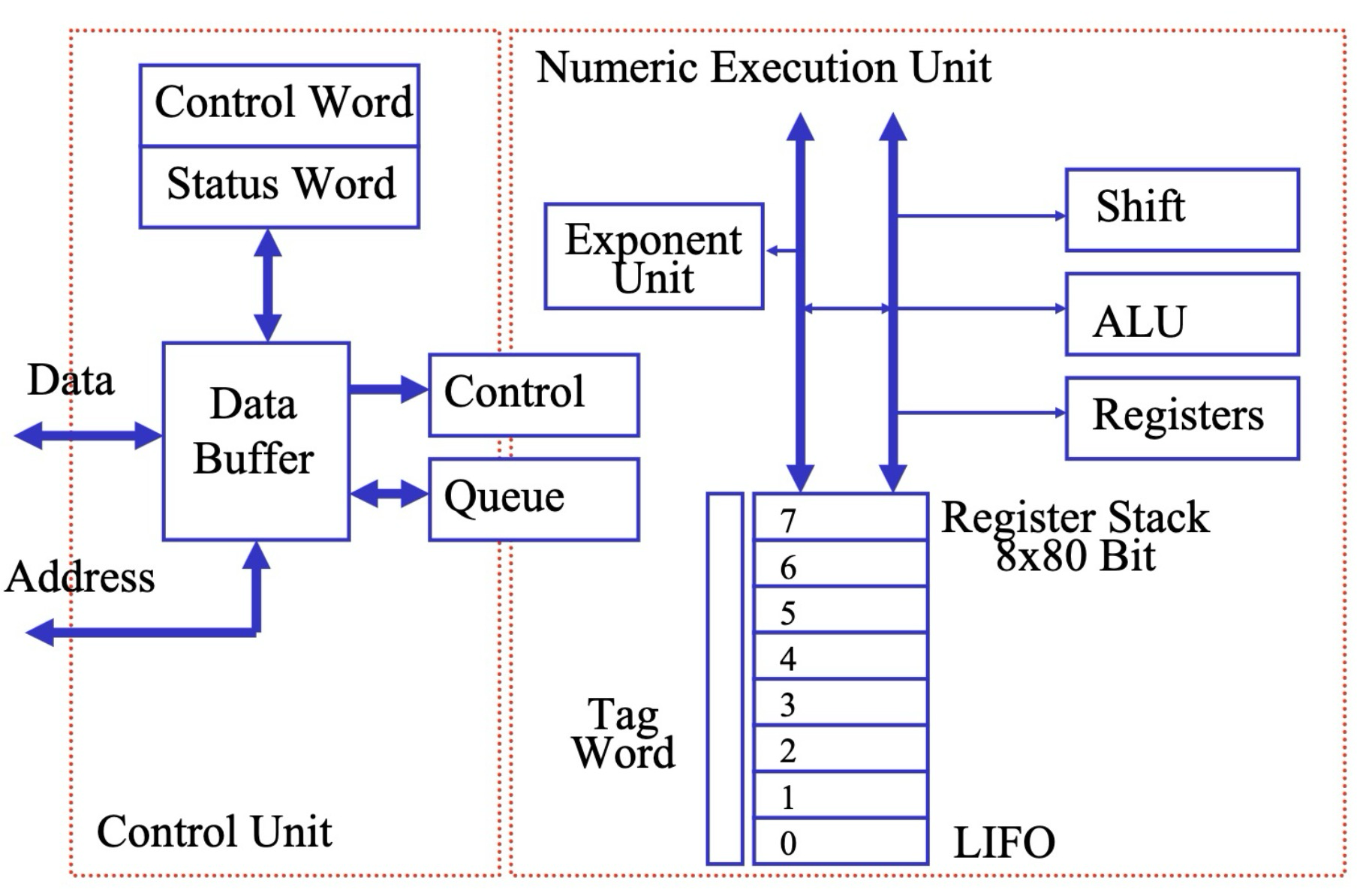
8087 的状态字组
状态字组 (Status Word) 是 8087 协处理器中的一个寄存器,用于记录浮点运算的状态和异常信息。

- 作用:状态字组中的各个标志位反映了最近一次浮点运算的结果状态,例如是否发生溢出、下溢、除零错误、精度丢失等异常情况,以及运算结果的符号、舍入模式等信息。
- 程序应用:程序员可以通过读取状态字组,检查浮点运算是否发生异常,并根据状态信息进行相应的错误处理或流程控制。
8087 的控制字组
控制字组 (Control Word) 是 8087 协处理器中的另一个寄存器,用于控制浮点运算的精度、舍入模式、异常处理方式等。

- 作用:通过设置控制字组中的各个控制位,可以配置 8087 的运算行为,例如:
- 精度控制:设置浮点运算的精度 (单精度、双精度、扩展精度)。
- 舍入控制:设置浮点数舍入模式 (例如,舍入到最近偶数、向上舍入、向下舍入、截断舍入)。
- 异常屏蔽:屏蔽或使能各种浮点异常 (例如,溢出异常、除零异常、无效操作异常)。
- 程序应用:程序员可以根据具体的应用需求,配置控制字组,以满足不同的精度、性能和可靠性要求。
8087 的栈结构
栈 (Stack) 是 8087 协处理器内部用于存储浮点数据的存储区域。
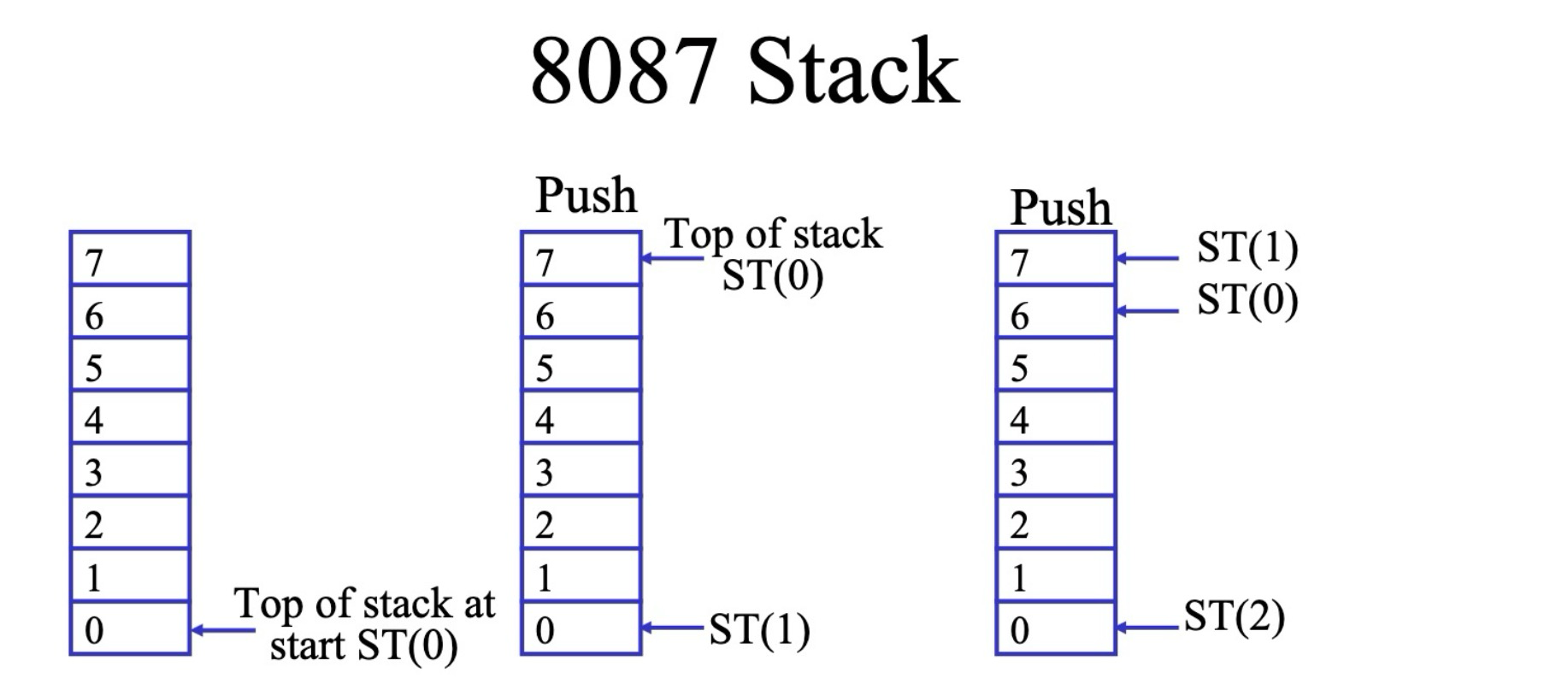
- 特点:
- 8 层栈结构:8087 栈共有 8 个 寄存器 位置,每个寄存器可以存储一个 10 字节 的扩展精度浮点数。
- 栈顶指针:使用 栈顶指针 (隐式) 来管理栈的push和pop操作。
- 循环栈:当新的数据压入栈时,栈顶指针会移动,栈底的数据会被覆盖,类似于循环移位操作。
- 寄存器命名:在 MASM 汇编 代码中,使用
ST(0)表示栈顶寄存器,ST(1)~ST(7)表示栈中其他寄存器,ST(1)是栈顶的下一个寄存器,以此类推。
8087 常用指令
8087 提供了丰富的指令集,用于执行各种浮点运算和数据操作。以下列举一些常用的 8087 指令:
FADD S1/D, S2(浮点加法):将两个浮点数S1和S2相加,结果存储到D中 (S1 = D)。- 如果没有指定
S1和S2,则默认操作为ST(0) += ST(1),即将栈顶元素ST(0)和次栈顶元素ST(1)相加,结果覆盖ST(0),并将栈顶指针减 1。
- 如果没有指定
FSUB S1/D, S2(浮点减法):将S1减去S2,结果存储到D中 (S1 -= S2)。FSUBR S1/D, S2(反向浮点减法):将S2减去S1,结果存储到D中 (S1 = S2 - S1)。FMUL S1/D, S2(浮点乘法):将S1和S2相乘。FDIV S1/D, S2(浮点除法):将S1除以S2。FMULP(浮点乘法并Pop):将栈顶元素ST(0)和次栈顶元素ST(1)相乘,结果存储到ST(1),并将栈顶元素弹出 (栈顶指针减 1)。FIMUL(整数浮点乘法):将栈顶元素ST(0)与一个整数相乘。FDIVR(反向浮点除法):将S2除以S1。FDIVP(浮点除法并Pop):将次栈顶元素ST(1)除以栈顶元素ST(0),结果存储到ST(1),并将栈顶元素弹出。FIDIV(整数浮点除法):将栈顶元素ST(0)除以一个整数。
Lecture 6: Assembly Language (V)
浮点数计算 —— 毕达哥拉斯问题
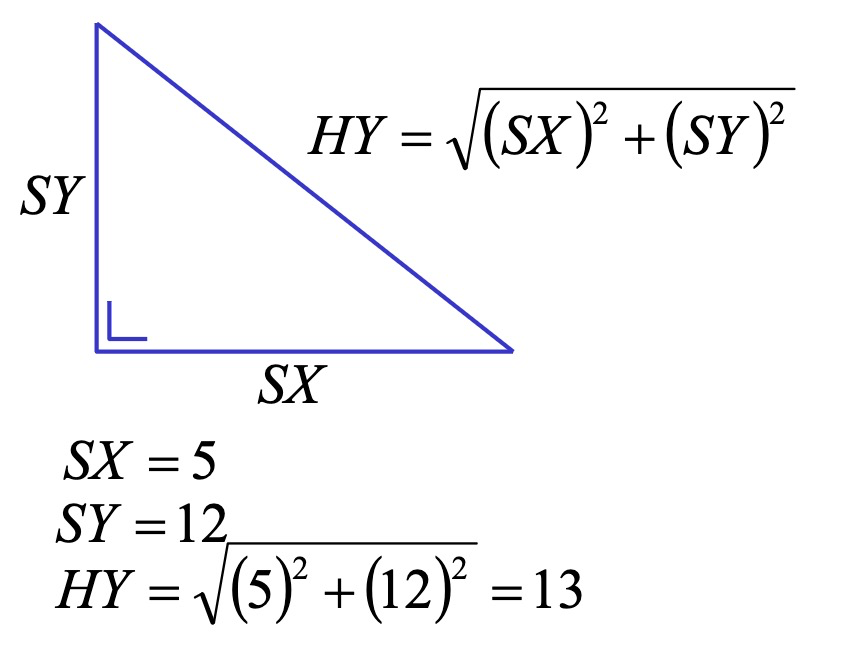
使用 FP 处理器 (8087 ) 执行上述计算
.8087 ; 告诉 MASM 协处理器存在
.MODEL medium
.STACK
.DATA
SX dd 5.0 ; 定义短实数 (4 字节 ), 初始值为 5.0
SY dd 12.0 ; 定义短实数 (4 字节 ), 初始值为 12.0
HY dd 0.0 ; 定义短实数 (4 字节 ), 用于存储结果
cntrl dw 03FFh ; 定义控制字, 用于设置 8087 协处理器的状态
stat dw 0 ; 定义状态字, 用于存储 FPU 的状态
.CODE
.STARTUP
FINIT ; 初始化 FPU, 将其设置为默认状态
FLDCW cntrl ; 加载控制字, 设置舍入模式为偶数, 并屏蔽中断
FLD SX ; 将 SX 压入 FPU 栈
FMUL ST, ST(0) ; 将栈顶元素与自身相乘, 结果存储在栈顶
FLD SY ; 将 SY 压入 FPU 栈
FMUL ST, ST(0) ; 将栈顶元素与自身相乘, 结果存储在栈顶
FADD ; 将栈顶的两个数相加
FSQRT ; 计算栈顶元素的平方根
FSTSW stat ; 将 FPU 的状态字加载到 [stat]
mov ax, stat ; 将 [stat] 复制到 AX
and al, 0BFh ; 检查所有 6 个状态位
jnz pass ; 如果有任何位被设置, 则跳转到 pass
FSTP HY ; 将栈顶的结果存储到 HY
jmp print ; 跳转到打印函数
print:
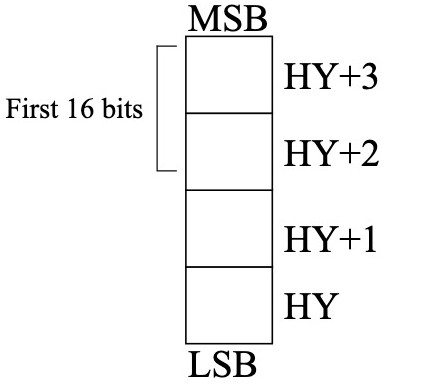
mov bx, OFFSET HY ; 将 HY 的地址加载到 BX 寄存器
mov ax, [bx+2] ; 将 HY+2 的值加载到 AX 寄存器
mov cx, 16 ; 设置循环次数为 16
call print_num
mov ax, [bx] ; 将 HY 的值加载到 AX 寄存器
mov cx, 16
call print_num
jmp pass
print_num:
push bx ; 存储 BX 寄存器
rol ax, 1 ; 将 AX 寄存器左移一位
jc set ; 如果 ZF=1 , 则 DL='1'
mov dl, '0' ; DL='0'
jmp over
set:
mov dl, '1'
over:
push ax ; 存储 AX 寄存器
mov ah, 02h
int 21h
pop ax ; 恢复 AX 寄存器
loop print_num
pop bx ; 恢复 BX 寄存器
ret
pass:
nop
; 程序结束
mov ah, 4Ch ; 设置 AH 为 4Ch (DOS 功能调用: 程序退出 )
int 21h
ENDHY在内存中的排列:
汇编的内容终于结束了
(≧▽≦)/
好的,这是根据您的规范重构后的关于半导体的笔记内容:
Lecture 7: 半导体
能级
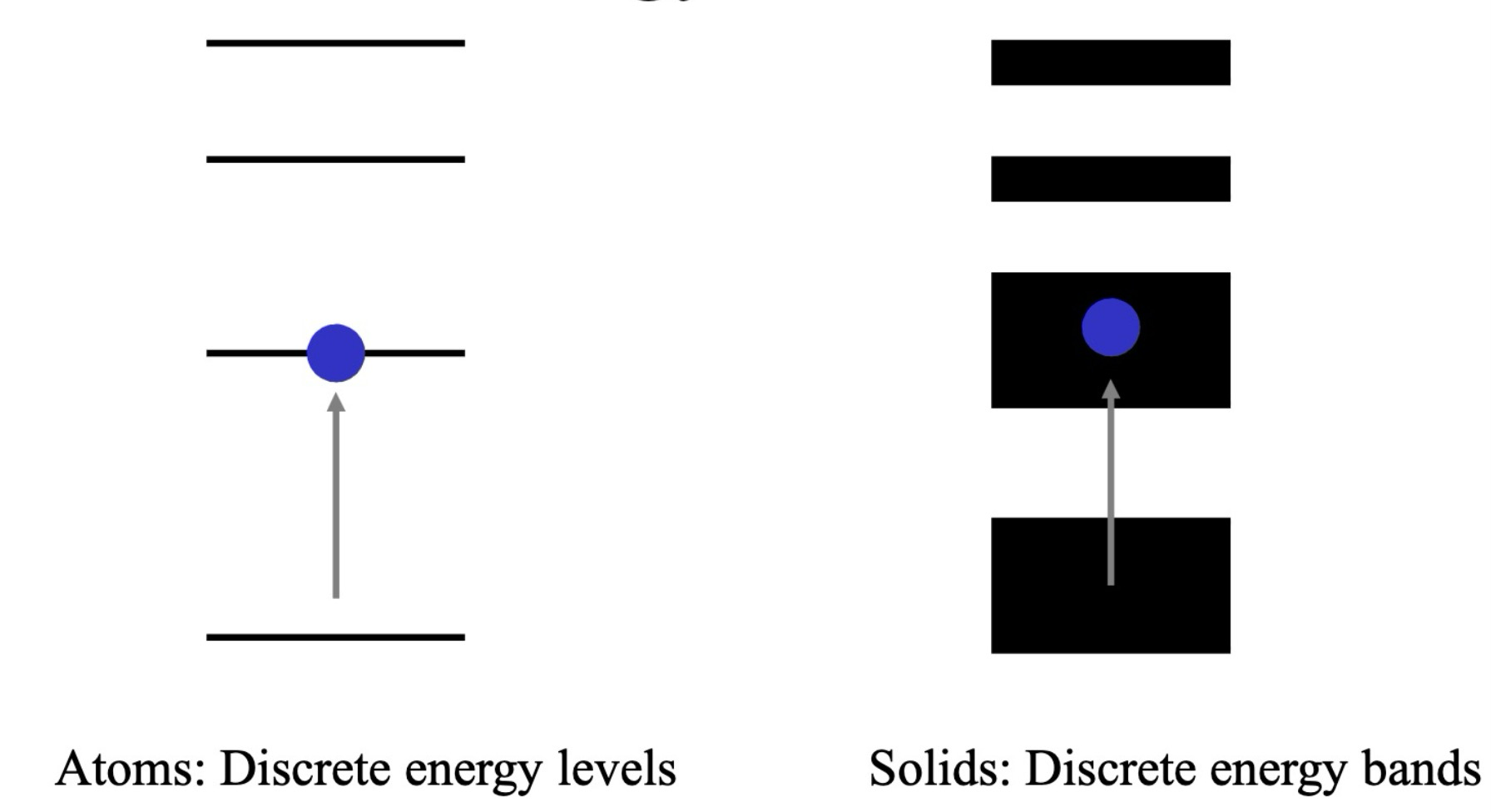
原子能级与固体能带的区别
原子和固体的能级结构存在显著差异,理解这些差异有助于认识半导体的特性。
-
原子能级:
- 离散能级:在原子 (Atom) 中,电子的能量是量子化的,只能占据特定的、离散的能级。这些能级对应于电子围绕原子核的不同轨道。
- 能级结构决定性质:原子的能级结构 (Energy Level Structure) 直接决定了原子的化学性质和物理性质,例如原子的光谱特性和化学反应活性。
- 能带的基础:原子能级结构是理解固体能带结构的基础,原子能级的变化和相互作用最终形成了固体中的能带。
-
固体能带:
- 连续能带:在固体 (Solid) 中,由于原子之间的相互作用,原子能级会扩展成连续的能量带,称为能带 (Energy Band)。电子可以在能带内连续地占据不同的能量状态。
- 电子自由移动:在固体中,电子不再局限于单个原子,而是在整个固体中相对自由地移动,因此其能量不再是离散的,而是形成能量区间。
- 能带性质取决于多因素:能带的性质 (Band Structure) 取决于多种因素,包括原子间的相互作用强度、晶体结构、化学成分等。
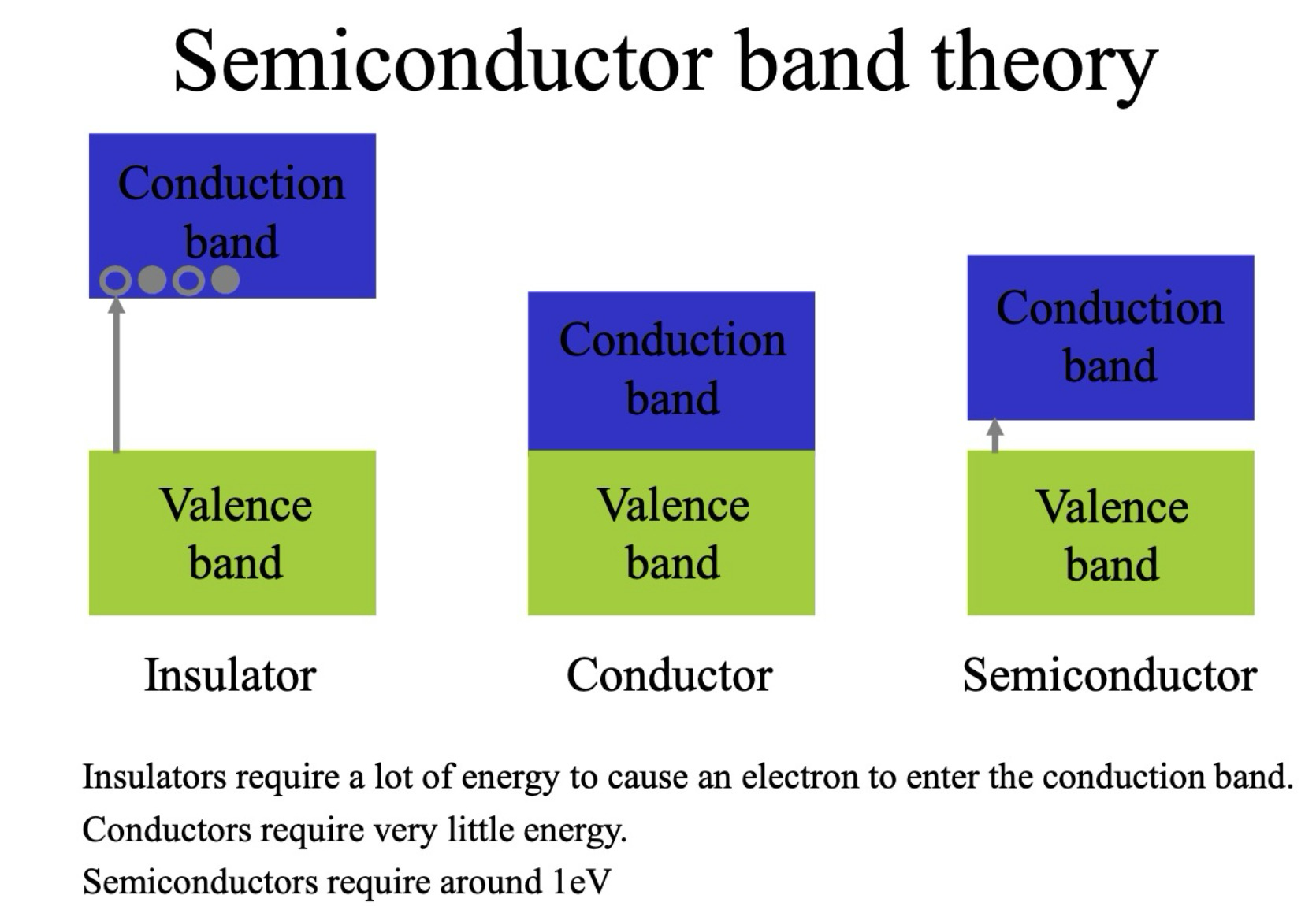
能带宽度与材料导电性
能带理论解释了不同材料的导电性差异,主要通过禁带宽度来区分绝缘体、导体和半导体。
-
绝缘体 (Insulator):
- 大禁带宽度:绝缘体 (Insulator) 具有非常宽的禁带,通常远大于 1eV。
- 难导电:需要非常大的能量才能将电子从价带 (Valence Band) 激发到导带 (Conduction Band),因此在通常条件下,绝缘体几乎不导电。
-
导体 (Conductor):
- 无禁带或禁带重叠:导体 (Conductor) 的导带和价带之间没有禁带,或者能带发生重叠。
- 易导电:电子可以自由地在能带间移动,极小的能量即可使电子进入导带,因此导体很容易导电。
-
半导体 (Semiconductor):
- 适中禁带宽度:半导体 (Semiconductor) 的禁带宽度适中,通常在 1eV 左右。
- 导电性可控:在常温下,半导体的导电性介于导体和绝缘体之间。通过掺杂、光照、温度等外部条件的变化,可以显著改变半导体的导电性,这是半导体材料最重要的特性。
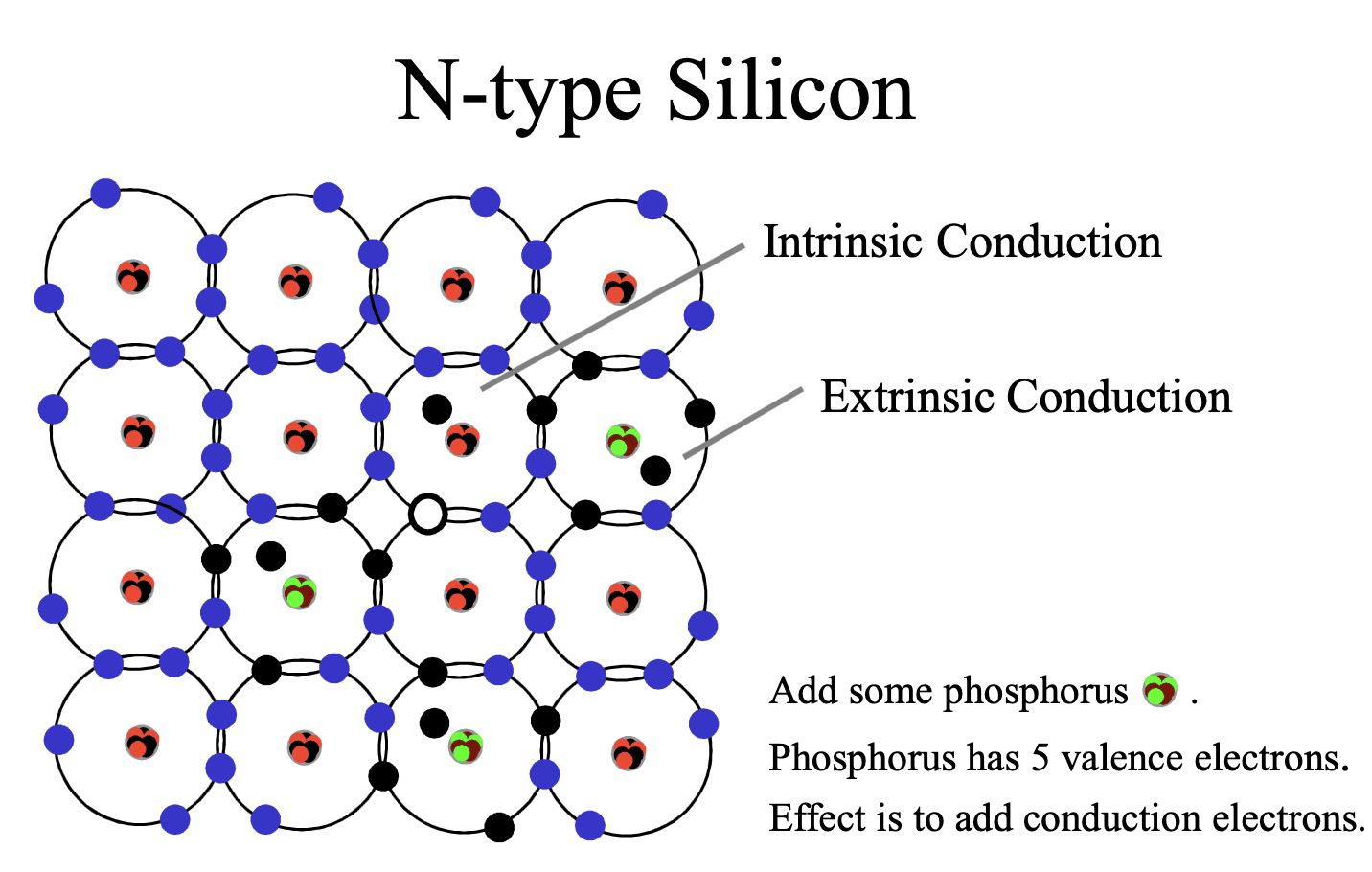
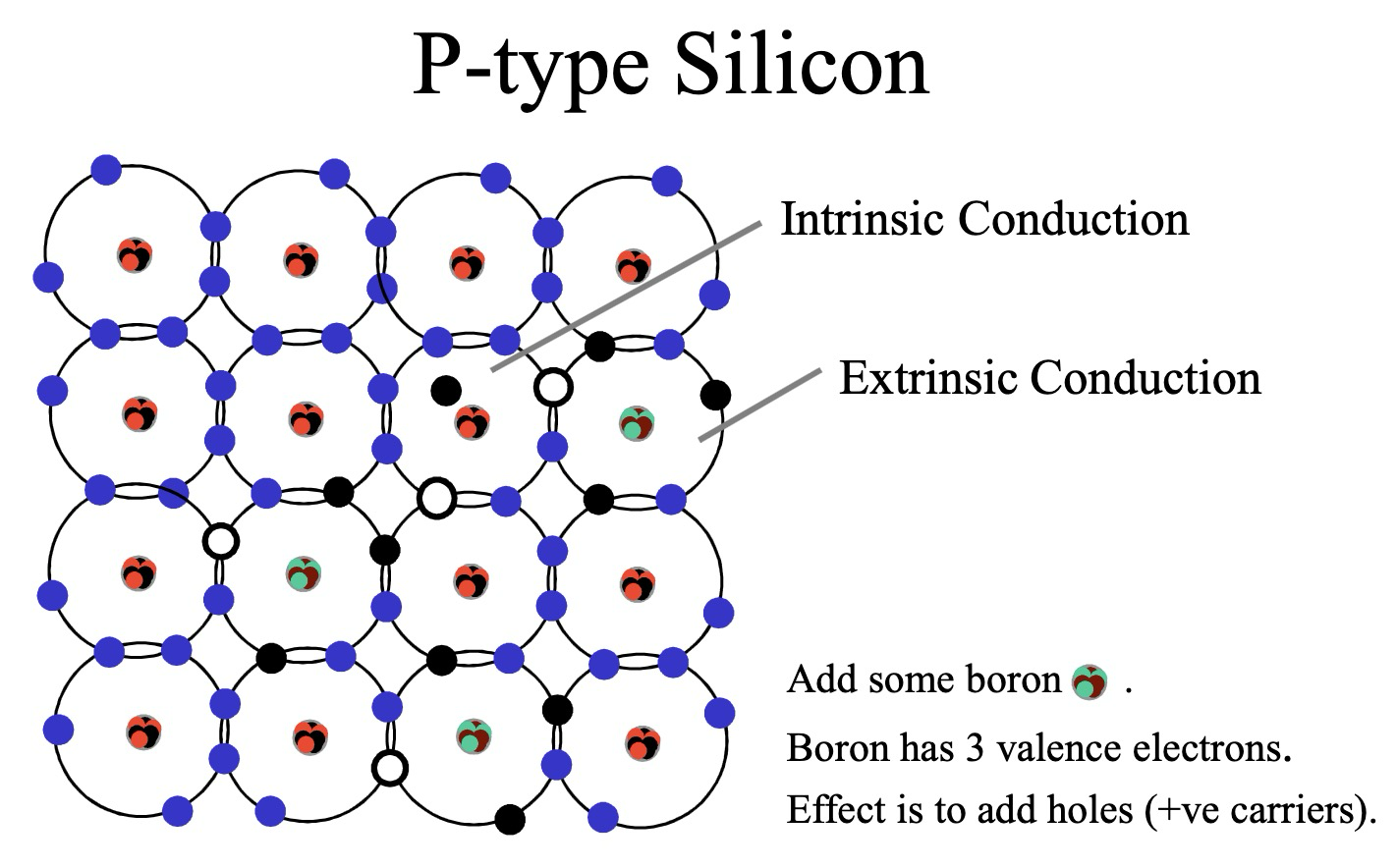
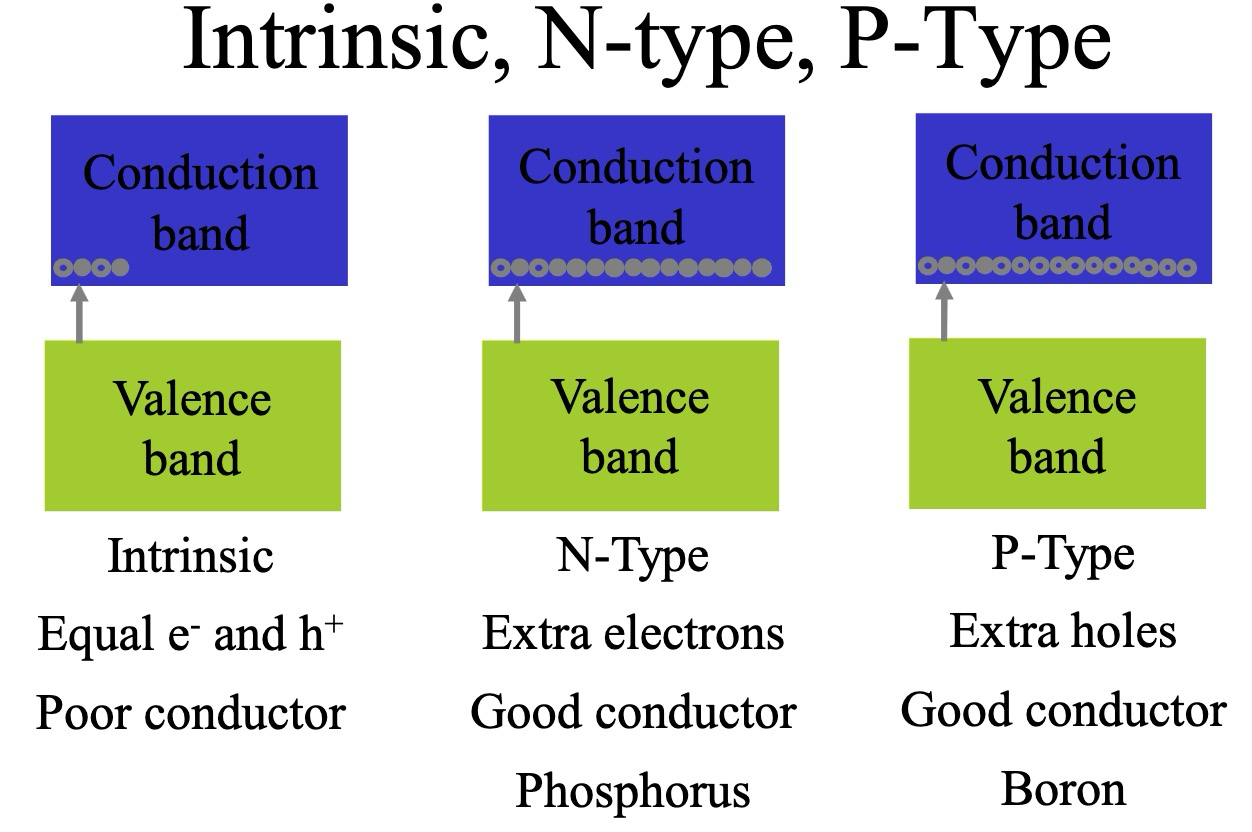
P型硅与N型硅
为了实现半导体的可控导电性,通常需要进行掺杂,形成 P 型半导体 和 N 型半导体。
P型硅 (P-type Silicon)
P 型硅 (P-type Silicon) 是通过掺杂 三价元素 (如硼 (Boron)) 到本征半导体 (Intrinsic Semiconductor) 硅中形成的。
- 掺杂硼:硼原子最外层有 3 个电子,取代硅晶格中的硅原子后,会缺少一个电子,形成一个空穴 (Hole)。
- 空穴导电:空穴可以被看作是带正电的载流子,在外电场作用下,空穴可以移动,形成电流。因此,P 型硅主要依靠空穴导电,空穴是 多数载流子,电子是 少数载流子。
N型硅 (N-type Silicon)
N 型硅 (N-type Silicon) 是通过掺杂 五价元素 (如磷 (Phosphorus)) 到本征半导体硅中形成的。
- 掺杂磷:磷原子最外层有 5 个电子,取代硅晶格中的硅原子后,会多出一个电子。这个多余的电子很容易挣脱原子核的束缚,成为自由电子 (Free Electron)。
- 电子导电:N 型硅中自由电子浓度大大增加,在外电场作用下,自由电子定向移动形成电流。因此,N 型硅主要依靠电子导电,电子是 多数载流子,空穴是 少数载流子。
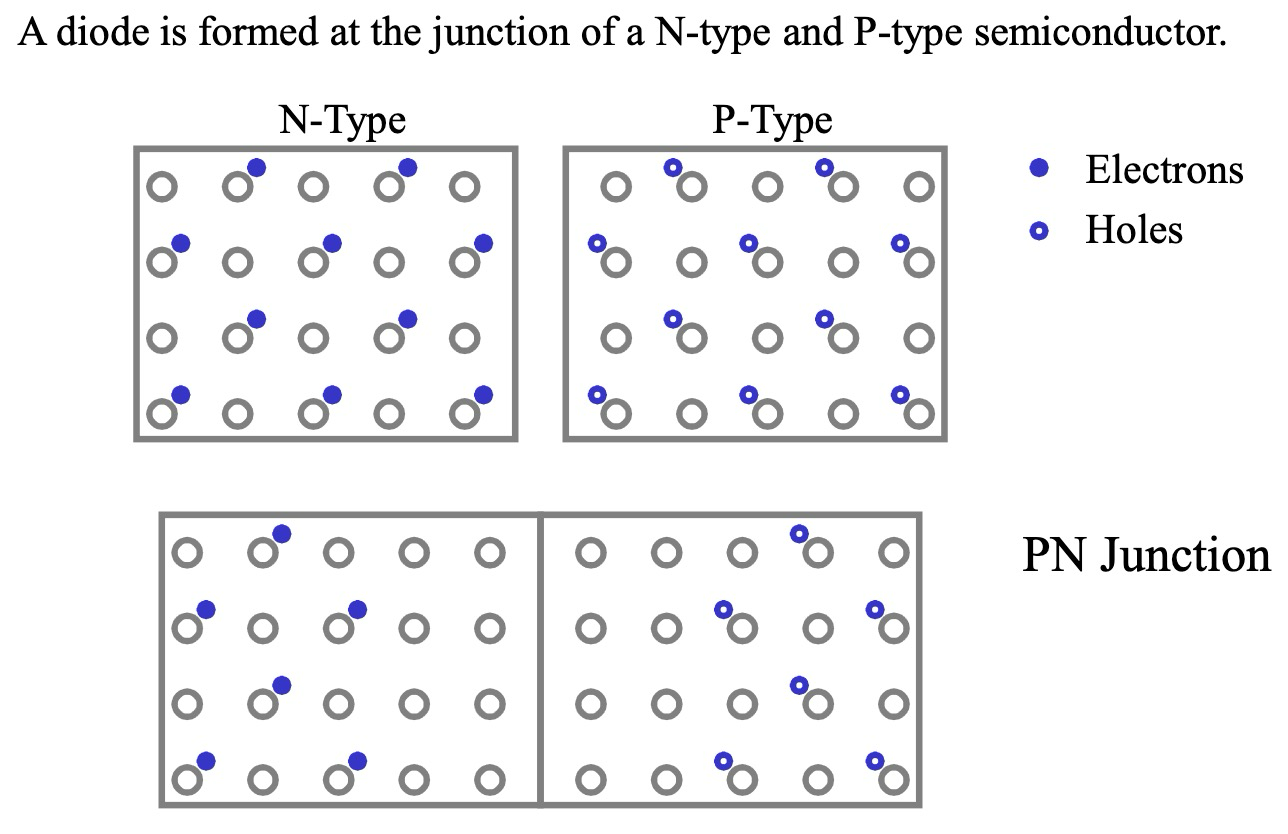
二极管
二极管 (Diode) 是利用 PN 结 的单向导电性制成的半导体器件,是电子电路中最基本和重要的元件之一。
PN 结的形成
PN 结 (PN Junction) 形成于 P 型半导体 和 N 型半导体 的交界面。
- 载流子扩散与复合:在 P-N 结形成初期,P 区的空穴和 N 区的电子会自发地向对方扩散。在扩散过程中,电子和空穴相遇会发生复合 (Recombination),导致耗尽区 (Depletion Region) 的形成。
- 耗尽区:耗尽区是指在 P-N 结界面附近,由于载流子复合而几乎没有自由载流子的区域。耗尽区内存在由 N 区指向 P 区的内建电场,阻碍载流子的进一步扩散。
- 势垒:内建电场形成了势垒,阻止电子从 N 区流向 P 区,空穴从 P 区流向 N 区。
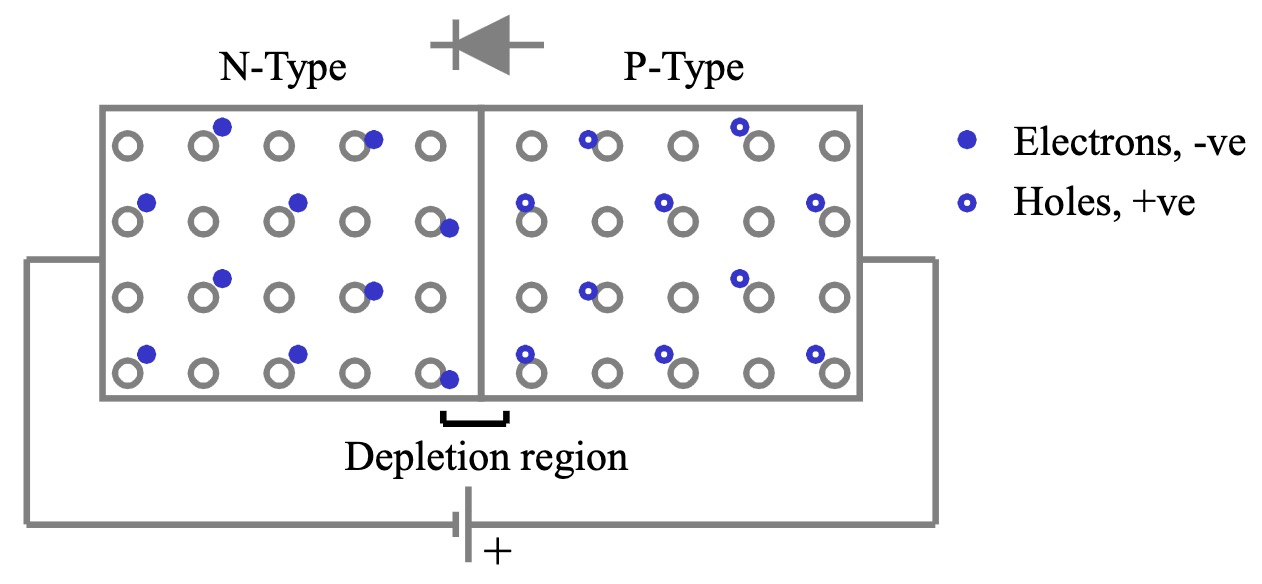
PN 结的正向偏置
正向偏置 (Forward Bias) 是指将外部电源的正极连接到 P 区,负极连接到 N 区。
- 耗尽区变窄:正向电压产生的电场方向与内建电场方向相反,削弱了势垒,使得耗尽区变窄。
- 电流导通:当正向电压超过一定阈值 (开启电压或死区电压) 后,势垒被克服,大量的电子从 N 区注入 P 区,空穴从 P 区注入 N 区,形成较大的正向电流,PN 结导通。
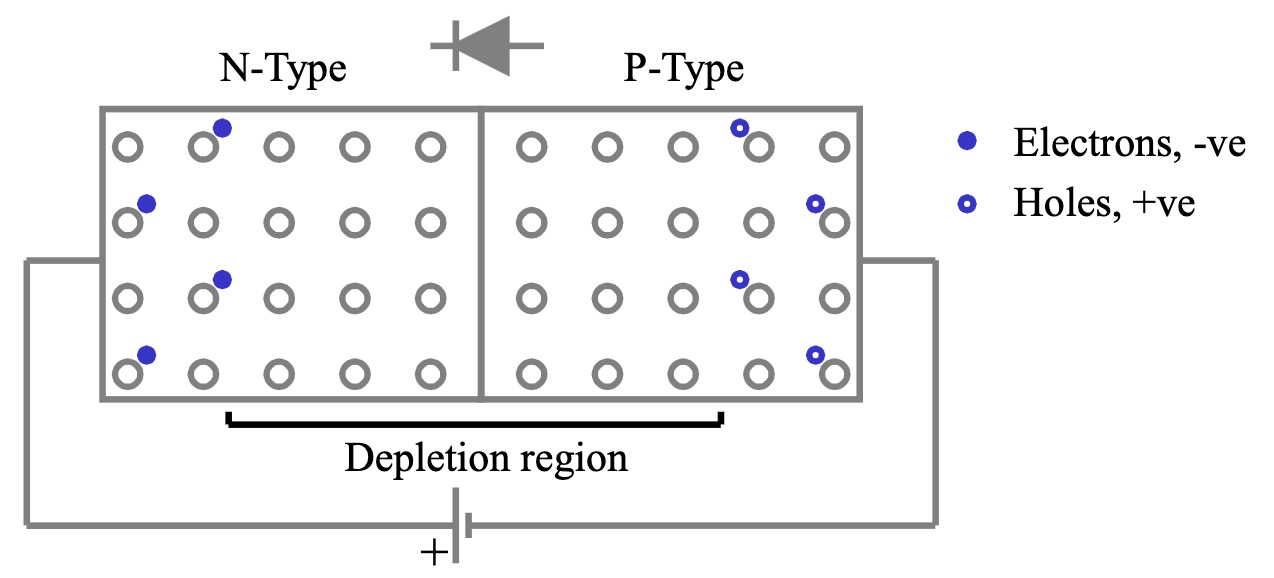
PN 结的反向偏置
反向偏置 (Reverse Bias) 是指将外部电源的正极连接到 N 区,负极连接到 P 区。
- 耗尽区变宽:反向电压产生的电场方向与内建电场方向相同,增强了势垒,使得耗尽区变宽。
- 电流截止:势垒进一步增大,阻止了多数载流子的流动。只有少量的少数载流子 (P 区的电子和 N 区的空穴) 在反向电场作用下漂移,形成很小的反向饱和电流,PN 结截止。理想情况下,反向电流可以忽略不计。
PN 结电流方向与导电方向
- 电子流动方向:在正向偏置时,电子从 N 型硅 -> P 型硅 流动。
- 传统电流方向:导电方向 (Conventional Current Direction) 与电子流动方向相反,为 P -> N。
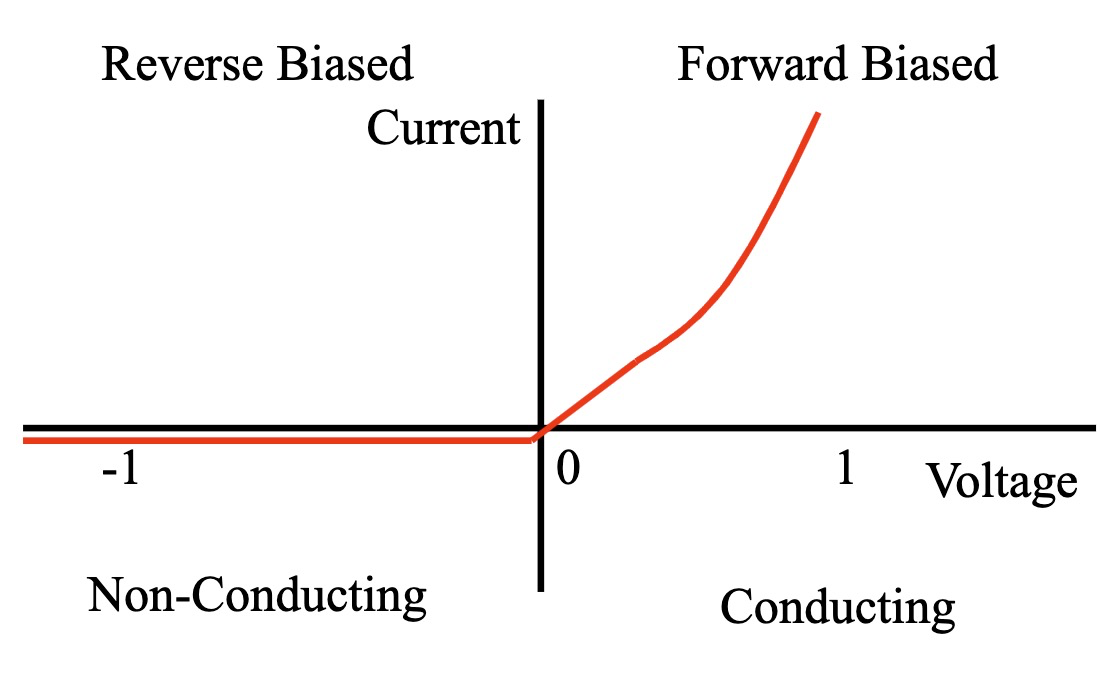
二极管的伏安特性曲线
伏安特性曲线 (Current-Voltage Characteristic Curve) 描述了二极管电流随电压变化的规律,体现了二极管的单向导电性。
- 正向导通区:当正向电压超过开启电压后,电流随电压呈指数增长。
- 反向截止区:当施加反向电压时,只有很小的反向饱和电流,电流接近于零。
- 击穿区:当反向电压超过反向击穿电压时,反向电流会急剧增大,二极管可能损坏。
二极管的典型应用
二极管因其单向导电性,在电路中有着广泛的应用。
- 整流 (Rectification):利用二极管的单向导电性,将交流电 (AC) 转换为 直流电 (DC)。这是二极管最常见的应用之一,例如在电源电路中,将交流电源转换为电子设备所需的直流电源。
- 电路保护 (Circuit Protection):在电路中反向并联二极管,可以限制电压,防止过电压或极性错误对敏感元件的损坏。例如,在继电器线圈两端反向并联二极管,可以吸收断电时产生的反向感应电动势,保护开关器件。
- 逻辑电路 (Logic Circuits):可以利用二极管的开关特性,搭建各种逻辑门电路,例如与门、或门等。早期的计算机中曾使用二极管逻辑门,但由于体积大、功耗高等缺点,已被晶体管逻辑门取代。
Lecture 8: 晶体管与场效应管
结型晶体管 (BJT)
结型晶体管的结构与原理
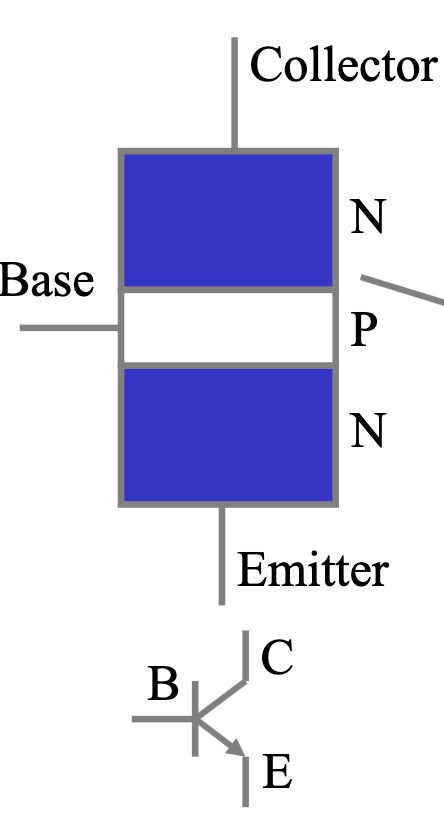
结型晶体管 (Bipolar Junction Transistor, BJT),俗称三极管,是一种电流控制电流型的半导体器件,常用于放大和开关电路中。NPN 型晶体管是最常见的 BJT 类型之一,它由三个区域构成:
- 发射极 (Emitter, E):晶体管的电流注入区,多数载流子由此注入。
- 基极 (Base, B):晶体管的控制区,通过基极电流控制集电极电流。
- 集电极 (Collector, C):晶体管的电流收集区,收集由发射极注入并受基极控制的载流子。
BJT 的工作原理可以类比为一个小阀门:
- 输入控制:基极电流 (IB) 作为输入信号,是一个较小的电流。
- 输出放大:集电极电流 (IC) 作为输出信号,是一个被放大的较大电流。
结型晶体管的电流增益
电流增益 (Current Gain) 是衡量 BJT 放大能力的重要参数,通常用符号 β (贝塔) 或 hFE 表示。它定义为集电极电流 (IC) 与 基极电流 (IB) 之比:
$\beta = \frac{I_C}{I_B}$
公式中:
- IC (集电极电流):输出电流,流经集电极的电流。
- IB (基极电流):输入电流,流经基极的电流。
- β (电流增益):电流放大倍数,无量纲参数,典型 BJT 的 β 值范围为 20 到 200,甚至更高。
电流增益的计算示例:
假设:
- 基极电流 IB = 1 mA (毫安)
- 电流增益 β = 100
则集电极电流 IC 为:
$I_C = \beta \times I_B = 100 \times 1 \text{ mA} = 100 \text{ mA}$
结论:1 mA 的输入基极电流 可以控制 100 mA 的输出集电极电流,实现了电流的放大,体现了电流增益的作用。
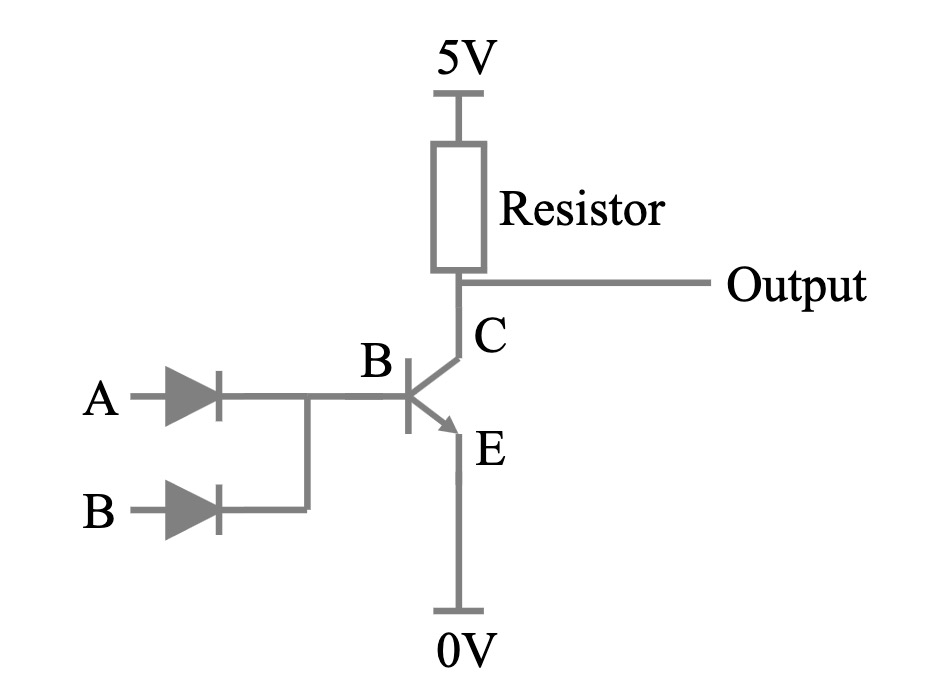
基于BJT的或非门 (NOR Gate) 实现
或非门 (NOR Gate) 是一种基本的逻辑门,其输出为低电平,当且仅当所有输入均为低电平时;否则输出为高电平。使用 NPN 型晶体管可以构建 NOR 门电路。
电路原理:
- 输入端 (A, B):分别连接两个输入信号 IA 和 IB。
- 输出端 (Output):电路的输出信号。
- 晶体管 (T):NPN 型晶体管作为核心开关元件。
- 电阻 (R):限制电流和提供合适的偏置。
工作原理:
- 输入均为低电平 (IA = IB = 0):
- 此时,基极电流为零,晶体管 T 处于截止状态,相当于一个大电阻。
- 电流无法通过晶体管流向 发射极 (IE),只能流向 输出端 (Output),因此 输出为高电平。
- 输入至少有一个高电平 (IA + IB ≠ 0):
- 此时,至少有一个基极电流不为零,晶体管 T 处于导通状态,相当于一个小电阻。
- 电流主要流经晶体管 T 到发射极 (IE),输出端 (Output) 被短路到地,因此 输出为低电平。
金属氧化物半导体场效应晶体管 (MOSFET)
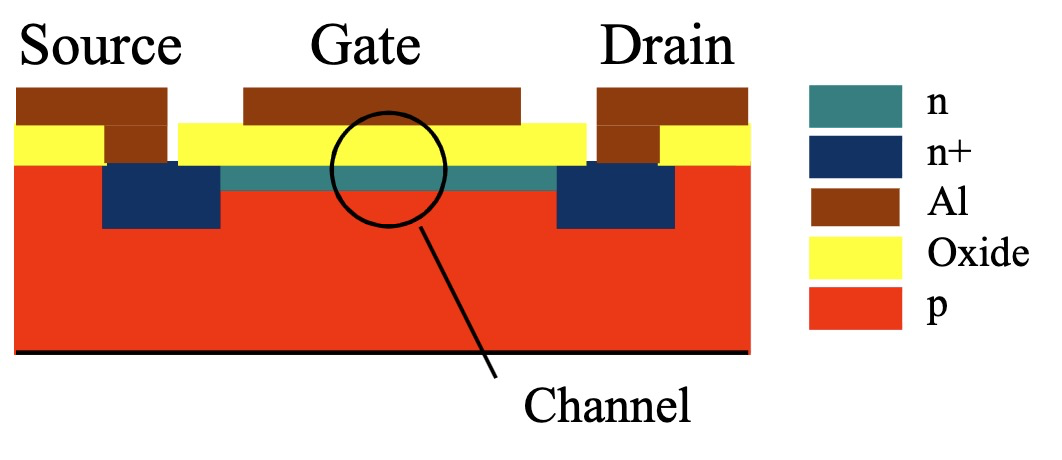
金属氧化物半导体场效应晶体管 (Metal-Oxide-Semiconductor Field-Effect Transistor, MOSFET) 是一种电压控制电流型的半导体器件,相比 BJT,MOSFET 具有输入阻抗高、功耗低等优点,被广泛应用于集成电路中。
MOSFET 的基本结构
MOSFET 主要由以下几个部分构成:
- 栅极 (Gate, G):通常为金属层或多晶硅层,通过一层绝缘层 (通常是二氧化硅 (SiO2)) 与半导体衬底隔离。栅极电压用于控制沟道的导电性。
- 源极 (Source, S):电流的注入端,载流子由此进入沟道。
- 漏极 (Drain, D):电流的输出端,载流子由此离开沟道。
- 衬底 (Body/Substrate, B):半导体基体,通常是硅材料。衬底的电位通常与源极或漏极相连,在某些 MOSFET 中,衬底也可以作为独立的控制端。
NMOS 场效应晶体管的工作原理
以 N 沟道 MOSFET (NMOS) 为例,说明 MOSFET 的工作原理。
工作原理:
-
未施加栅极电压 (VG = 0):
- 在栅极下方的 P 型衬底 中,存在少量自由电子 (少数载流子) 和大量空穴 (多数载流子)。
- 由于没有栅极电压的吸引,自由电子分布稀少,源极 (S) 和 漏极 (D) 之间无法形成导电沟道,器件截止。
-
施加正向栅极电压 (VG > 0):
- 电子积累:正向栅极电压会在栅极下方的 P 型衬底表面吸引大量的自由电子。
- 空穴耗尽:同时,正向栅极电压会排斥空穴,导致栅极下方的空穴浓度降低,形成耗尽层。
- N 沟道形成:当栅极电压达到一定阈值后,栅极下方的自由电子积累到足够多,在源极和漏极之间形成一条N 型导电沟道,称为 N 沟道 (N-channel)。
- 电流导通:一旦 N 沟道形成,在 漏极电压 (VD) 的作用下,电子可以从源极 (S) 经 N 沟道 流向 漏极 (D),形成漏极电流 (ID),器件导通。
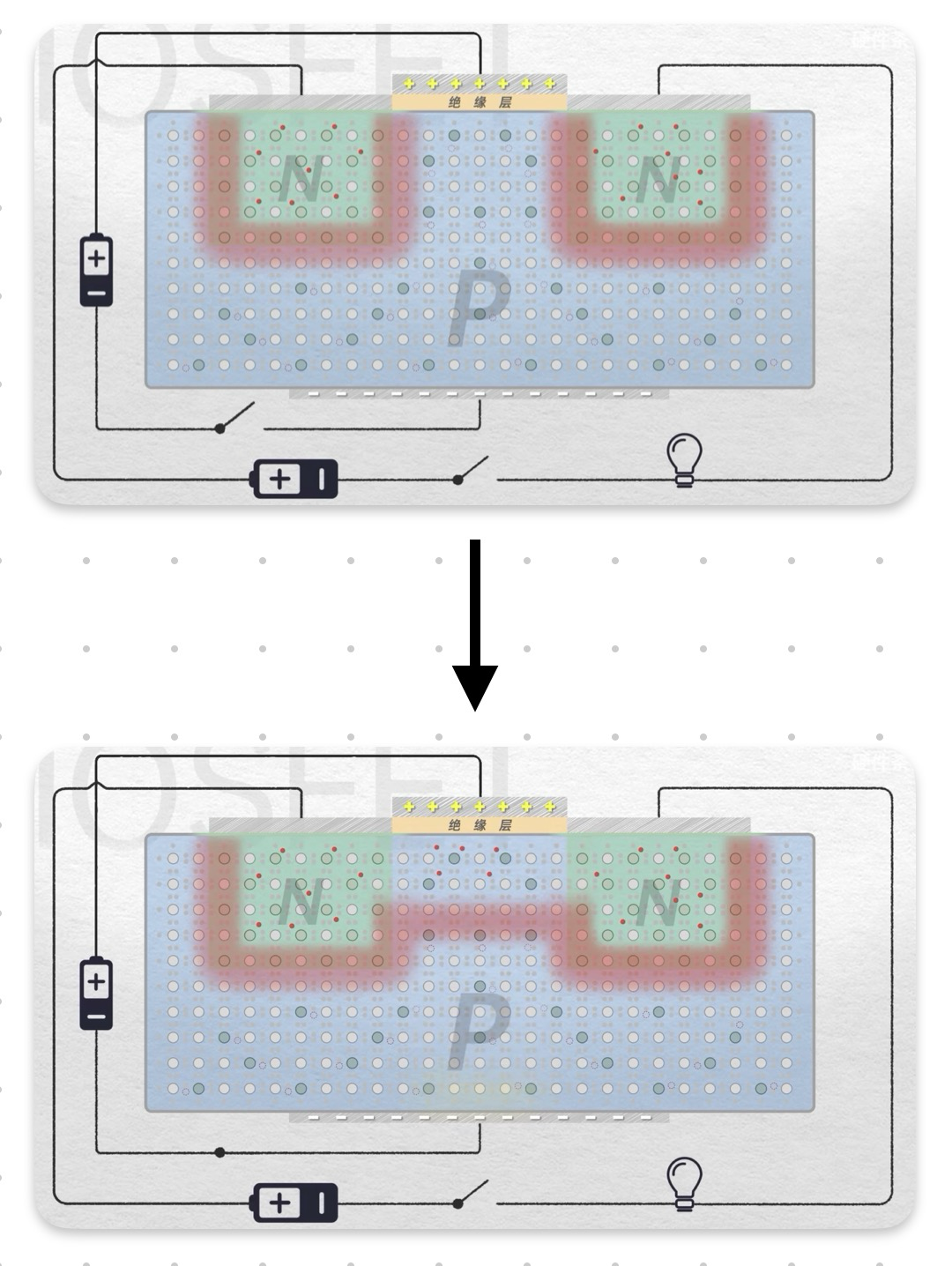
Note
这里MOSFET讲的很抽象,参考【硬核科普】带你认识CPU第00期——什么是MOSFET
区分
- N 型 (N-channel) MOSFET: 载流子是电子 (Electrons) - 记住 N 代表 Negative (负),电子带负电,需要 正栅极电压 (Positive Gate Voltage) 才能导通。
- N 型 (N-channel) MOSFET: 载流子是空穴 (Holes) - 记住 P 代表 Positive (正),空穴可以被认为是带正电的,需要 负栅极电压 (Negative Gate Voltage) 才能导通。
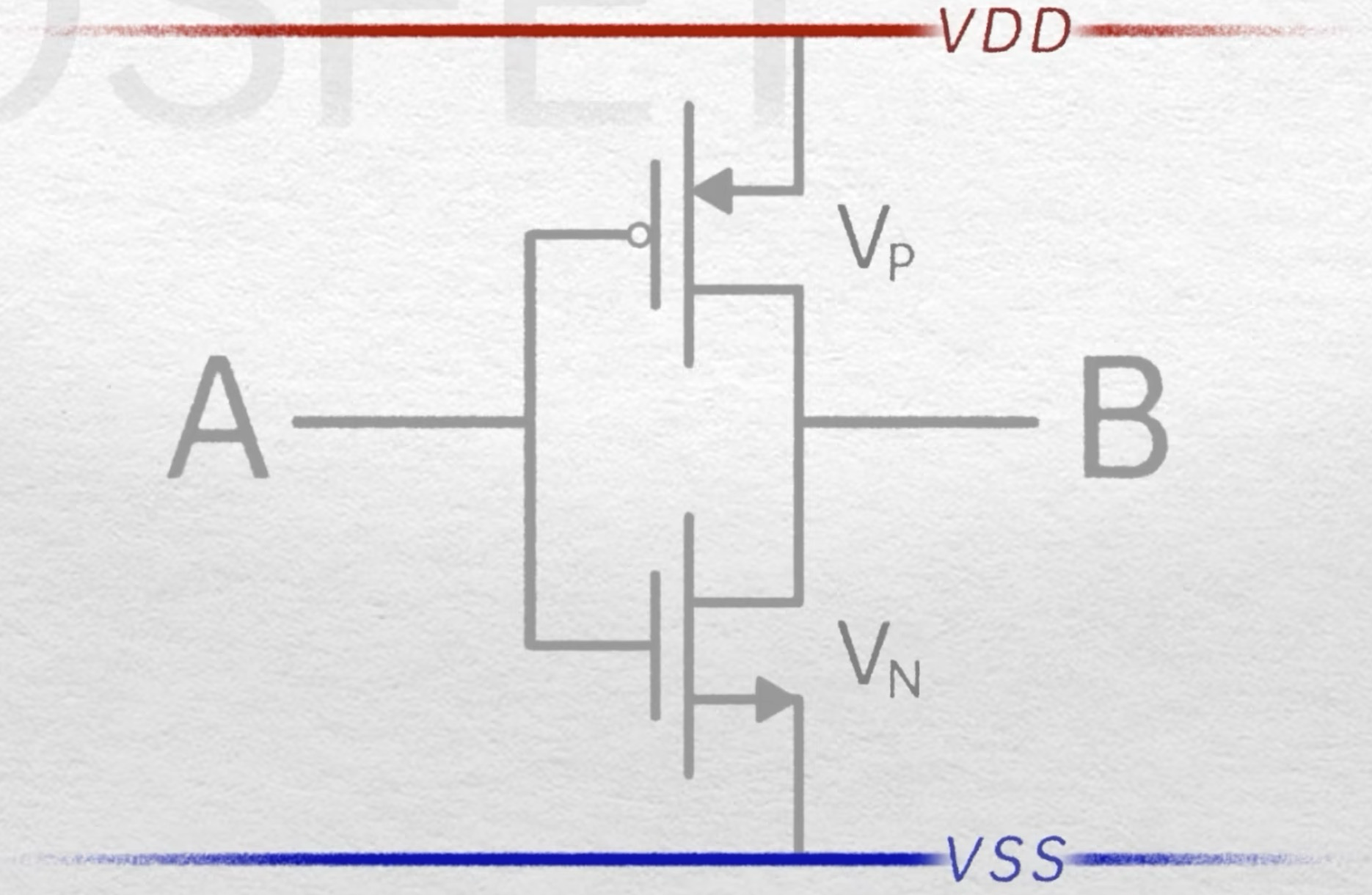
互补金属氧化物半导体 (CMOS)
互补金属氧化物半导体 (Complementary Metal-Oxide-Semiconductor, CMOS) 电路是现代数字电路中最主流的电路形式。CMOS 电路利用 PMOS (P 沟道 MOSFET) 和 NMOS (N 沟道 MOSFET) 的互补特性,实现低功耗、高性能的逻辑功能。
CMOS 反相器的工作原理
CMOS 反相器 (Inverter) 是 CMOS 电路中最基本的逻辑门,它由一个 PMOS 管 和一个 NMOS 管 串联组成。
工作原理:
-
输入高电平:
- 当 输入端 (A) 为高电平时,NMOS 管导通,PMOS 管截止。
- 电路相当于 输出端 (B) 通过导通的 NMOS 管接地,因此 输出为低电平。
-
输入低电平:
- 当 输入端 (A) 为低电平时,PMOS 管导通,NMOS 管截止。
- 电路相当于 输出端 (B) 通过导通的 PMOS 管连接到电源 (VDD),因此 输出为高电平。
总结:CMOS 反相器实现了输入与输出电平的反转,是构成更复杂 CMOS 逻辑门的基础。
Lecture 9: I/O
I/O
I/O 操作与地址空间
I/O (Input/Output) 操作是计算机系统中 CPU (中央处理器) 与外部设备进行数据交换的关键方式。8086 微处理器架构中,I/O 操作的设计特点包括:
- 独立的 I/O 地址空间:
- 8086 使用 20 位地址总线 用于内存读写,但为 I/O 操作划分了 16 位的 I/O 地址空间。
- 这种分离设计允许系统区分内存访问和 I/O 访问,通过额外的控制线进行选择。
- 端口 (Port) 的概念:
- I/O 空间中的每个位置都被称为 端口 (Port)。端口是 CPU 与外部设备通信的接口。
- 8086 的 16 位 I/O 地址空间,可以映射为 64K 的 8 位端口 (字节) 或 32K 的 16 位端口 (字)。
- 指令集差异:
- 相较于内存控制,用于控制 I/O 端口 的汇编指令数量相对较少,体现了 I/O 操作的简洁性。
- 内存映射 I/O:
- 值得注意的是,某些硬件设备,例如屏幕显示,可能被映射到内存空间,而不是传统的 I/O 空间。这种技术称为 内存映射 I/O (Memory-mapped I/O)。
常见 I/O 地址示例
下表列出了一些 常见 I/O 地址 及其用途,这些地址在早期的 IBM PC 兼容机 中被广泛使用,用于控制各种外围设备:
| 地址 | 名称 | 方向 | 用途 |
|---|---|---|---|
| 0x378 | Parallel Printer Latch | 输出 | 并行打印机数据端口,常用于 LPT1 (Line Printer 1),向打印机发送打印数据. |
| 0x37A | Printer Control Latch | 输出 | 并行打印机控制端口,常用于 LPT1,控制打印机的各种操作,例如初始化、选择打印机等. |
| 0x379 | Printer Status | 输入 | 并行打印机状态端口,常用于 LPT1,读取打印机的状态信息,例如是否忙碌、是否有纸等. |
| 0x3D9 | VDU Colour Register | 输出 | 视频显示单元 (VDU) 颜色寄存器,用于设置 DOS 文本模式 下的边框颜色. |
| 0x278 | Parallel Printer Latch | 输出 | 并行打印机数据端口,常用于 LPT2 (Line Printer 2),向打印机发送打印数据. |
总线共享与内存访问周期
- 总线复用:由于 8086 处理器硬件引脚数量的限制,内存地址总线 和 数据总线 实际上是共享相同的物理引脚。
- 控制线区分:因此,需要额外的控制线来区分当前的总线操作是内存访问还是 I/O 数据传输。
- 内存访问时序:8086 完成一次内存访问周期 通常需要 4 个时钟周期, 步骤如下:
- 周期 1:CPU 发送内存地址到地址总线上。
- 周期 2-3:CPU 等待内存响应,并进行数据传输 (读取或写入) 。
- 周期 4:结束周期,完成本次内存访问。
Z80A CPU 架构对比
分离总线设计
与 8086 的总线复用设计不同,Z80A CPU 的 数据总线 和 地址总线 采用了分离的设计,拥有独立的引脚,简化了总线控制逻辑,并可能提升总线操作的效率。
基于 AND 门的地址解码器
为了实现地址解码,Z80A 系统中使用了几个巨大的 AND 门 作为地址解码器 (Address Decoder)。
- 地址匹配:当 16 个输入信号 与预设的设备地址 完全匹配时,AND 门输出逻辑真 (高电平),否则输出逻辑假 (低电平)。
- 控制线:系统使用两根控制线 (图中绿色和紫色线条) 来指示当前操作是读取还是写入,以及针对哪个设备。
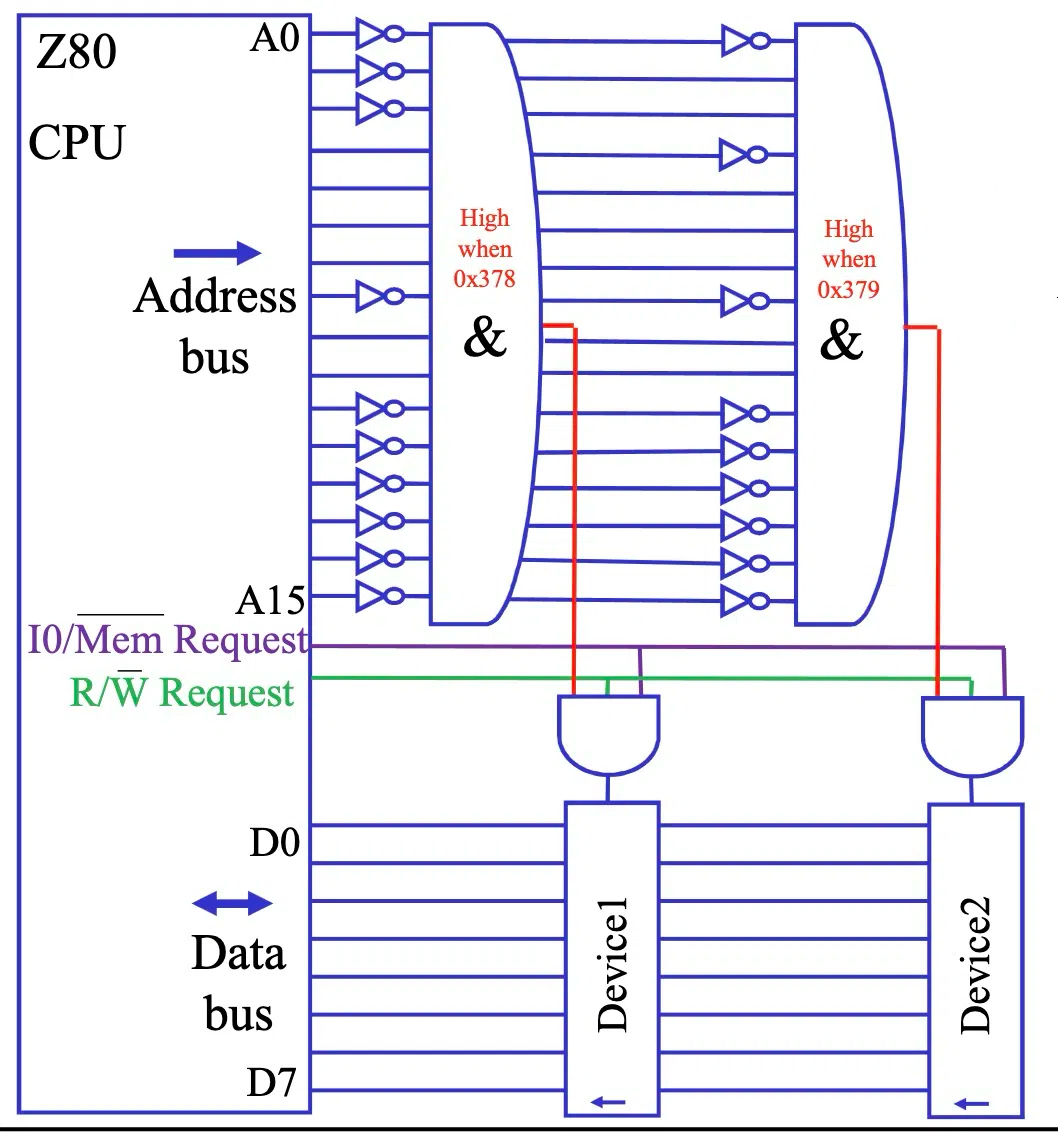
三态缓冲器与数据传输控制
三态缓冲器 (Tri-state Buffer) 在 I/O 接口中扮演着重要的角色,用于控制数据流的方向和连接状态。
- 控制信号:AND 门 的输出 (地址匹配结果) 和两根控制线 的信号,通过另一个 AND 门 组合成最终的控制信号。
- 三态输出:三态缓冲器 具有三种输出状态:高电平 (1), 低电平 (0), 和 高阻态 (High-Z)。
- 根据 控制信号 的状态,三态缓冲器决定是否将 输入信号 直接传输到输出,或者切换到高阻态,相当于断开连接。
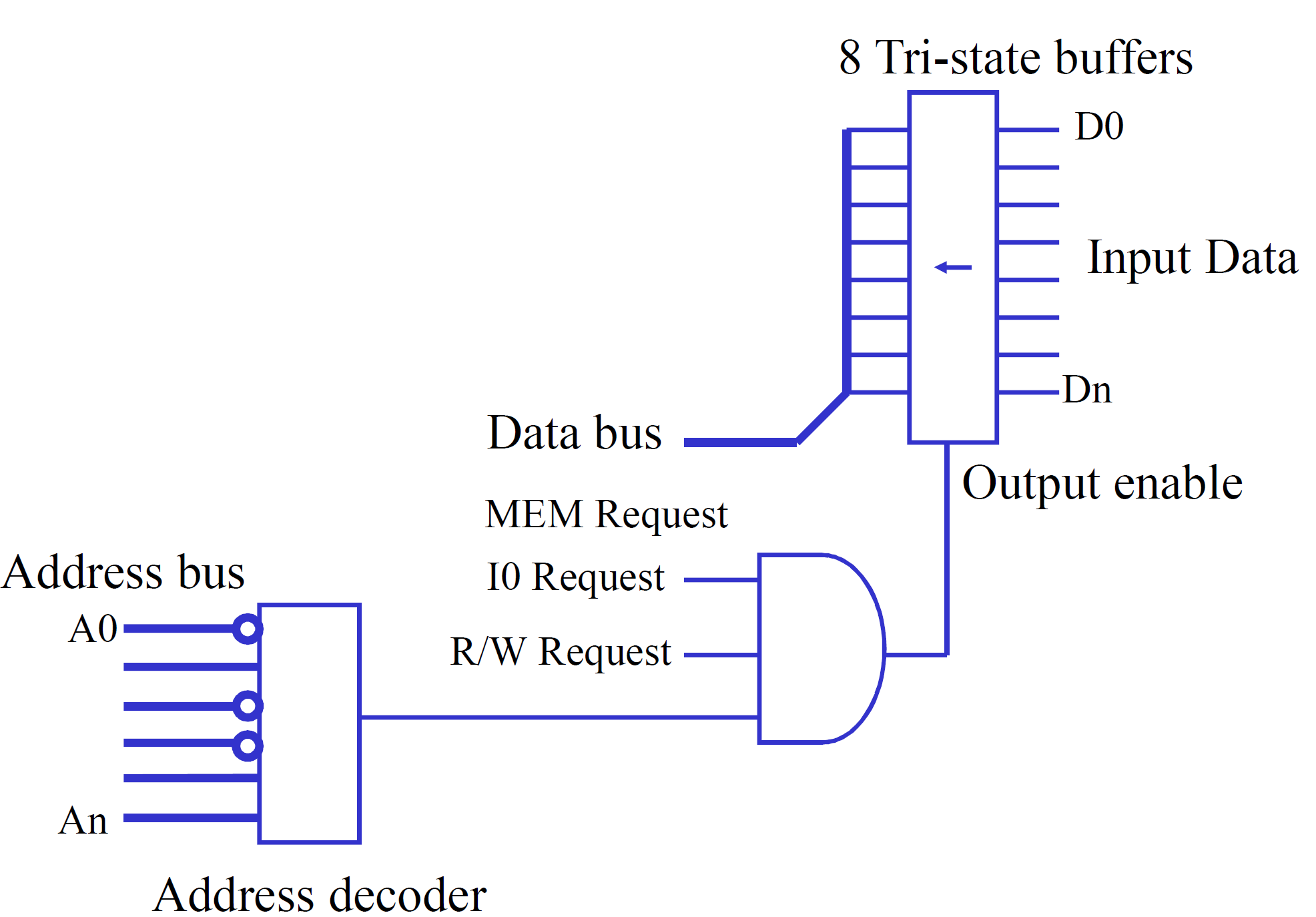
对于输出操作,三态缓冲器会被 D 触发器 (D Flip-Flop) 替代,用于锁存输出数据。
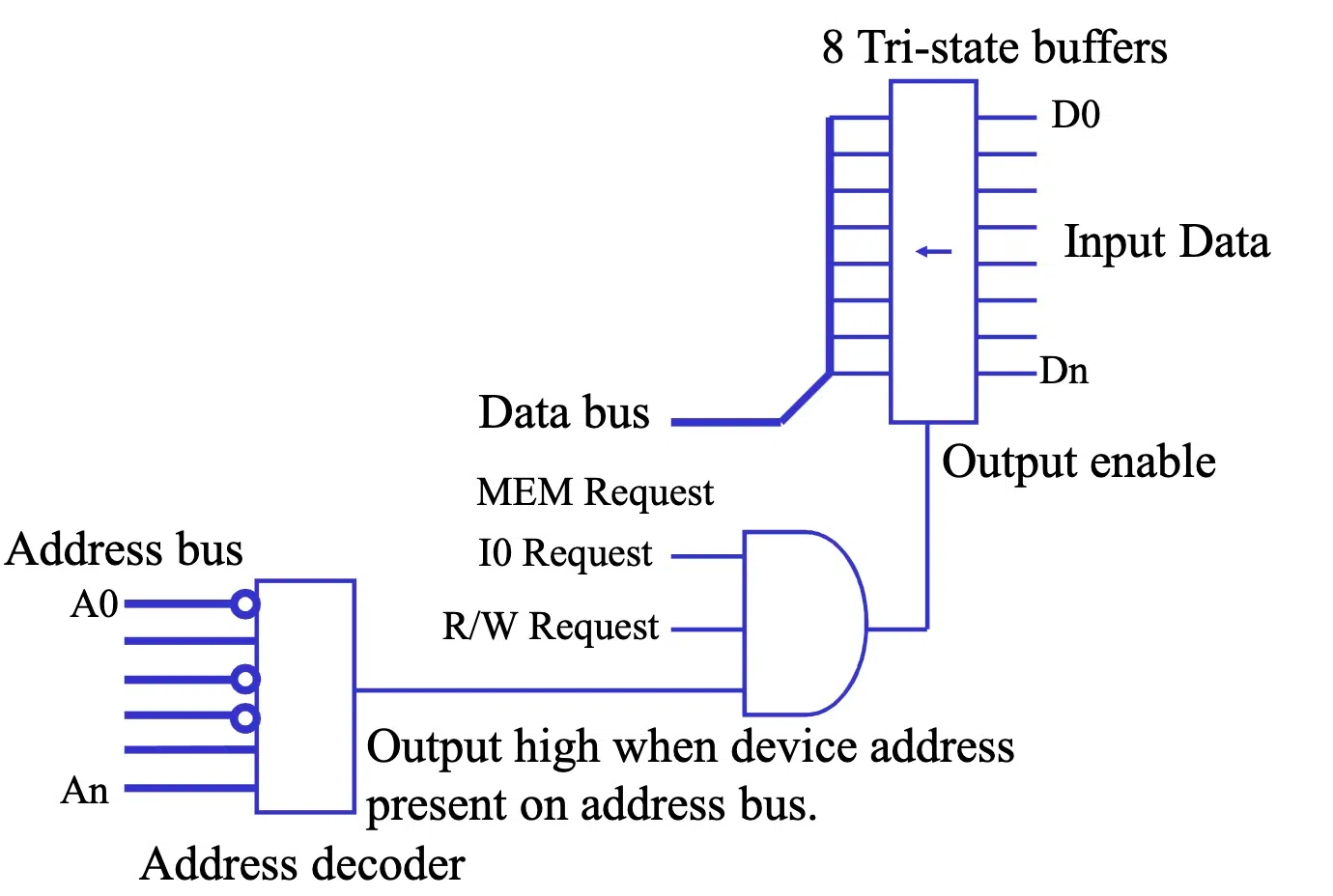
汇编语言 I/O 指令
OUT 指令:端口输出
OUT 指令 用于将数据从 CPU 寄存器 (通常是累加器 AL, AX, EAX) 写入 到指定的 I/O 端口。
OUT port, acc- port: I/O 端口地址,可以是立即数或存储在 DX 寄存器中。
- acc: 累加器 (
AL,AX, 或EAX),存储着要输出的数据。
OUT 指令的两种寻址模式:
-
立即数模式 (Immediate Mode):
- 端口地址 直接在指令中指定为 立即数 (0-255)。
- 寻址范围限制: 这种模式只能访问 256 个端口 (地址范围 00h-FFh)。
OUT 30h, AL ; 将 AL 寄存器中的 8 位数据写入端口地址 30h
-
DX 寄存器模式 (Register Mode):
- 端口地址 存储在 DX 寄存器 中。
- 寻址范围扩展: 这种模式可以访问 64K 个端口 (0-65535),提供了更大的 I/O 空间访问能力。
mov dx, 0x378 ; 将端口地址 0x378 放入 DX 寄存器 OUT DX, AX ; 将 AX 寄存器中的 16 位数据写入 DX 寄存器指定的端口
IN 指令:端口输入
IN 指令 用于从指定的 I/O 端口 读取数据 到 CPU 寄存器 (通常是累加器 AL, AX, EAX) 。
IN acc, port- acc: 累加器 (
AL,AX, 或EAX),用于存储从端口读取的数据。 - port: I/O 端口地址,可以是立即数或存储在 DX 寄存器中。
IN 指令的两种寻址模式:
-
立即数模式 (Immediate Mode):
- 端口地址 直接在指令中指定为 立即数 (0-255)。
- 寻址范围限制: 这种模式只能访问 256 个端口 (地址范围 00h-FFh)。
IN AL, 30h ; 从端口地址 30h 读取 8 位数据,存储到 AL 寄存器
-
DX 寄存器模式 (Register Mode):
- 端口地址 存储在 DX 寄存器 中。
- 寻址范围扩展: 这种模式可以访问 64K 个端口 (0-65535),提供了更大的 I/O 空间访问能力。
mov dx, 0x379 ; 将端口地址 0x379 放入 DX 寄存器 IN AX, DX ; 从 DX 寄存器指定的端口读取 16 位数据,存储到 AX 寄存器
[!NOTE] I/O 特权级 (IOPL)
IOPL (I/O Privilege Level, I/O 特权级) 是 x86 架构 中用于控制 I/O 端口访问权限 的保护机制。它存储在 EFLAGS 寄存器 的 第 12 和 13 位,定义了程序执行 I/O 指令 (如
IN,OUT) 所需的最低特权级别 (CPL, Current Privilege Level)。IOPL 是一个 2 位 的值,取值范围为 0 到 3,数值越小特权级别越高:
- 特权级检查:在执行 I/O 指令时,CPU 会比较当前程序的 CPL 和 IOPL。
- 当 CPL ≤ IOPL 时:程序被允许直接执行 I/O 指令 (如
IN,OUT) ,可以访问 I/O 端口。- 当 CPL > IOPL 时:程序没有权限直接执行 I/O 指令。如果尝试执行,会触发 一般保护异常 (General Protection Fault, #GP),导致程序终止或系统崩溃。
作用:IOPL 机制增强了系统的安全性和稳定性,防止低特权级别的程序非法访问硬件设备,保护系统资源。
中断机制
中断的引入与优势
中断 (Interrupt) 是一种重要的异步事件处理机制,允许外部设备或软件事件打断 CPU 的正常执行流程,转而处理更紧急或重要的任务。
应用场景:考虑 CPU 从 HDD (硬盘驱动器) 读取数据的场景。
- 传统轮询方式的低效:若 CPU 采用轮询 (Polling) 方式,需要周期性地查询 HDD 的状态,等待数据就绪.HDD 响应速度通常较慢 (例如毫秒级,涉及磁头移动和盘片旋转) ,CPU 在等待期间会空耗大量的计算资源。
- 中断机制的优势:中断机制 提供了更高效的方案。
- 设备主动通知:当 HDD 数据就绪时,主动向 CPU 发送中断信号。
- CPU 响应:CPU 接收到中断信号后,暂停当前任务,转而处理数据读取操作。
- 资源高效利用:CPU 在 HDD 准备数据的期间,可以执行其他任务,避免了无谓的等待,提高了系统资源的利用率。
- 低功耗:CPU 可以进入低功耗模式等待中断,进一步降低能耗。
中断处理流程
中断发生时的典型处理流程:
- 暂停当前程序:CPU 暂停 当前正在执行的主程序。
- 调用中断处理程序:CPU 跳转 到一个专门服务中断的程序,称为 中断处理程序 (Interrupt Handler) 或 中断服务例程 (ISR, Interrupt Service Routine)。
- 返回主程序:中断处理程序执行完毕后,将控制权返回 到之前被中断的主程序,从断点处继续执行。
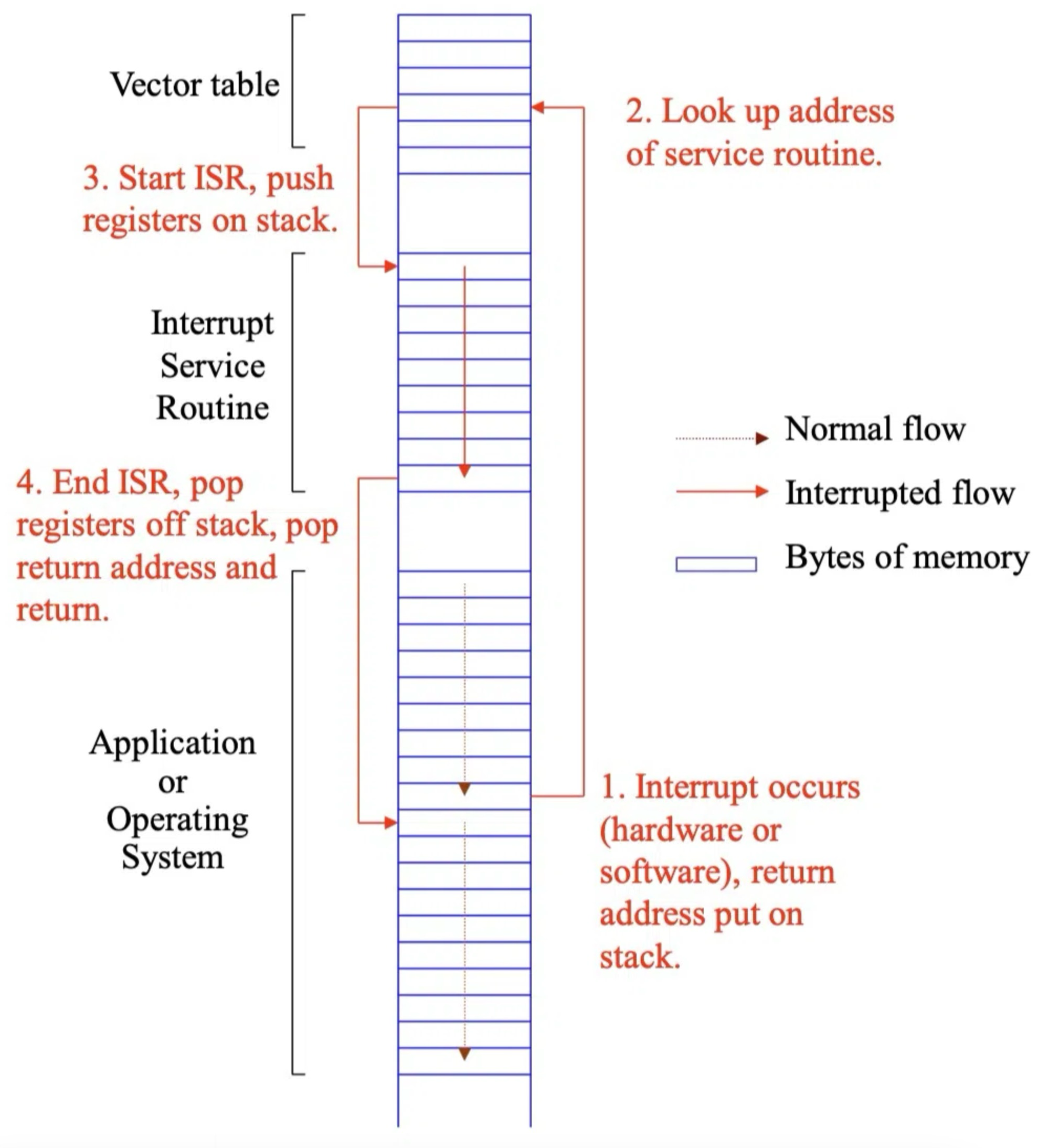
8086 的中断类型
8086 架构支持多种类型的中断,可以根据触发来源进行分类:
- 硬件中断 (Hardware Interrupt):
- 由外部硬件设备通过处理器的引脚发出中断请求信号。
- INTR (Interrupt Request) 引脚:可屏蔽中断,可以通过设置中断标志位 (IF) 来屏蔽或使能。
- NMI (Non-Maskable Interrupt) 引脚:非可屏蔽中断,优先级高于 INTR,通常用于处理更紧急的硬件错误,如电源故障或内存奇偶校验错误。
- 由外部硬件设备通过处理器的引脚发出中断请求信号。
- 异常中断 (Exception Interrupt):
- 由 CPU 内部错误 或异常条件触发。
- 常见的异常包括:除以零错误、非法操作码、页错误 等。
- 用途:通常用于打印错误信息、终止程序 或进行错误恢复。
- 软件中断 (Software Interrupt):
- 由程序主动执行汇编指令
INT引起。 - 指令格式:
INT n,其中n为中断号 (0-255)。 - 用途:一种软件请求操作系统服务的机制,例如 DOS 系统调用 就是通过软件中断 实现的。可以理解为 调用 BIOS (基本输入/输出系统) 中的函数。
- 由程序主动执行汇编指令
时间片轮询调度 vs 抢占式调度
中断机制 在操作系统中被广泛用于实现任务调度,两种典型的调度方式是 时间片轮询调度 和 抢占式调度。
-
时间片轮询调度 (Time Slice Scheduling):
- 轮流执行:操作系统将 CPU 时间 划分为固定长度的时间片 (例如 20ms) 。
- 任务切换:操作系统轮流 为每个就绪任务分配一个时间片,顺序执行。当时间片用完,即使任务未完成,也强制切换到下一个任务。
- 硬件轮询:CPU 通常需要主动轮询硬件设备 的状态,以确定是否有 I/O 请求需要处理。
- 适用场景:适用于 简单的多任务系统。
- 缺点:可能存在资源浪费,实时性较差。
-
抢占式调度 (Pre-emptive Scheduling):
- 优先级抢占:操作系统为每个任务分配优先级。高优先级任务 可以中断 正在执行的低优先级任务,优先获得 CPU 执行权。
- 中断驱动:硬件设备 通过中断 通知 CPU I/O 事件 的发生。
- 快速响应:CPU 响应中断 速度快,能够及时处理外部事件。
- 适用场景:适用于 实时性要求高 的系统,例如 实时操作系统 (RTOS)。
- 优点:实时性好,响应速度快,资源利用率高。
中断优先级
中断优先级 (Interrupt Priority) 用于区分不同中断请求的重要性。在多中断源的系统中,当多个中断同时发生时,优先级较高的中断 会被优先处理。
- 中断嵌套:中断服务例程 (ISR) 可以嵌套执行,即在执行一个 ISR 的过程中,可以被更高优先级的中断 再次中断。
- 优先级编码:通常使用中断号 或 优先级编码 来表示中断的优先级。
- 编号越小的 ISR,优先级越高。例如,在某些系统中,硬件中断 的优先级通常高于软件中断,NMI 的优先级高于 INTR。
- 优先级管理:中断控制器 (如 8259A) 负责管理中断优先级,仲裁 中断请求,并决定 哪个中断应该被优先响应。
中断向量表 (IVT)
中断向量表 (Interrupt Vector Table, IVT) 是计算机系统中管理和处理中断 的核心数据结构。
-
作用:存储中断服务例程 (ISR) 的入口地址。当中断发生时,CPU会根据中断号 在 中断向量表 中查找相应的入口地址,然后跳转到该地址执行中断处理程序。
-
存储位置:中断向量表 通常位于RAM (随机访问存储器的起始地址区域,即 前 1024 字节 (地址范围:0000:0000 到 0000:03FF) 。
-
条目结构:每个中断向量 在中断向量表中占用 4 个字节。
- 前 2 个字节:存储 指令指针 (IP, Instruction Pointer),即 ISR 代码段内的偏移地址。
- 后 2 个字节:存储 代码段选择器 (CS, Code Segment),即 ISR 代码所在的段地址。
-
地址计算:对于给定的中断号
n,其在中断向量表中的起始地址可以通过以下公式计算:中断向量地址 = 中断号 * 4例如,假设 中断号为
0x3:- 中断向量表位置:
0x0C:0x0F - 入口地址解析:例如
0x0C:0x0F处存储的值为0x0070:0x06F4,则表示 中断处理程序的入口地址 为 代码段0x0070,偏移地址0x06F4。CPU 将跳转到 物理地址0x0070 << 4 + 0x06F4处开始执行 ISR 代码。
- 中断向量表位置:
中断向量表结构示意图
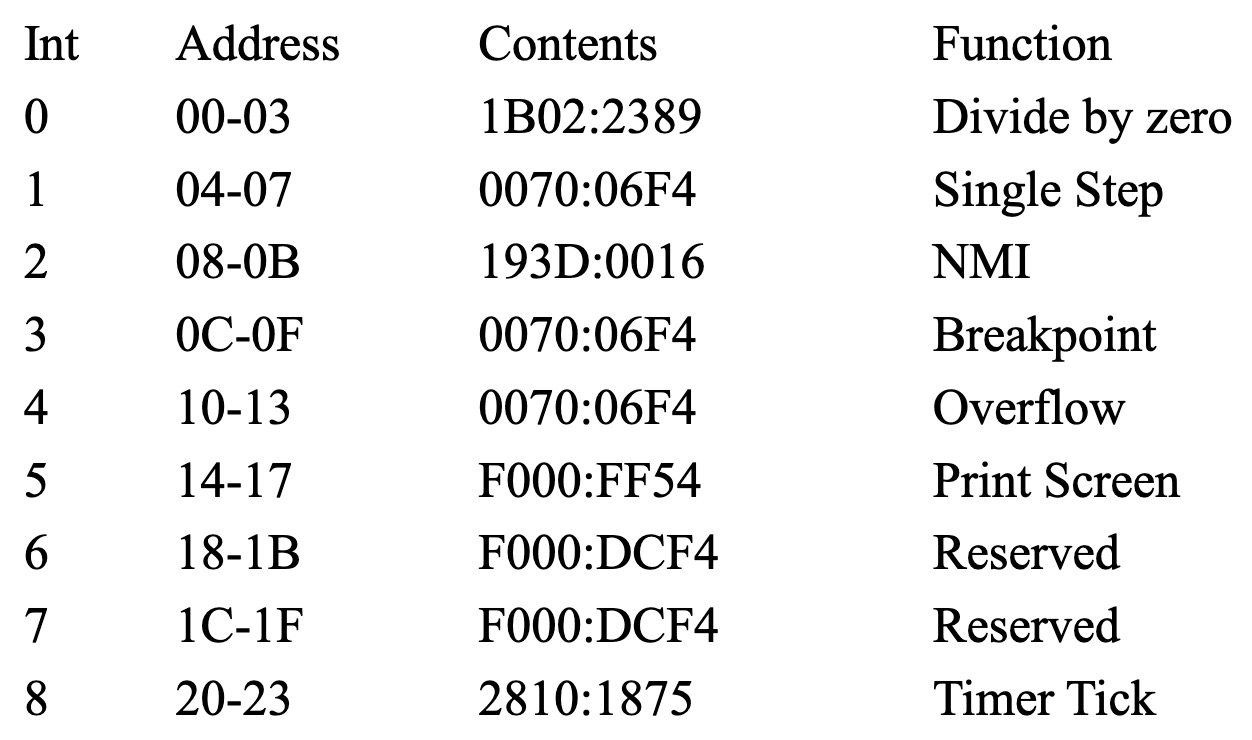
重写中断向量表的例子
; 保存原INT 8h中断向量
cli ; 禁用中断
xor ax, ax
mov es, ax ; ES=0000h(中断向量表段)
mov bx, 8*4 ; INT 8h向量地址(8h*4=20h)
; 保存原处理程序地址
mov ax, es:[bx]
mov old_ip, ax
mov ax, es:[bx+2]
mov old_cs, ax
; 设置新中断向量
mov ax, OFFSET isr
mov es:[bx], ax
mov ax, cs
mov es:[bx+2], ax
sti ; 重新启用中断Note
注意这里由于8086是使用小端法,偏移在低地址,段地址在高地址!
中断控制器 8259A
8259A 的功能与连接
8259A 可编程中断控制器 (Programmable Interrupt Controller, PIC) 是一种常用的硬件中断管理芯片,用于扩展 CPU 的中断处理能力,管理多个中断源,并实现中断优先级控制。
- 中断请求处理:当外部设备 的 IRQ (Interrupt Request) 线被触发 (发出中断请求信号) 时,8259A 会接收 这些中断请求,进行优先级仲裁,并将最高优先级的中断请求 转发给 CPU。
- 中断号传输:中断编号 会通过 PC 总线 传输给 CPU,作为中断向量索引。
- 中断向量表查找:CPU 接收到中断号后,会在 中断向量表 (IVT) 中查找 对应的 中断服务例程 (ISR) 入口地址。
- 跳转执行 ISR:CPU 跳转到 ISR 入口地址,开始执行 中断处理程序。
8259A 级联结构
在 IBM PC 架构中,通常使用 两个 8259A 芯片 级联 构成中断系统,以支持更多的中断源。
- 主芯片 (8259A #1):
- 负责处理 IRQ0 ~ IRQ7 共 8 个 中断请求。
- 基地址 通常设置为 20H。
- 从芯片 (8259A #2):
- 负责处理 IRQ8 ~ IRQ15 共 8 个 中断请求。
- 基地址 通常设置为 A0H。
- 级联连接:从芯片 通过 IRQ2 引脚 连接到 主芯片 (8259A #1) 的 IRQ2 输入,实现级联。
8259A 中断系统连接示意图
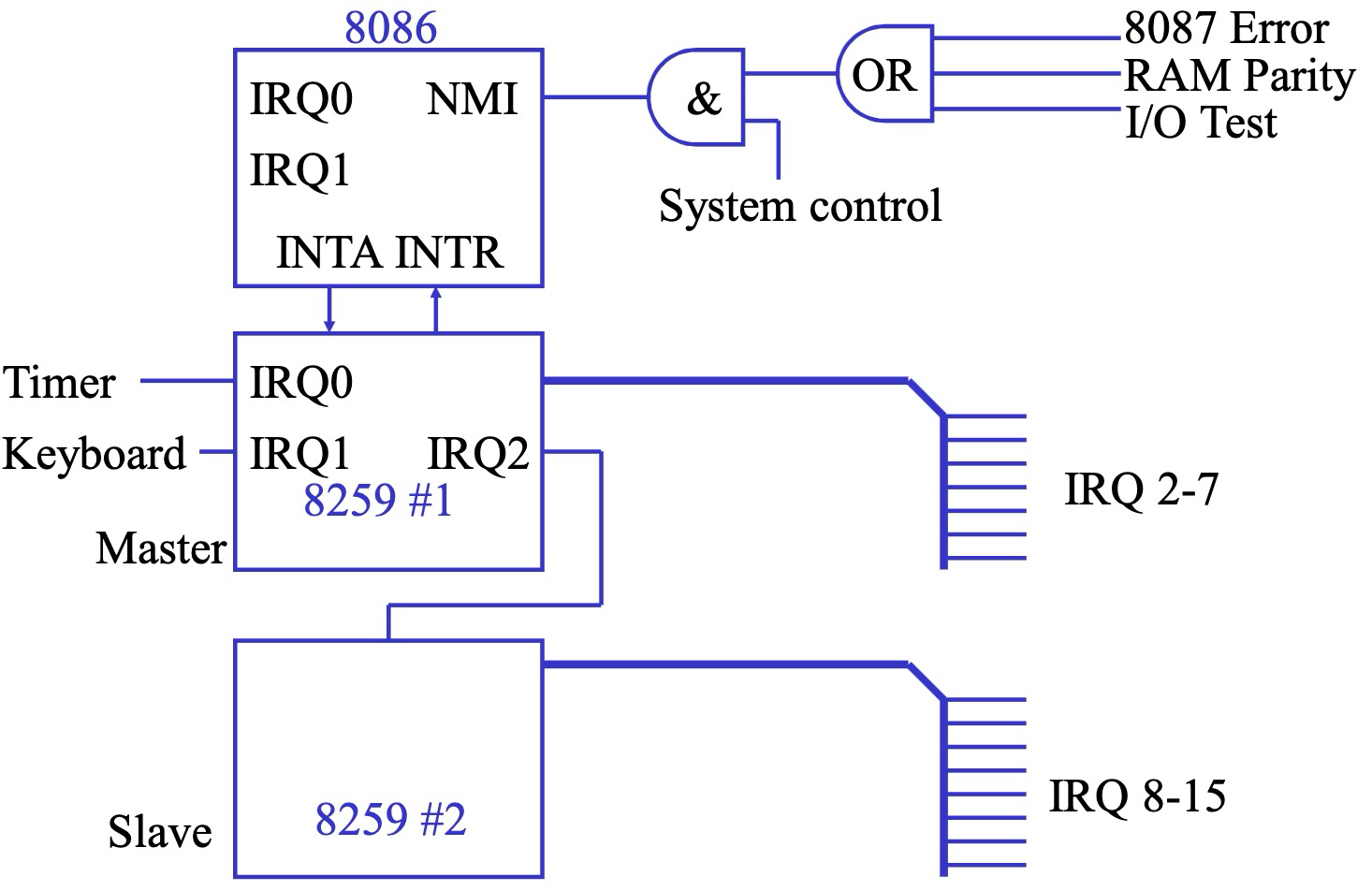
IRQ 与中断向量的映射关系
8259A 将 硬件中断请求 (IRQ) 信号 映射 到 中断向量 (INT) 号,从而与 中断向量表 (IVT) 关联起来。
- 8259A #1 (主芯片) 的映射:
- IRQ0 映射到 INT 08H (中断向量号 0x08)
- IRQ1 映射到 INT 09H (中断向量号 0x09)
- ...
- IRQ7 映射到 INT 0FH (中断向量号 0x0F)
- 8259A #2 (从芯片) 的映射:
- IRQ8 映射到 INT 70H (中断向量号 0x70)
- IRQ9 映射到 INT 71H (中断向量号 0x71)
- ...
- IRQ15 映射到 INT 77H (中断向量号 0x77)
IRQ 与中断向量映射表
| IRQ | 中断向量 (十六进制) | 描述 |
|---|---|---|
| 0 | 0x08 | 定时器节拍 (Timer Tick) |
| 1 | 0x09 | 键盘 (Keyboard) |
| 2 | 0x0A | 辅助 8259A (Second 8259A) |
| 3 | 0x0B | COM2 (串行端口 2) |
| 4 | 0x0C | COM1 (串行端口 1) |
| 5 | 0x0D | 声卡 / LPT2 |
| 6 | 0x0E | 软盘驱动器控制器 |
| 7 | 0x0F | LPT1 (并行端口) |
| 8 | 0x70 | 实时时钟 (RTC) |
| 9 | 0x71 | 可用 (传统: IRQ2) |
| 10 | 0x72 | 可用 |
| 11 | 0x73 | 可用 |
| 12 | 0x74 | PS/2 鼠标 |
| 13 | 0x75 | 数学协处理器 |
| 14 | 0x76 | 主 IDE 控制器 |
| 15 | 0x77 | 辅助 IDE 控制器 |
Note
中断向量 INT 0-7 不由 8259A 控制,而是直接 由 CPU 硬件 或 BIOS 预留和使用,通常用于处理 CPU 异常 和 早期的硬件中断,例如:
- INT 0: 除法错误异常
- INT 1: 单步中断 (调试)
- INT 2: NMI (非可屏蔽中断)
- INT 3: 断点中断
- INT 4: 溢出中断
CPU 中断处理流程详解
CPU 处理硬件中断请求的详细步骤:
-
中断触发 (Interrupt Trigger):
- 外部设备 或 内部异常 产生中断请求 (IRQ)。
- 中断信号 通过 中断线 发送到 CPU 或 中断控制器 (如 8259A)。
-
中断响应 (Interrupt Acknowledge):
- CPU 在完成当前指令的执行后,检测 到 中断请求。
- 如果中断允许 (中断标志位 IF=1,且非屏蔽中断) ,CPU 发出 中断响应信号 (INTA, Interrupt Acknowledge)。
-
保存现场 (Save Context):
- CPU 自动将 当前程序的状态 压入堆栈 (Stack) 保存,以便在中断处理完成后恢复执行。
- 保存内容 通常包括:
- 程序计数器 (PC, Program Counter) / 指令指针 (IP, Instruction Pointer):指向下一条要执行的指令地址,用于记录中断发生时的程序执行位置。
- 标志寄存器 (FLAGS):保存 状态标志位 和 控制标志位 的值,如 进位标志 CF、零标志 ZF、中断使能标志 IF 等。
-
获取中断向量 (Get Interrupt Vector):
- CPU 从 中断控制器 (如 8259A) 读取 或 直接接收 中断号 (或称为 中断向量号)。
- 根据中断号 在 中断向量表 (IVT) 中查找 对应的 中断服务例程 (ISR) 入口地址 (代码段地址 CS 和偏移地址 IP) 。
-
跳转到 ISR (Jump to ISR):
- CPU 加载 从中断向量表读取的 ISR 入口地址 (CS:IP) 到 代码段寄存器 CS 和 指令指针寄存器 IP。
- 程序控制权 转移 到 中断服务例程 (ISR) 的起始地址,开始执行 ISR 代码。
-
执行中断处理 (Execute ISR):
- CPU 执行 中断服务例程 (ISR) 代码,完成特定设备 或 异常 的具体处理逻辑。
- ISR 代码 负责:
- 识别中断源 (如果需要)。
- 读取 或 写入 I/O 端口,与设备进行数据交换。
- 清除中断状态,复位设备 (如果需要)。
- 发送中断结束命令 (EOI) 给中断控制器 (对于 8259A 等可编程中断控制器)。
-
恢复现场 (Restore Context):
- 中断处理完成 后,ISR 代码 通常会执行
IRET(中断返回) 指令。 IRET指令 会从 堆栈 (Stack) 中 弹出 之前 保存的程序状态 (包括 FLAGS 和 CS:IP)。- CPU 寄存器 和 程序状态 恢复 到 中断发生前的状态。
- 中断处理完成 后,ISR 代码 通常会执行
-
返回原程序 (Return to Original Program):
- CPU 恢复执行 被中断的 原程序,从 断点处 (即 中断发生时 PC 指向的地址) 继续运行。
8259A 操作命令:中断屏蔽
中断屏蔽寄存器 (IMR, Interrupt Mask Register) 是 8259A 可编程中断控制器 (PIC) 的一个重要寄存器,用于控制 哪些 中断请求 (IRQ) 被允许 或 禁止 (屏蔽)。
- 端口地址:中断屏蔽寄存器 (IMR) 的端口地址通常为 21H (对于主 8259A 芯片)。
- 位屏蔽:IMR 是一个 8 位寄存器,每一位 对应一个 IRQ 输入线 (IRQ0 - IRQ7)。
- 位值为 1:屏蔽 对应的 IRQ 中断请求,即 禁止 该中断被 8259A 传递给 CPU。
- 位值为 0:允许 对应的 IRQ 中断请求,即 使能 该中断可以被 8259A 传递给 CPU。
设置中断屏蔽的汇编代码示例:
以下代码示例演示了如何通过设置 IMR 来屏蔽 IRQ 7, IRQ 3 和 IRQ 1 中断。
mov al, 137 ; 十进制 137, 十六进制 89H
; 二进制 10001001B
; 位 7, 3, 0 设置为 1,对应屏蔽 IRQ7, IRQ3, IRQ1
mov dx, 21h ; 中断屏蔽寄存器 (IMR) 的端口地址 (主 8259A)
out dx, AL ; 将屏蔽值写入 IMR 寄存器屏蔽值 137 (89H) 的二进制表示 10001001B 的含义:
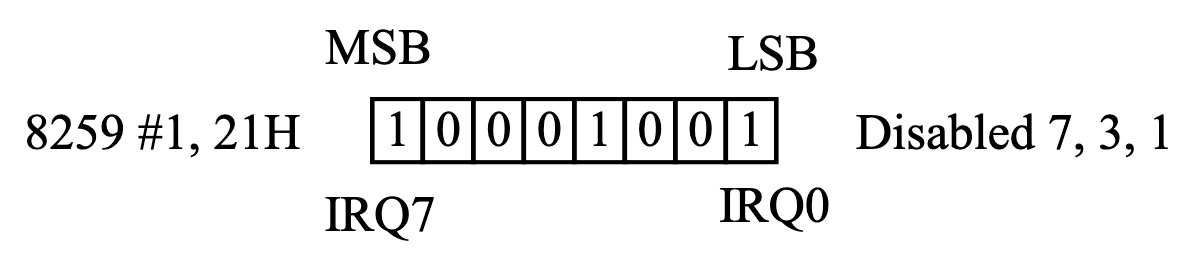
- 位 7 (最高位):设置为 1,屏蔽 IRQ7。
- 位 6 - 位 4:设置为 0,允许 IRQ6, IRQ5, IRQ4。
- 位 3:设置为 1,屏蔽 IRQ3。
- 位 2:设置为 0,允许 IRQ2。
- 位 1:设置为 1,屏蔽 IRQ1。
- 位 0 (最低位):设置为 0,允许 IRQ0。
中断结束命令 (EOI)
中断结束 (End of Interrupt, EOI) 命令是 8259A 可编程中断控制器 (PIC) 中用于通知控制器 中断处理程序 (ISR) 已经完成,可以重新接受新的中断请求 的命令。
- 非特定 EOI (Non-Specific EOI):
- 命令字:通常为 20H。
- 端口地址:命令端口 地址通常为 20H (对于主 8259A 芯片)。
- 用途:最常用的 EOI 命令。通知 8259A 当前正在处理的中断已经结束,可以清除 8259A 内部的中断请求状态,并允许处理新的中断请求。
- 优先级管理:非特定 EOI 会让 8259A 自动 将优先级最低的正在服务的中断 标记为结束。
发送非特定 EOI 命令的汇编代码示例:
EOI_command:
mov al, 20h ; EOI 命令字 (非特定 EOI)
out 20h, al ; 发送到 8259A 的主控制器命令端口 (20H)Note
何时发送 EOI 命令:
- 在中断服务例程 (ISR) 的末尾,
IRET(中断返回) 指令之前,必须发送 EOI 命令 给中断控制器。 - 目的:
- 通知 8259A 中断处理已完成。
- 重置 8259A 的内部状态,准备 接收和处理新的中断请求。
- 如果忘记发送 EOI 命令,8259A 可能无法正确响应后续的中断请求,导致系统功能异常。
自定义中断服务例程 (ISR)
自定义中断服务例程 (ISR) 是指程序员 自己编写 的 中断处理程序,用于替换 系统默认的 ISR,以实现特定的中断处理逻辑。
- 硬件驱动程序:为特定的硬件设备编写 ISR,处理设备发出的中断请求,实现设备的数据传输、控制等功能。
- 实时系统:在实时系统中,需要编写定制化的 ISR,以满足系统对中断响应时间、处理逻辑的特定需求。
- 系统功能扩展:通过自定义 ISR,可以扩展系统的功能,例如实现自定义的定时器、热键检测 等。
自定义定时器 ISR 的示例:
INT 08H (定时器中断) 是 IBM PC 架构 中由 系统定时器 周期性触发的 硬件中断,默认情况下,INT 08H 的 ISR 通常用于更新系统时间 等操作。
- 自定义 ISR 替换:程序员可以编写自己的 ISR 代码,替换 原有的 INT 08H 中断处理程序,从而实现自定义的定时器功能。
- 周期性执行:由于 INT 08H 大约每 50ms 左右 自动执行一次,因此可以利用它来实现周期性的任务,例如 计时器、实时数据采集、周期性系统监控 等。
直接访问屏幕内存 (VRAM)
直接访问屏幕内存 是一种高效的屏幕显示技术,允许程序直接 读写 视频 RAM (Video RAM, VRAM),从而快速 控制屏幕显示内容。
- DOS 文本模式:在 DOS 文本模式 下,屏幕内存 的起始地址通常为 B800:0000 (段地址 B800H,偏移地址 0000H)。
- 字符和属性存储:每个屏幕显示位置 在内存中占用 2 个字节。
- 第一个字节:存储 字符的 ASCII 码。
- 第二个字节:存储 属性字节 (Attribute Byte),用于控制字符的 颜色、闪烁 等显示属性。
- 屏幕尺寸:DOS 屏幕 通常设置为 80 列 x 25 行,总共可以显示 2000 个字符 (80 * 25 = 2000)。
- 内存占用:整个屏幕的显存空间占用 4000 字节 (2000 字符 * 2 字节/字符 = 4000 字节)。
DOS 屏幕内存组织结构

属性字节 (Attribute Byte) 结构
属性字节 (Attribute Byte) 用于控制 DOS 文本模式 下 字符的显示属性,例如 前景色、背景色、闪烁、亮度 等。
属性字节的位结构:
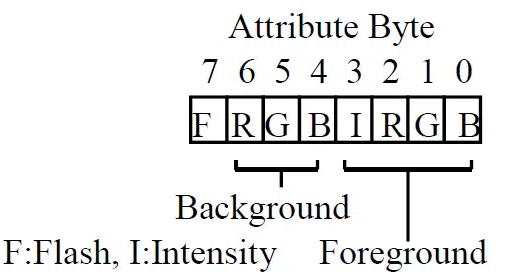
-
背景色 (Background Color):
- 位 7 (F, Flash):闪烁控制位。
- 1: 字符 闪烁。
- 0: 字符 不闪烁。
- 位 6-4 (R, G, B):背景颜色控制位。
- RGB 三位二进制编码,控制 背景颜色,可以表示 8 种颜色 (黑、蓝、绿、青、红、紫、黄、白)。
- 位 7 (F, Flash):闪烁控制位。
-
前景色 (Foreground Color):
- 位 3 (I, Intensity):亮度控制位。
- 1: 高亮度 (亮色)。
- 0: 普通亮度 (暗色)。
- 位 2-0 (R, G, B):前景色控制位。
- RGB 三位二进制编码,控制 前景色,可以表示 8 种颜色 (黑、蓝、绿、青、红、紫、黄、白)。
- 位 3 (I, Intensity):亮度控制位。
汇编代码示例:屏幕打印 "Hello, world!"
以下汇编代码示例演示了如何在 DOS 文本模式 下,直接访问屏幕内存,在屏幕上打印字符串 "Hello, world!"。
.MODEL small
.STACK
.DATA
msg db 'Hello, world!'
.CODE
start:
; 设置数据段寄存器 DS 指向数据段
mov ax, @data
mov ds, ax
; 设置附加段寄存器 ES 指向显存段 (B800h)
mov ax, 0B800h
mov es, ax
; 清空屏幕
xor dx, dx ; DX 寄存器清零,用于存储空格字符和属性
mov cx, 2000 ; 屏幕字符总数 (80列 * 25行)
xor di, di ; DI 寄存器清零,作为显存地址偏移量
clear_screen:
mov es:[di], dx ; 将空格字符和属性写入显存,清空屏幕
add di, 2 ; 显存地址偏移量增加 2 (每个字符占 2 字节)
loop clear_screen ; 循环清空整个屏幕
; 循环写入字符和属性,打印字符串 "Hello, world!"
mov cx, 13 ; 字符串长度 (13个字符)
mov di, (12 * 80 + 33) * 2
lea bx, msg ; BX 寄存器指向字符串 msg 的首地址
print_loop:
mov al, [bx] ; 从字符串中取出一个字符,放入 AL 寄存器
mov ah, 07h ; 设置属性字节为 07h (黑底白字)
mov es:[di], ax ; 将字符和属性字节写入显存
inc bx ; 字符串指针 BX 加 1,指向下一个字符
add di, 2 ; 显存地址偏移量增加 2
loop print_loop ; 循环打印整个字符串
; 等待按键按下后退出程序
wait_for_key:
mov ah, 1
int 16h ; BIOS 键盘输入中断,检测是否有按键按下 (不回显)
jz wait_for_key ; 如果没有按键按下,继续等待
mov ah, 0
int 16h ; BIOS 键盘输入中断,读取按键的 ASCII 码 (回显)
; 退出程序,返回 DOS
mov ax, 4C00h
int 21h ; DOS 程序结束中断
END驻留程序 (TSR)
驻留程序 (Terminate and Stay Resident, TSR) 是一种在 DOS 系统 中使用的特殊程序类型。
- 驻留内存:TSR 程序 在 主程序结束后,仍然可以继续驻留在内存中,不释放内存资源。
- 后台运行:TSR 程序 通常在 后台运行,监听系统事件 或 用户操作,并在特定条件触发时被激活,执行预定的功能。
- 快速调用:由于 TSR 程序常驻内存,因此可以被快速调用,无需重新加载,提高了响应速度。
TSR 程序的典型应用:
- 弹出式工具:例如 弹出式计算器、剪贴板工具。用户可以通过热键 快速激活 TSR 程序,执行计算、复制粘贴等操作,完成后程序仍然驻留在后台。
- 系统监控程序:例如 系统资源监视器、病毒扫描程序。TSR 程序可以在后台监控系统状态,并在发现异常情况时及时发出警告 或 采取措施。
- 定时任务:利用 定时器中断,TSR 程序可以周期性地执行 某些后台任务,例如 自动备份、数据同步 等。
热键检测
; 伪代码:检测热键 Ctrl+Alt+X
check_hotkey:
mov ah, 02h ; BIOS 功能号 02h:读取键盘状态
int 16h ; 调用 BIOS 键盘中断 16h,读取键盘状态字节到 AL 寄存器
and al, 00001111b ; 屏蔽 AL 寄存器高 4 位,仅保留低 4 位 (Shift, Ctrl, Alt, Scroll Lock 状态位)
cmp al, 00001100b ; 与 00001100b (Ctrl+Alt 键按下) 进行比较
jne no_hotkey ; 如果比较结果不相等 (Ctrl+Alt 未同时按下),跳转到 no_hotkey 标签
; 如果 Ctrl+Alt 键同时按下,继续检测 X 键是否按下
mov ah, 00h ; BIOS 功能号 00h:读取键盘输入
int 16h ; 调用 BIOS 键盘输入中断 16h,读取键盘扫描码和 ASCII 码
cmp al, 'x' ; 比较 AL 寄存器中的 ASCII 码是否为字符 'x' (小写 x)
je hotkey_pressed ; 如果比较结果相等 (X 键按下),跳转到 hotkey_pressed 标签
no_hotkey:
ret ; 如果热键未按下,子程序返回
hotkey_pressed:
; 在这里编写 TSR 程序的功能代码
; 例如:弹出计算器窗口、显示系统信息等
ret ; 热键处理程序返回Lecture10: MASM Code for Interrupts
一个显示在屏幕右上角的后台计时器
.MODEL small
.STACK 100h
.DATA
; 注意:TSR运行时DS可能改变,变量存储在代码段
; 以下变量通过CS段前缀访问
.CODE
.STARTUP
jmp install_tsr ; 跳过数据区
; 变量存储在代码段 (保持驻留)
dseg db '0',0 ; 当前显示字符
cntr db 0 ; 中断计数器
old_ip dw 0 ; 原中断处理程序IP
old_cs dw 0 ; 原中断处理程序CS
install_tsr:
; 保存原INT 8h中断向量
cli ; 禁用中断
xor ax, ax
mov es, ax ; ES=0000h (中断向量表段)
mov bx, 8*4 ; INT 8h向量地址 (8h*4=20h)
; 保存原处理程序地址
mov ax, es:[bx]
mov old_ip, ax
mov ax, es:[bx+2]
mov old_cs, ax
; 设置新中断向量
mov ax, OFFSET isr
mov es:[bx], ax
mov ax, cs
mov es:[bx+2], ax
sti ; 重新启用中断
; 计算驻留内存大小并终止驻留
mov dx, OFFSET tsr_end ; DX=程序结束地址
mov cl, 4
shr dx, cl ; 转换为段落 (除以16)
inc dx ; 向上取整
mov ax, 3100h ; AH=31h TSR功能,AL=返回码
int 21h
; 中断服务程序 (ISR)
isr PROC far
pushf
push di
push si
push bp
push ds
push es
; 使用CS段访问变量
mov bx, cs
mov ds, bx
; 更新计数器
inc cs:cntr
cmp cs:cntr, 18 ; 约1秒 (18.2次/秒)
jb chain_int
; 重置计数器并更新显示
mov cs:cntr, 0
inc cs:dseg
cmp cs:dseg, '9'
jbe update_screen
mov cs:dseg, '0'
update_screen:
; 直接写入显存B800h
mov ax, 0B800h
mov es, ax
mov di, (79)*2
mov al, cs:dseg
mov es:[di], al
chain_int:
; 恢复环境并链式调用原中断处理程序
pop es
pop ds
pop bp
pop si
pop di
popf
jmp cs:dword ptr old_ip ; 跳转到原处理程序
isr ENDP
tsr_end: ; 标记TSR代码结束
ENDLecture 11: 内存层次结构:动态与静态随机存储器
内存的层次结构
内存层次结构的重要性
现代计算机系统采用内存层次结构 (Memory Hierarchy) 以平衡 速度、成本 和 容量 之间的矛盾。这种结构利用了程序访问数据的局部性原理,通过多层不同特性的存储器协同工作,实现高性能的内存系统。
- 高速缓存 (Cache) -> 主存储器 (Main Memory) -> 辅助存储器 (Secondary Storage) 构成金字塔结构。
- 速度递减:从高速缓存到辅助存储器,访问速度依次降低。
- 成本递减:从高速缓存到辅助存储器,单位存储容量的成本依次降低。
- 容量递增:从高速缓存到辅助存储器,存储容量依次增大。
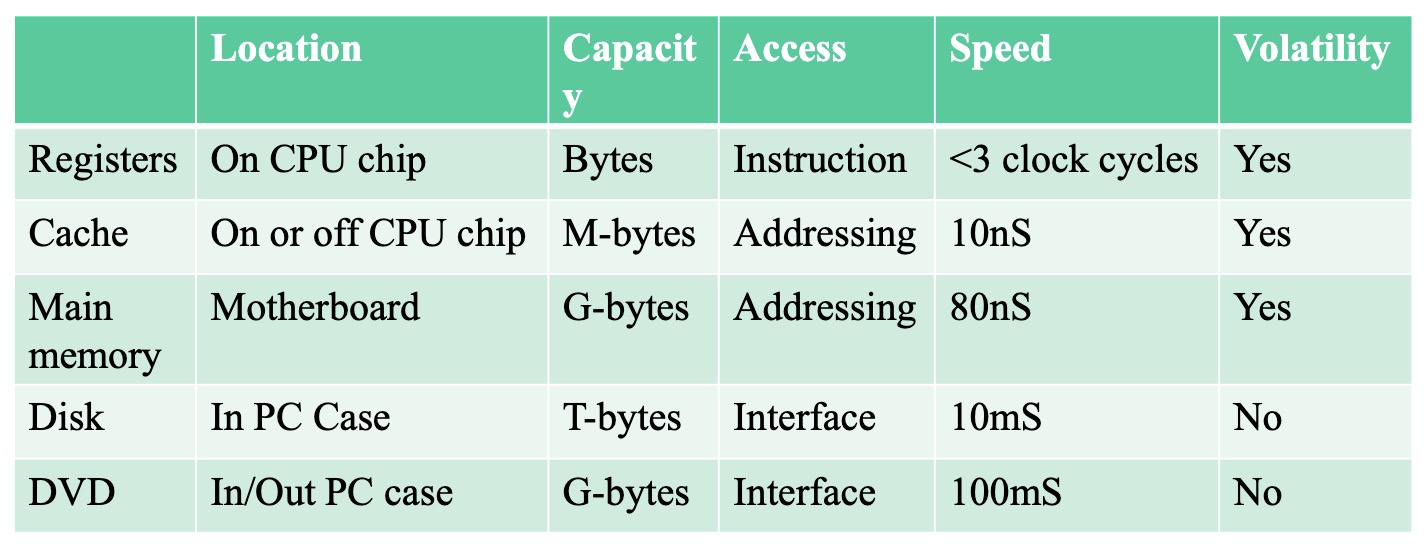
主存储器 (Main Memory)
主存的分类:DRAM 与 SRAM
主存储器 (Main Memory),也常被称为 内存 或 RAM (Random Access Memory),是计算机系统中用于 高速 存储 正在运行的程序和数据 的关键组件.主存储器主要分为两种类型: DRAM (动态随机存取存储器) 和 SRAM (静态随机存取存储器)。
静态随机存取存储器 (SRAM)
静态随机存取存储器 (Static Random Access Memory, SRAM) 是一种高速的半导体存储器,其特点包括:
- 构造原理:SRAM 基于 触发器 (Flip-Flops) 存储数据。每个存储位使用多个晶体管 (通常为 4-6 个) 构成触发器来保持数据状态。
- 单元尺寸:由于使用触发器结构,SRAM 存储单元 的 尺寸较大,集成度相对较低。
- 数据保持:SRAM 具有 易失性 (Volatile),断电后数据会丢失。但只要供电,SRAM 就能静态地保持数据,无需刷新操作。
- 访问速度:SRAM 的 访问速度非常快,远快于 DRAM,常用于构建 高速缓存 (Cache)。典型的 SRAM 访问时间 约为 10 纳秒 (10ns)。
SRAM 存储单元结构图
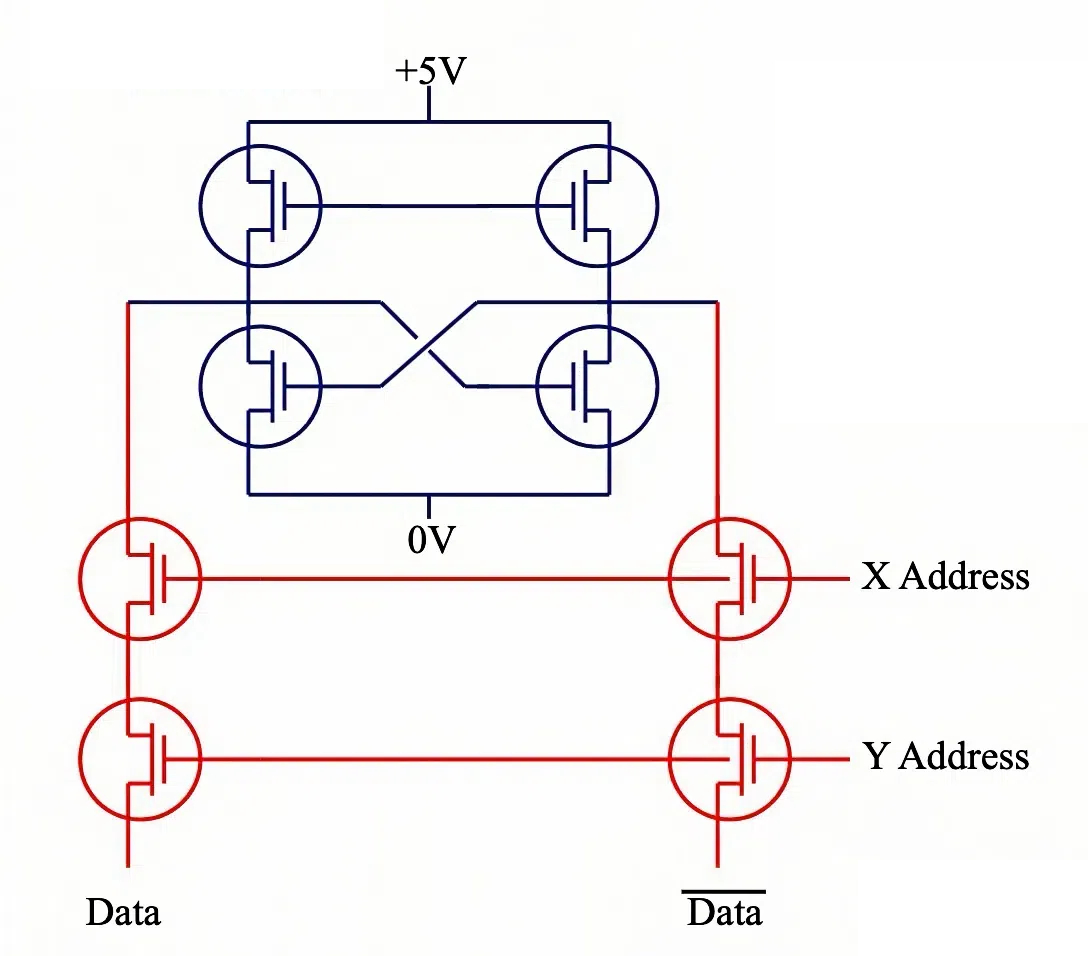
SRAM 访问方式示意图
动态随机存取存储器 (DRAM)
动态随机存取存储器 (Dynamic Random Access Memory, DRAM) 是另一种常用的半导体存储器,其特性如下:
- 构造原理:DRAM 基于 MOSFET (金属氧化物半导体场效应晶体管) 的 栅极电容 存储数据。每个存储位使用一个晶体管和一个电容组成存储单元。
- 存储密度:DRAM 存储单元 结构简单,尺寸小,可以实现 更高的存储密度 (更大的存储容量)。
- 成本:DRAM 的 制造成本较低,因此被广泛用作 主存储器。
- 数据保持与刷新:DRAM 也是 易失性 存储器。由于电容会 漏电,DRAM 存储的数据需要 定期刷新 (Refresh) 才能保持。需要 额外的刷新控制电路 来完成刷新操作。
- 访问速度:DRAM 的 访问速度相对较慢,典型的 DRAM 访问时间 约为 60 纳秒 (60ns).在非访问状态下,DRAM 不消耗能量。.了提高读取速度,DRAM 在读取操作前会对存储单元进行 预充电 (Precharge)。因.,DRAM 的速度 通常以 总周期时间 T 来衡量,约为 访问时间的两倍。
DRAM 存储单元结构图
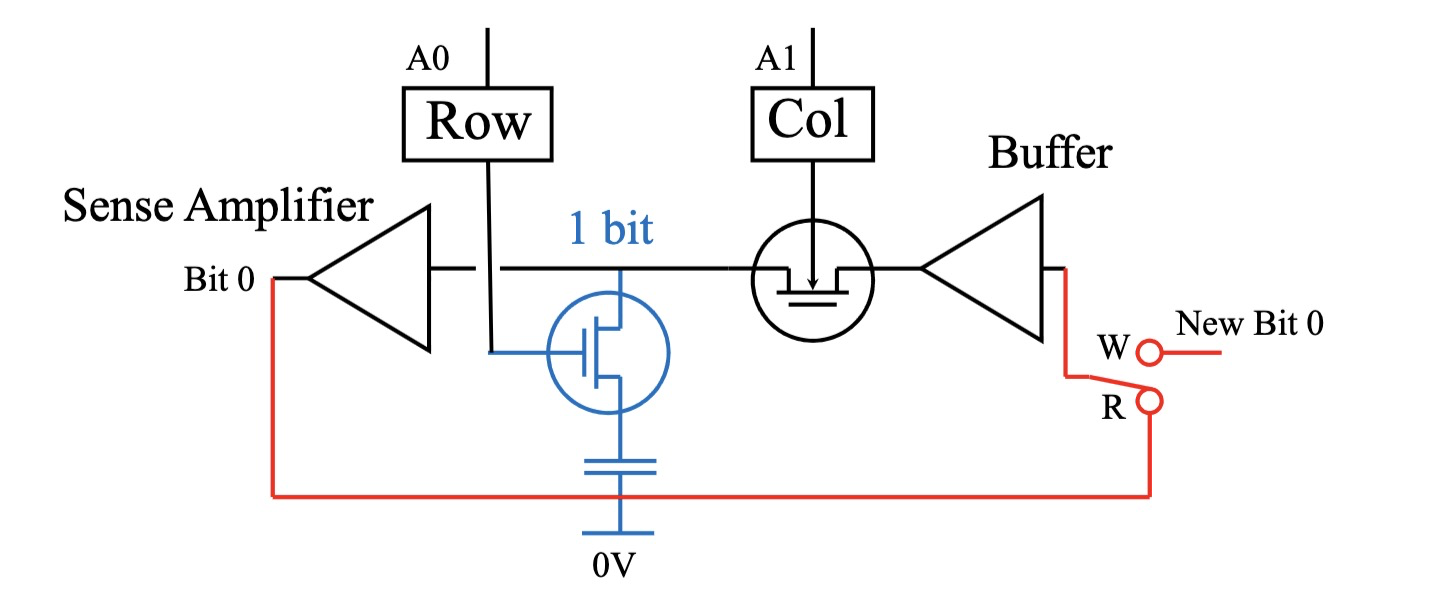
4-bit DRAM 结构示意图
DRAM 通常以 阵列形式 组织,例如 4 位 DRAM 结构.通过 激活字线 (Word Line) 来选择 存储单元行,然后通过 列选择 (Column Select) 来选择 特定的位 进行读写操作。
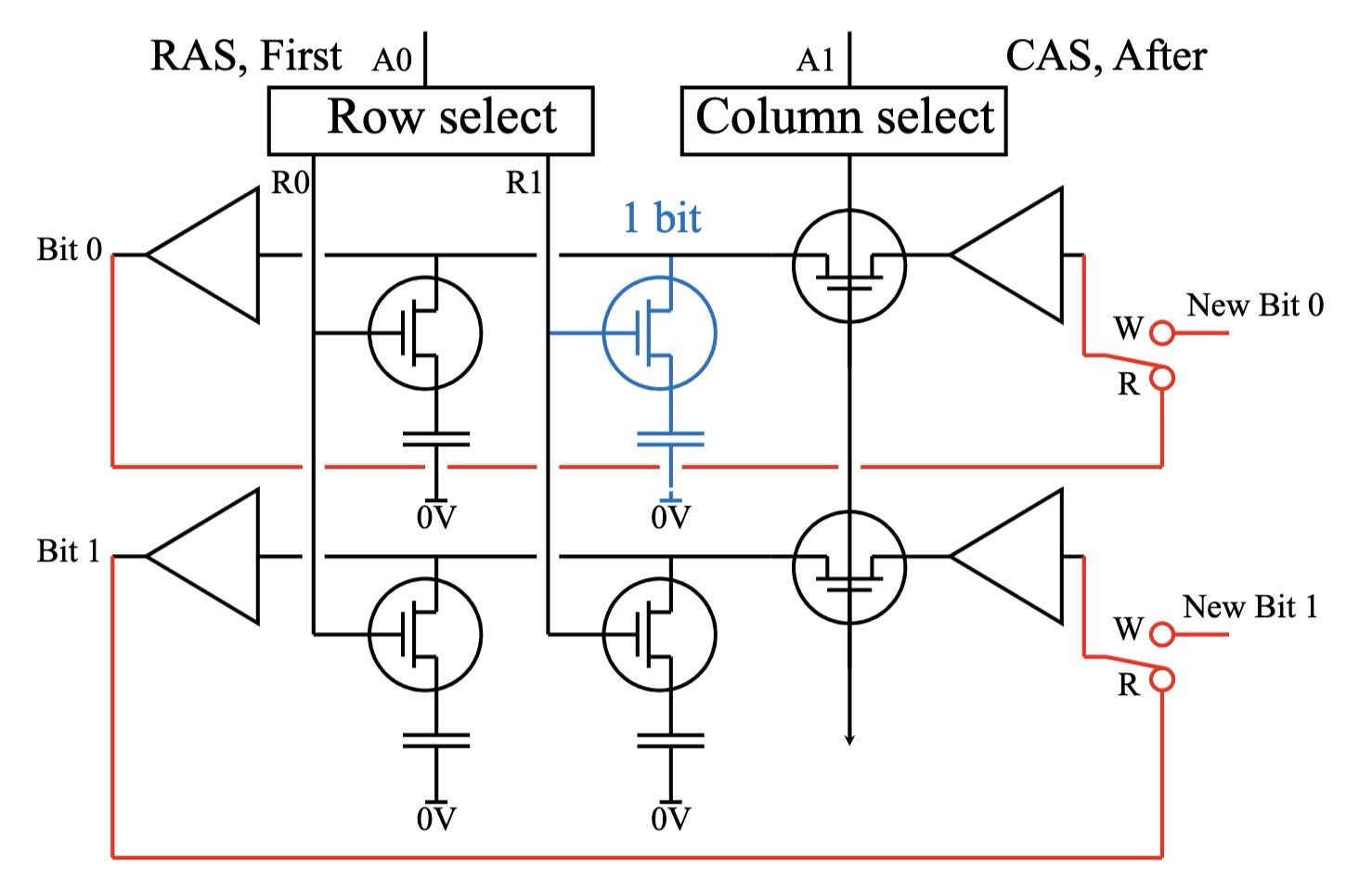
DRAM 读写与刷新周期
DRAM 的读写操作
DRAM 的读写操作 流程如下:
- 行激活 (Row Activation):通过 激活字线 (Word Line) 选择 存储单元阵列中的一行.这会将选定行中 所有存储单元的数据 读出 到 位线 (Bit Line)。
- 列选择与数据传输 (Column Select & Data Transfer): 通过 激活列线 (Column Line) 和 列选择信号 (CAS, Column Address Select), 从选定行中 选择特定的列 (即 特定的存储单元)。
- 数据写入 (Write) 或 读回 (Readback):
- 读取模式 (Read Mode):列线被激活,选定存储单元的数据被 输出。同时,读出的数据 会被 写回 (Write Back) 到 存储单元,以 保持数据。
- 写入模式 (Write Mode):列线被激活,新的数据 通过 列线 被 写入 到选定的 存储单元。
DRAM 刷新 (Refresh)
DRAM 刷新 (Refresh) 是维持 DRAM 数据完整性 的关键操作。
- 刷新必要性:由于 DRAM 使用 电容存储数据,电容上的电荷会 随时间泄漏。为了防止数据丢失,每个存储单元 必须 定期重新写入 (刷新)。
- 刷新周期:通常,DRAM 的 刷新周期 为 每 2 毫秒 (2ms) 左右。这意味着 每个存储单元 必须 每 2ms 内至少刷新一次。
- 刷新机制:DRAM 控制器 负责 自动执行刷新操作.RAS (Row Address Select) 和 CAS (Column Address Select) 信号线 被用于实现 刷新控制。.常采用 行刷新 (Row Refresh) 方式,即 每次刷新一行存储单元。
内存封装类型
常见内存封装
内存芯片 采用多种 封装形式 (Package),以适应不同的应用场景和安装需求.常见的内存封装类型包括:
- DIP (Dual In-line Package):双列直插式封装,引脚呈双行排列,穿孔安装 (Through-hole),体积较大,已较少使用。
- SIMM (Single In-line Memory Module):单列直插式内存模块,引脚呈单行排列,表面安装 (Surface-mount),体积较小,常用于早期计算机。
- DIMM (Dual In-line Memory Module):双列直插式内存模块,引脚呈双行排列,表面安装,是目前最常见的内存封装形式。
内存封装类型示意图

Lecture 12: 内存管理与缓存策略
访问局部性
在计算机科学中,引用局部性,也称为局部性原理,是指处理器在短时间内重复访问同一组内存位置的趋势。引用局部性有两种基本类型——时间局部性和空间局部性。时间局部性指的是在相对较短的时间内重复使用特定的数据和/或资源。空间局部性 (也称为数据局部性) 指的是使用相对接近的存储位置中的数据元素。顺序局部性是空间局部性的一种特殊情况,当数据元素以线性方式排列和访问时发生,例如遍历一维数组中的元素。
局部性是计算机系统中发生的一种可预测的行为。表现出强引用局部性的系统非常适合通过使用诸如缓存、内存预取以及处理器核心的高级分支预测器之类的技术来进行性能优化。
引用局部性的类型
引用局部性是指程序在执行过程中访问存储器的地址倾向于聚集在某些区域的特性。引用局部性是缓存得以有效工作的理论基础,可以分为两种主要类型:
-
时间局部性 (Temporal Locality):
- 定义:如果某个内存地址在当前时刻被访问,那么在不久的将来,该地址很可能再次被访问。
- 原理:程序倾向于重复使用最近访问过的数据和指令。例如,循环、函数调用、计数器等都会导致时间局部性。
- 缓存优化:时间局部性使得将最近访问过的数据存储在高速缓存中变得有效,以便后续快速访问。
-
空间局部性 (Spatial Locality):
- 定义:如果某个内存地址在当前时刻被访问,那么在不久的将来,其附近的内存地址也很可能被访问。
- 原理:程序在访问某个数据时,很可能会访问与其相邻的数据。例如,顺序执行的指令、数组的顺序访问、结构体或对象的成员访问等都表现出空间局部性。
- 缓存优化:空间局部性使得可以预取当前访问地址附近的数据块到缓存中,以减少未来访问的延迟。顺序局部性可以被看作是空间局部性的一种特殊情况,例如线性访问数组。

示例:
- 数据段中的数据访问倾向于展现空间局部性,因为相关数据通常存储在相邻的内存区域。
- 循环体内部的代码和数据访问倾向于展现时间局部性,因为循环会重复执行相同的指令和访问相同的数据。
缓存 (Cache)
理解计算机Cache (一) :从块到缓存结构,以及逐步推出映射策略
缓存的工作原理
**缓存 (Cache)**是一种高速、小容量的存储器,位于 **CPU (中央处理器) **和 **主存储器 (DRAM) **之间,用于缓解 CPU 与主存之间速度不匹配的问题。
-
数据复制:处理器当前正在使用的代码和数据,会从速度较慢的 **D-RAM (动态随机存取存储器) **中复制到速度更快的 **S-RAM (静态随机存取存储器) **缓存中。
例如,Intel i7 处理器的二级缓存 (L2 Cache) 为 8MB,通常搭配 8GB 的 DRAM 作为主内存。
-
缓存命中 (Cache Hit) 与缓存未命中 (Cache Miss):
当处理器发出内存地址请求时,缓存控制器 (Cache Controller) 会首先检查所需数据是否已存在于缓存中,这称为缓存查找 (Cache Lookup)。
- 缓存命中 (Cache Hit):如果数据已存在于缓存中,则称为缓存命中。数据会直接从缓存高速传输到处理器,无需访问速度较慢的主内存,从而减少了访问延迟。
- 缓存未命中 (Cache Miss):如果数据不在缓存中,则称为缓存未命中。此时,缓存控制器需要从主内存读取数据并发送给处理器 (速度较慢) 。同时,为了利用局部性原理,缓存控制器会将读取的数据的副本也存入缓存,以便后续可能的访问。
- 缓存命中率 (Hit Rate):S-RAM 缓存命中次数占总读取次数的百分比,称为缓存命中率,是衡量缓存性能的重要指标。个人电脑的缓存命中率通常可以高达 90% 甚至更高。
总结:缓存的工作原理类似于在处理器和主存之间建立一个“快速通道”,通过存储常用数据,减少了处理器访问慢速主存的次数,从而提高了程序的整体执行速度。
x86 缓存模型
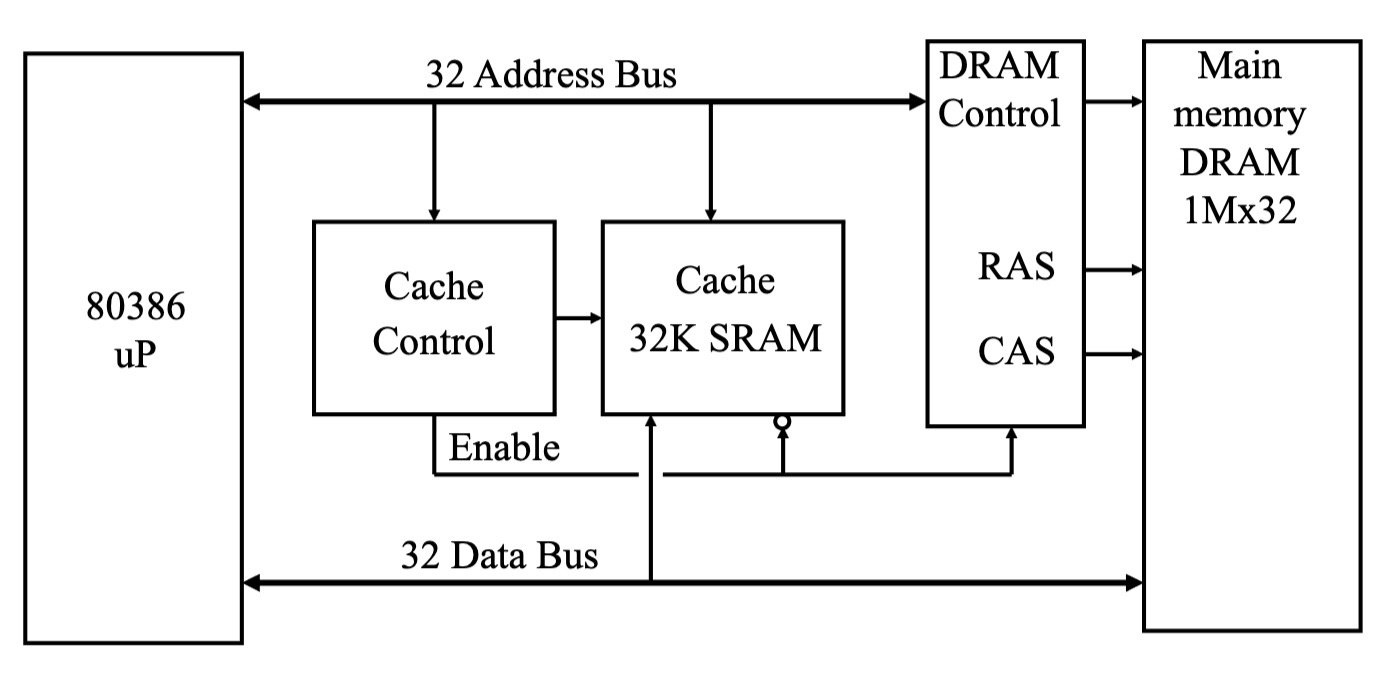
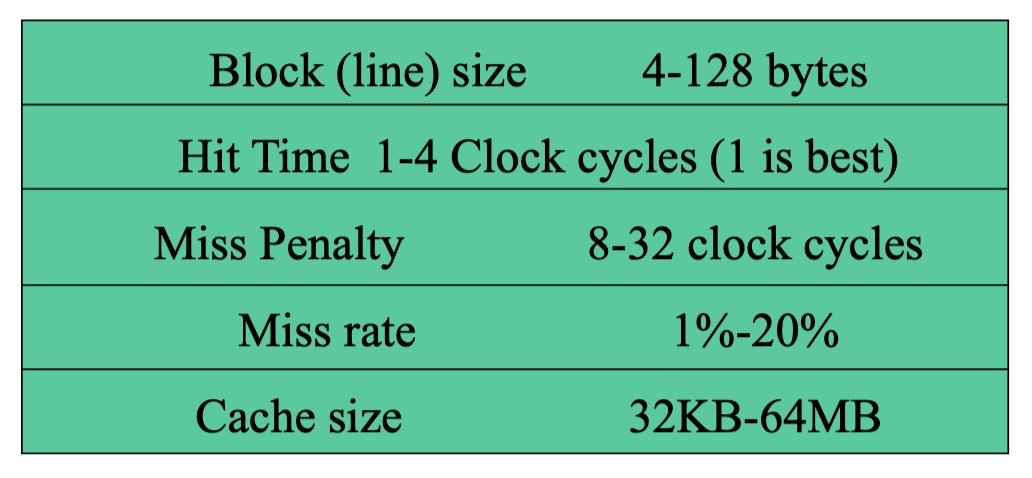
典型缓存参数
缓存组织方式
缓存控制器包含一个缓存目录 (Cache Directory),用于管理缓存中的数据。常见的缓存组织方式包括:
- 直接映射缓存 (Direct Mapped Cache):
- 单页映射:缓存被组织成只包含内存中单个页面的副本。
- 地址冲突与抖动 (Thrashing):如果处理器频繁地在不同页面之间快速切换,可能会导致抖动 (Thrashing) 现象。
- 抖动指的是缓存频繁地被新页面替换,而旧页面又很快被重新访问,导致缓存命中率极低,系统性能急剧下降。
- 直接映射缓存容易发生抖动,因为它对每个主存块的缓存位置是固定的。
- 性能影响:抖动会显著降低系统速度。
- 双路组相联缓存 (Two-Way Set Associative Cache):
- 双缓存组:使用两个独立的缓存 (或称为路 (Way)) 来存储数据。
- 页面快速切换:允许在两个缓存组之间快速切换页面,降低了抖动的可能性。
- 提高命中率:相较于直接映射缓存,组相联缓存提供了更高的灵活性,可以减少地址冲突,提高缓存命中率。
- 全相联缓存 (Fully Associative Cache):
- 任意位置存放:主存中的任何数据块可以被放置在缓存中的任何位置。
- 缓存目录查找:每个缓存条目的缓存目录需要存储完整的 DRAM 地址和关联的数据。
- 查找开销:由于需要搜索整个缓存目录来查找数据,查找速度可能较慢。
- 数据替换策略:需要复杂的数据替换策略来决定当缓存满时,如何丢弃旧数据。例如:
- 随机丢弃 (Random Discard):随机选择缓存行进行替换。
- 统一丢弃 (Uniform Discard):按照某种预定规则丢弃缓存行。
- 最近最少使用 (LRU, Least Recently Used):替换最近最少被访问的缓存行。LRU 策略的实现较为复杂,需要记录每个缓存行的访问历史。
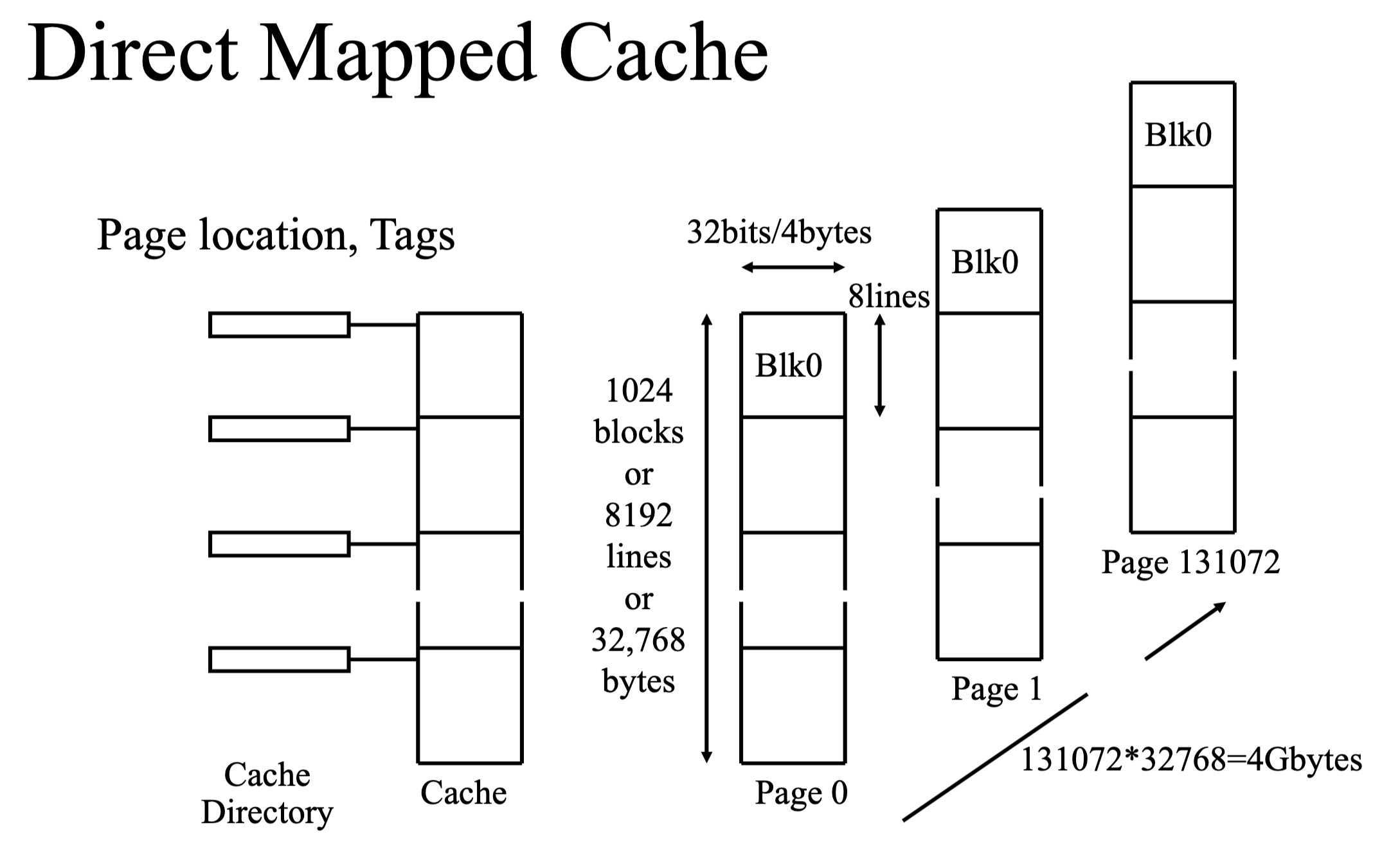
直接映射缓存 (Direct Mapped Cache)
直接映射缓存的地址映射机制如下 (以 80386 处理器为例):
- 地址总线:80386 处理器具有 32 位地址总线,可以访问 2³²=4 GBytes 的内存空间。
- 数据总线:数据总线也是 32 位宽,每 4 个字节组成一个行 (Line)。
- 缓存容量:80386 缓存包含 8196 行,总容量为 32KB (8196 行 * 4 字节/行 = 32784 字节 ≈ 32KB)。
- 缓存块 (Block):缓存将行组织成块 (Block),每 8 行组成一个块,每个块大小为 32 字节 (8 行 * 4 字节/行 = 32 字节)。
- 内存页面划分:缓存控制器将 4GB 内存空间划分为 2³²/32768=131072 个页面 (Page),每个页面大小为 32KB。
- 直接映射规则:主内存的特定行总是映射到缓存中的相同行位置。
- 缓存目录 (Tag Directory):缓存目录存储每个缓存行对应的主内存页面位置 (称为标记 (Tag)).标记用于区分缓存行中存储的数据来自主内存的哪个页面。
**内存地址分解 (虚拟地址) **
- A15-A31 (高 17 位):标记 (Tag) 位,用于设置主内存中的页面。
- A5-A14 (中间 10 位):块索引 (Block Index) 位,用于设置缓存中的块号。
- A2-A4 (低 3 位):行索引 (Line Index) 位,用于设置块内的行号。
- A0-A1 (最低 2 位):字节偏移 (Byte Offset) 位,用于选择行内的特定字节。
内存访问流程:
内存访问流程
- CPU 生成虚拟地址: CPU 在执行指令时,生成一个 32 位 (或其他位数) 的虚拟地址,用于访问内存中的数据。
- 缓存控制器接收虚拟地址: 缓存控制器拦截 CPU 发出的虚拟地址。
- 缓存查找 (使用虚拟地址) : 缓存控制器从虚拟地址中提取:
- 标记位 (Tag Bits): 用于与缓存目录中的标记进行比较。
- 块索引位 (Index Bits): 用于在缓存目录中选择对应的条目。
- 块内偏移 (Offset Bits): 用于在缓存块中选择特定的字节。
缓存控制器使用索引位在缓存目录中找到对应的条目,并将提取的标记位与该条目中的标记进行比较.同时,检查该缓存行的有效位。
- 缓存命中/未命中判断:
- 缓存命中 (Cache Hit): 如果标记匹配且有效位为真,则发生缓存命中。
- 数据读取: 缓存控制器使用偏移位从缓存块中读取对应的数据,并将数据返回给 CPU.地址转换到此为止不需要进行。
- 缓存未命中 (Cache Miss): 如果标记不匹配或有效位为假,则发生缓存未命中。
- MMU 地址转换 (仅在缓存未命中时):
- 缓存控制器将 虚拟地址 发送给 MMU。
- 物理地址生成: MMU 将虚拟地址转换为物理地址。
- 内存访问 (DRAM):
- MMU 将 物理地址 发送给内存控制器。
- 内存控制器访问 DRAM,读取所需的数据。
- 缓存更新 (在缓存未命中时):
- 缓存控制器将从 DRAM 中获取的数据存储到缓存中.这可能涉及到缓存行的替换 (Eviction),例如使用 LRU (Least Recently Used) 算法。
- 缓存控制器更新缓存目录中的标记位和有效位。
- 数据返回给 CPU: 缓存控制器将从缓存中读取的数据 (现在数据已经在缓存中了) 返回给 CPU。
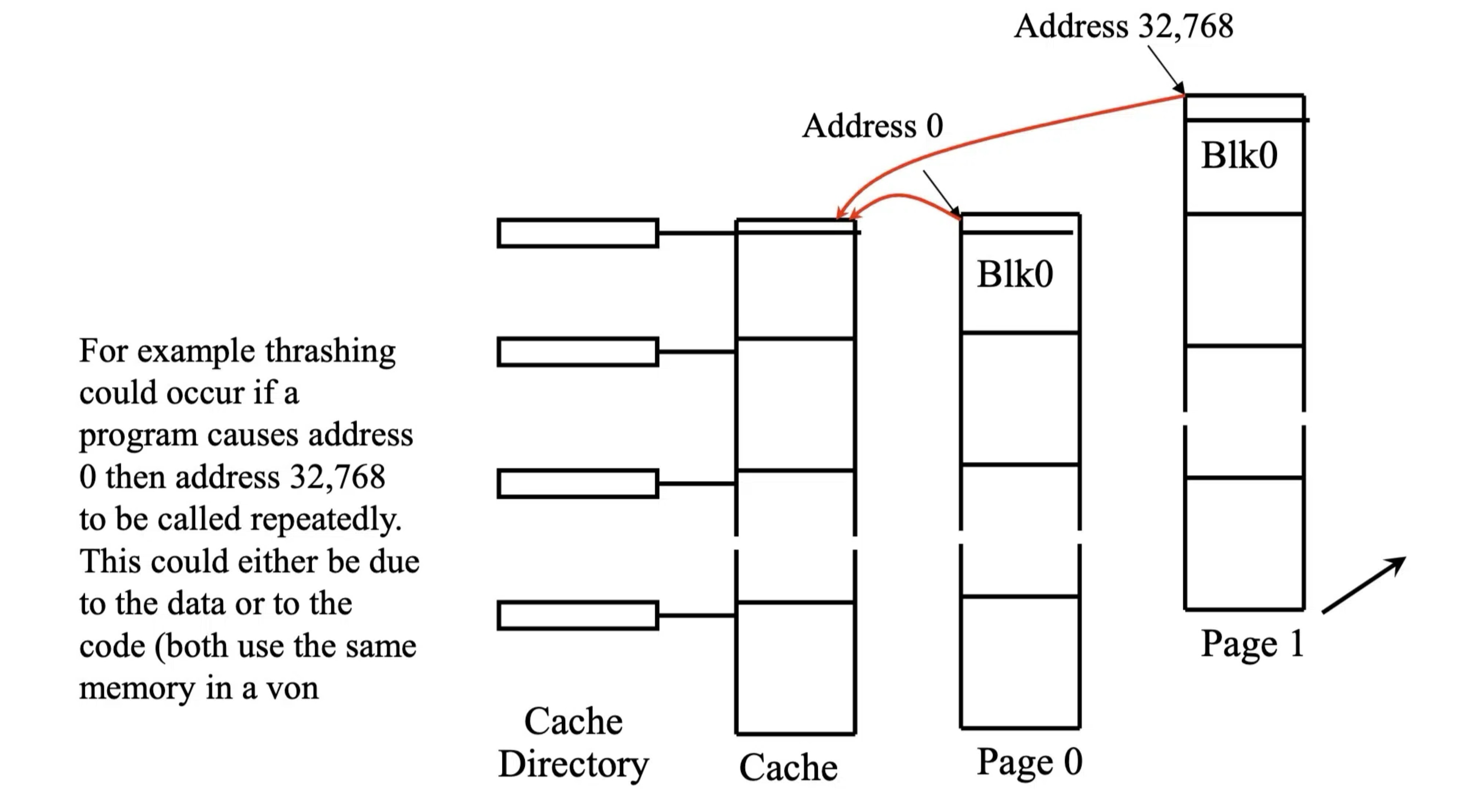
抖动 (Thrashing) 问题
**抖动 (Thrashing)**问题在直接映射缓存中尤为突出。
- 抖动场景:当程序循环重复访问内存中不同页面的相同块索引位置。
- 缓存冲突:由于直接映射缓存的映射规则,页面 0 的 X 块和页面 1 的 X 块会映射到缓存中的相同位置。
- 频繁替换:每次访问都会导致缓存未命中,需要从 DRAM 重新加载数据到缓存,并替换之前缓存的内容。
- 性能下降:导致每次内存访问都变成 DRAM 访问,缓存形同虚设,内存访问延迟增大,系统性能严重下降。
例如,如果程序反复调用地址 0 和地址 32,768,则可能发生颠簸 (thrashing) ,导致缓存命中率严重下降!!!
全相联缓存 (Fully Associative Cache)
全相联缓存提供了最大的灵活性,但实现成本和复杂度也最高。
- 任意位置映射:主存中的任何行可以被写入缓存中的任意位置。
- 缓存目录开销:缓存目录中的每个标记必须是完整的 30 位地址 (或其他位数,取决于地址空间大小) ,以唯一标识缓存行对应的主存地址。
- 查找开销大:为了查找数据,必须搜索整个缓存目录,查找时间较长。
全相联缓存的缺点:
- 查找速度慢:需要遍历整个缓存目录才能确定缓存是否命中。
- 替换策略复杂:当缓存满时,需要复杂的替换策略 (如 LRU) 来丢弃旧数据.LRU 策略的实现需要维护每个缓存行的访问历史信息,增加了硬件开销。
全相联缓存由于实现复杂,成本高昂,在 PC (个人计算机) 中不常使用 (尤其是在 1995 年左右) 。
组相联缓存 (Set Associative Cache)
组相联缓存平衡了直接映射缓存的抖动问题和全相联缓存高成本问题
- 多路缓存:将缓存分成多个组 (Set),每个组包含多个路 (Way) (例如双路组相联就是每个组包含两条路,即两个独立的缓存块) 。
- 灵活映射:主存中的一个块可以映射到组内任意一路的缓存行。
- 地址映射:内存地址被划分为标记 (Tag)、组索引 (Set Index) 和块偏移 (Block Offset) 字段.组索引用于选择缓存组,标记用于在组内区分不同的主存块。
双路组相联缓存示意图
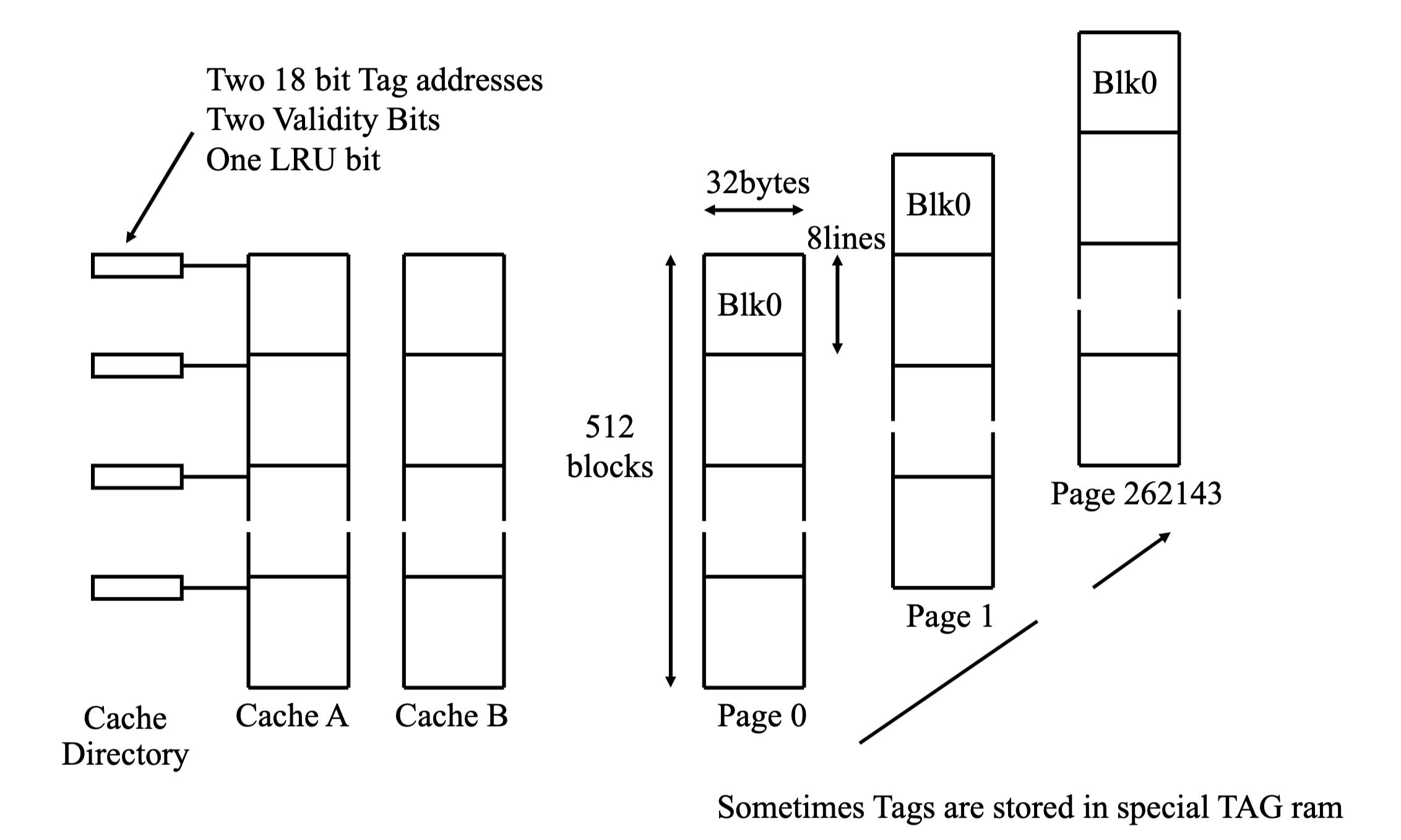
- 抖动缓解:在抖动场景中,例如程序循环访问页面 0 的 X 块和页面 1 的 X 块,双路组相联缓存可以将页面 0 的 X 块缓存到 Way 0,将页面 1 的 X 块缓存到 Way 1。
- 减少冲突:从而避免了缓存冲突,提高了缓存命中率,改善了性能。
- 替换策略:当缓存组满时,需要替换策略 (如 LRU (Least Recently Used) , 最近最少使用算法) 来决定替换哪一路的缓存行.LRU 位用于标记每个缓存路的最近使用情况,以便优先替换最近最少使用的缓存路。
缓存效率
缓存虽然在空间容量上远小于内存,但它比内存快得多,在程序执行速度上起着至关重要的作用。由于缓存的容量有限,只能存储一小部分频繁访问的数据,因此当 CPU 尝试访问的数据不在缓存中时,就会发生缓存未命中 (cache miss) ,此时 CPU 不得不从速度较慢的内存中加载所需数据。
缓存未命中的原因
- 强制性未命中 (Compulsory Miss):
- 首次访问:也称为冷启动未命中 (Cold Start Miss)。当程序第一次访问某个内存块时,该块不在缓存中,必须从 DRAM 中读取.强制性未命中是不可避免的。
- 容量未命中 (Capacity Miss):
- 缓存容量不足:如果程序频繁使用的内存块数量超过了缓存的容量,就会发生容量未命中.即使缓存已经装满了数据,但程序需要访问的数据仍然不在缓存中,需要从 DRAM 读取并替换缓存中的旧数据。
- 抖动也是容量未命中的一种表现形式。
- 冲突未命中 (Conflict Miss):
- 地址冲突:在直接映射缓存或组相联缓存中,由于地址映射的限制,不同的主存块可能映射到缓存中的相同位置 (或同一个组) .当程序频繁访问映射到相同缓存位置的不同主存块时,就会发生冲突未命中。
缓存的效果评估:Amdahl 定律
**Amdahl 定律 (Amdahl's Law)**用于评估通过改进系统资源 (例如使用缓存) 所能获得的性能提升。
Amdahl 定律公式:
$Speedup = \frac{1}{(1-p) + \frac{p}{s}}$
公式中:
- Speedup (加速比):使用改进资源后,系统性能提升的倍数。
- s (资源改进带来的速度提升):改进的资源 (例如缓存) 比原有资源 (例如 DRAM) 的速度提升倍数。
- p (可加速部分占比):程序执行时间中,可以受益于资源改进的部分所占的比例。
缓存性能提升示例:
假设:
- 缓存将内存访问速度提升 10 倍 (从 100ns DRAM 访问时间降低到 10ns 缓存访问时间),即 s=10。
- 典型程序的缓存命中率为 95%,即程序执行时间中有 95% 的时间受益于缓存加速,p=0.95。
计算加速比:
$Speedup = \frac{1}{(1-0.95) + \frac{0.95}{10}} = \frac{1}{0.05 + 0.095} = \frac{1}{0.145} \approx 6.89$
结论:加入缓存后,内存访问速度比仅使用 DRAM 时提高了约 6.89 倍。
有效访问时间 (EAT) 估算
**有效访问时间 (Effective Access Time, EAT)**用于综合评估包含缓存的内存系统的平均访问性能。
EAT 计算公式:
$\text{EAT} = (1 - \text{命中率}) \times \text{缓存访问时间} + \text{命中率} \times (\text{缓存访问时间} + \text{未命中惩罚})$
EAT 估算示例:
假设:
- 缓存访问时间:10 纳秒 (ns)。
- 缓存未命中率:5% (命中率 95%),即 p=0.95,未命中率 1-p=0.05。
- DRAM 访问时间:100 纳秒 (ns)。
计算 EAT:
$\begin{aligned} \text{EAT} &= (1 - 0.95) \times 10 \text{ns} + 0.95 \times 100 \text{ns} \ &= 0.05 \times 10 \text{ns} + 0.95 \times 100 \text{ns} \ &= 0.5 \text{ns} + 95 \text{ns} \ &\approx 14.5 \text{ns} \end{aligned}$
加速比验证:
$\text{加速比} = \frac{\text{DRAM 访问时间}}{\text{EAT}} = \frac{100 \text{ns}}{14.5 \text{ns}} \approx 6.89$
结论:内存系统的有效访问时间约为 14.5 纳秒,相较于 100 纳秒的 DRAM 访问时间,速度提升约为 6.89 倍,与 Amdahl 定律的计算结果一致。
写策略 (Write Policies)
**写策略 (Write Policies)**定义了数据写入缓存时,如何保证缓存和主内存数据一致性的策略。
-
写直通 (Write-Through):
- 同步写入:每次向缓存写入数据时,同时也将数据写入主内存。
- 数据一致性:缓存和主内存中的数据始终保持一致。
- 写操作延迟:写操作的速度受限于 DRAM 的速度,写入速度较慢。
- 读操作高速:读操作可以从高速缓存中进行,速度较快。
-
写回 (Write-Back):
- 延迟写入:数据写入操作只写入缓存,暂不写入主内存。
- 数据标记:被修改过的缓存行会被标记为“脏 (Dirty)”。
- 替换时写回:只有当脏缓存行需要被替换 (例如,缓存满时) 时,才将脏数据写回主内存。
- 写操作高速:写操作速度仅受限于缓存速度,写入速度较快。
- 读操作高速:读操作也可以从高速缓存中进行,速度较快。
- 数据一致性挑战:缓存和主内存数据在一段时间内可能不一致,数据一致性维护较为复杂.需要更复杂的机制 (例如监听 (Snooping) 或目录 (Directory) 协议) 来保证多处理器系统中缓存一致性。
- 优点:减少了对主内存的写操作次数,提高了写性能。
DMA (直接内存访问) 与缓存一致性:
**DMA (Direct Memory Access, 直接内存访问) **允许某些硬件设备 (例如 DMA 控制器) 直接读写主存储器,无需 CPU 的参与.DMA 操作可能导致缓存与主内存之间的数据不一致问题。
- 写直通缓存:写直通缓存在一定程度上可以缓解 DMA 缓存一致性问题,因为每次缓存写入都会同步更新主内存。
- 写回缓存:写回缓存需要更复杂的机制来处理 DMA 缓存一致性,例如缓存刷新 (Cache Flush) 操作,强制将脏缓存行写回主内存,以确保 DMA 设备读取到最新的数据。
多级缓存 (Multilevel Caches)
**多级缓存 (Multilevel Caches)**是现代高性能处理器中常用的缓存组织方式。
- 分级结构:采用多层缓存结构,例如 L1 缓存 (一级缓存) 、L2 缓存 (二级缓存) 、L3 缓存 (三级缓存) 等。
- 速度与容量平衡:
- **L1 缓存 (一级缓存) **:容量最小,速度最快,通常集成在 CPU 核心内部.L1 缓存追求最低的访问延迟,通常可以实现零等待状态 (Zero Wait State) 访问,即
mov ax,[bx]指令可以在最少的时钟周期内完成。.型容量为 1KB - 32KB。 - **L2 缓存 (二级缓存) **:容量比 L1 大,速度比 L1 慢,但比主存快.通常集成在 CPU 芯片上,但不一定在核心内部。.型容量为 2MB - 8MB。
- **L3 缓存 (三级缓存) **:容量最大,速度最慢 (但仍比主存快).通常多个 CPU 核心共享 L3 缓存。.型容量可以达到数 MB 到数十 MB。
- **L1 缓存 (一级缓存) **:容量最小,速度最快,通常集成在 CPU 核心内部.L1 缓存追求最低的访问延迟,通常可以实现零等待状态 (Zero Wait State) 访问,即
- 访问顺序:CPU 访问内存时,首先查找 L1 缓存,如果 L1 未命中,则查找 L2 缓存,依此类推,直到最后一级缓存或主内存。
示例参数:
- 一级缓存 (L1 Cache): 例如 1KB - 32KB,零等待状态。
- 二级缓存 (L2 Cache): 例如 2MB,500MHz 运行频率。
- 主存储器 (Main Memory): 例如最大 64GB 容量。
DMA
**DMA (Direct Memory Access, 直接内存访问) **技术允许某些硬件设备 (例如 DMA 控制器) 直接读写主存储器,无需 CPU 的参与。
- CPU 解放:DMA 技术可以解放 CPU,使 CPU 可以并行处理其他任务,提高系统整体效率。
- 高速数据传输:DMA 适用于高速数据传输的场景,例如硬盘数据读取、图形图像数据传输、音频数据传输等。
- 应用设备:DMA 常用于帧捕获卡 (Frame Grabber)、声卡 (Sound Card) 等设备。
DMA 控制器 (DMA Controller)
**DMA 控制器 (DMA Controller) **是实现 DMA 传输的关键硬件组件。
DMA 控制器结构示意图
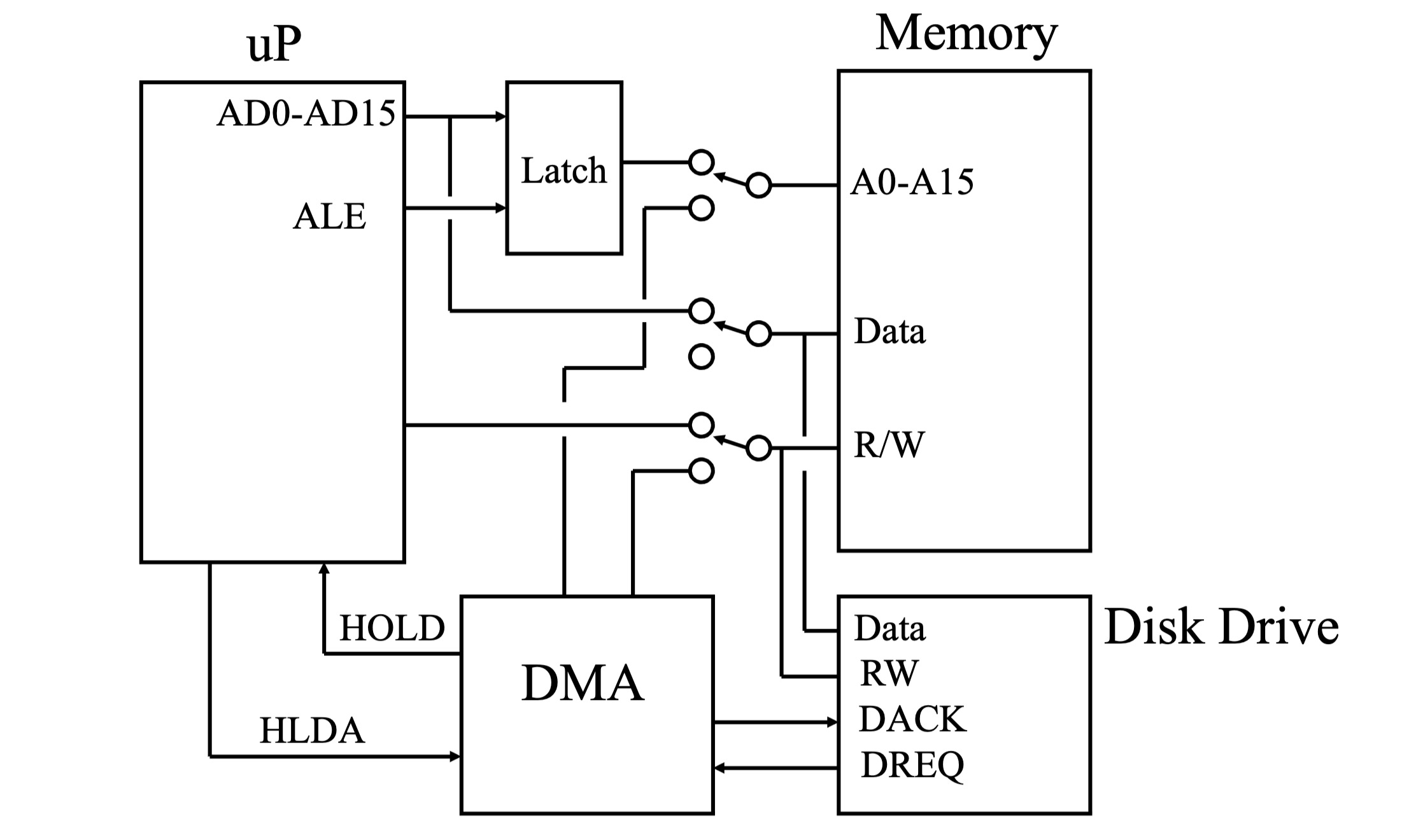
DMA 传输序列 (DMA Sequence)
DMA 控制器通过一系列握手信号与 CPU 和外围设备协同工作,完成 DMA 数据传输。
- **DMA 请求:外围设备 (例如智能磁盘控制器) 准备好数据后,设置 DREQ 信号线为高电平,请求 DMA 传输。
- **HOLD 请求:DMA 控制器接收到 DREQ 信号后,向 CPU 发送 HOLD 请求信号 (HOLD)。
- HOLD 响应:CPU 在完成当前总线周期后,释放总线控制权,并将 HLDA 信号线拉高,响应 DMA 请求。
- 总线控制权转移:DMA 控制器接管数据总线、地址总线和控制总线的控制权.CPU 暂时与内存断开连接。
- DMA 确认:DMA 控制器向外围设备发送 DMA 确认信号 (DACK),允许设备开始 DMA 传输。
- 数据传输:外围设备 (例如智能磁盘驱动器) 通过 DMA 控制器直接向主内存写入数据或从主内存读取数据。
- HOLD 释放:DMA 传输完成后,DMA 控制器释放 HOLD 请求。
- CPU 恢复总线控制:CPU 重新获得总线控制权,HLDA 信号线被拉低。
ROM (只读存储器)
**ROM (Read-Only Memory, 只读存储器) **是一种非易失性存储器,断电后数据不会丢失.ROM 通常用于存储固件 (Firmware) 和引导代码 (Boot Sequence Code),例如 BIOS (基本输入/输出系统)。
ROM 的类型
-
掩膜 ROM (Mask Programmed ROM):
- 制造时编程:程序在 ROM 芯片制造过程中被永久写入,出厂后无法更改。
- 成本高,适用于大批量生产。
-
**PROM (可编程 ROM, Programmable ROM) **:
- 一次性编程:用户可以使用 PROM 编程器写入程序一次.编程过程通常通过熔断器件内部的熔丝 (Fusible Links) 来实现。.旦编程,无法修改。
-
**EPROM (可擦除可编程 ROM, Erasable Programmable ROM) **:
- 多次编程:用户可以多次擦除和重写程序。
- 紫外线擦除:EPROM 通过紫外线 (UV Light) 照射擦除存储的数据.擦除过程需要将芯片从电路板上取下,并使用紫外线擦除器照射一段时间。
- 电荷存储:EPROM 使用 FET (场效应晶体管) 栅极上的电荷存储数据.高电压编程会在绝缘栅极上注入电荷,改变 FET 的阈值电压,从而表示不同的数据状态。
EPROM 编程与擦除原理示意图
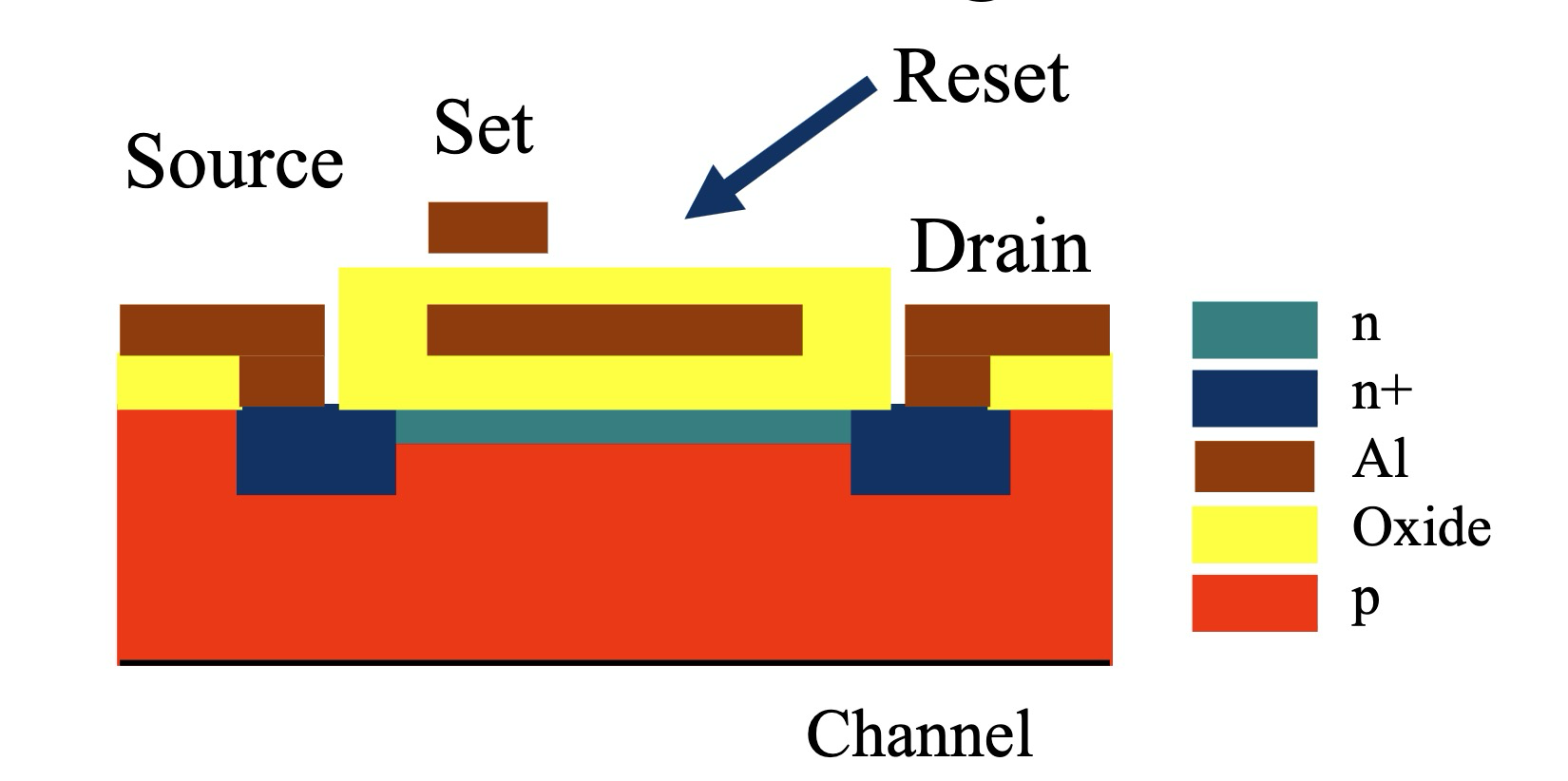
- **EEPROM (电可擦除可编程 ROM, Electrically Erasable Programmable ROM) **:
- 电可擦除和编程:EEPROM 可以通过电信号进行擦除和重写,无需紫外线照射,也无需从电路板上取下芯片。
- 字节或块擦除:EEPROM 可以按字节 (Byte) 或按块 (Block) 进行擦除,灵活性更高。
- 应用广泛:EEPROM 常用于存储 BIOS 设置、固件升级等.Flash 存储器 (闪存) 是 EEPROM 的一种发展,具有更高的擦除和写入速度,更大的存储容量。
2716 EPROM 引脚图
ROM 组合 (或与其他类型存储器组合)
ROM 芯片 (或其他类型的存储器芯片) 可以通过芯片选择 (CS, Chip Select) 信号线和多路复用器 (Demultiplexer) 组合在同一内存空间中。
- 地址解码:多路复用器根据高位地址线译码产生不同的 CS 信号。
- 芯片选择:每个 ROM 芯片的 CS 引脚连接到多路复用器的不同输出端。
- 内存扩展:通过控制 CS 信号,可以选择访问特定的 ROM 芯片,从而扩展内存空间。
ROM 组合应用示意图
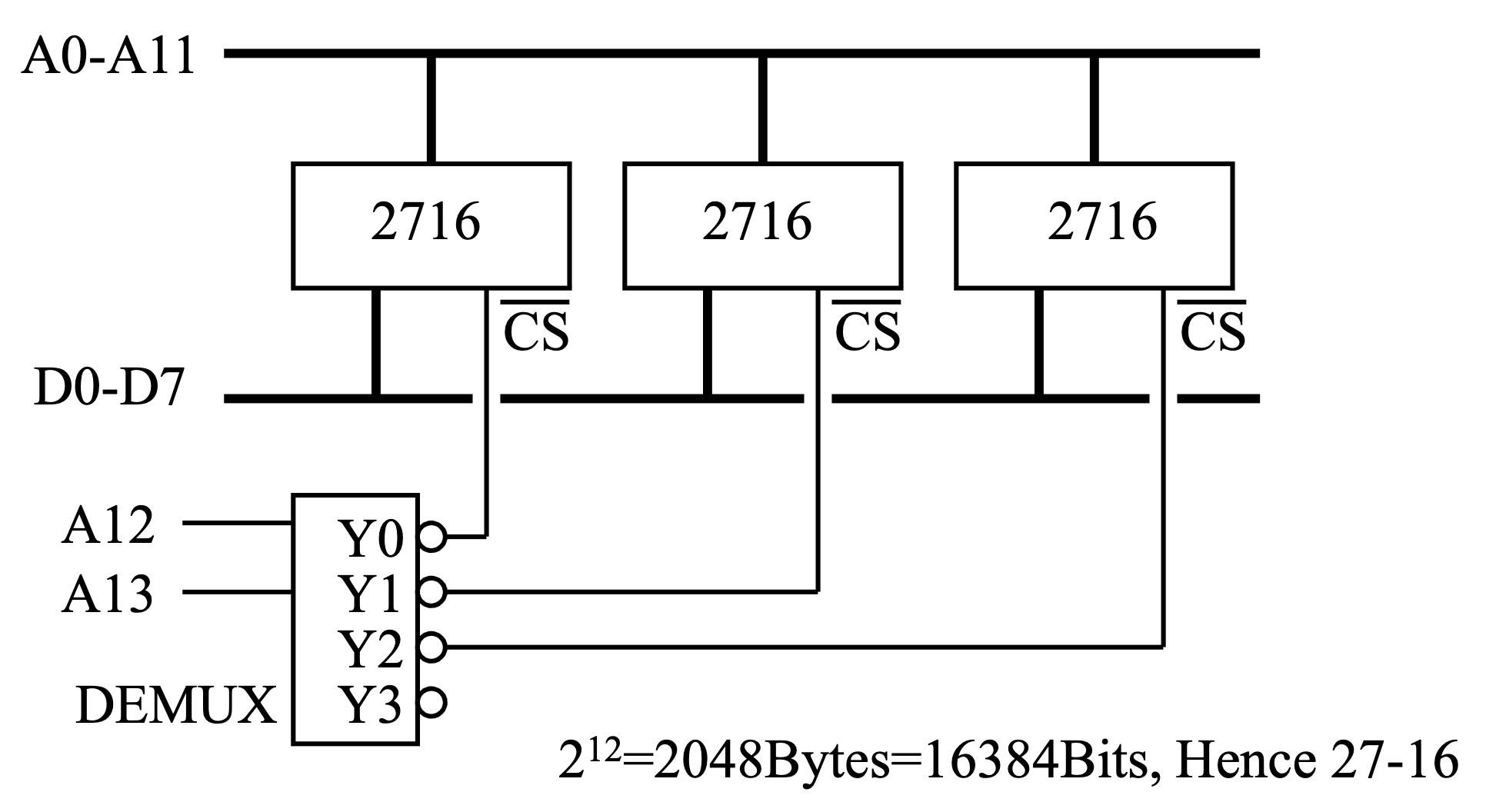
虚拟内存 (Virtual Memory)
虚拟内存的概念
**虚拟内存 (Virtual Memory)**是一种内存管理技术,将磁盘 (硬盘) 的一部分作为内存的扩展来使用,使得程序可以访问比实际物理内存更大的地址空间。
- **虚拟地址空间 (Virtual Address Space) **:CPU 寻址的地址空间称为虚拟地址空间.在典型的 PC 系统中,虚拟地址空间可以是 64GB 甚至更大。
- **物理内存 (Physical Memory) **:实际安装在计算机上的 RAM 容量称为物理内存 (或主内存) .例如 4GB RAM。
- 地址映射:虚拟内存系统负责将虚拟地址映射到物理地址.并非所有虚拟地址都映射到物理内存。
- **页面交换 (Paging) **:虚拟内存系统将虚拟地址空间和物理内存都划分成固定大小的块,称为页面 (Page).数据以页面为单位在物理内存和外部存储器 (硬盘) 之间交换。
虚拟内存的工作原理
- 外存扩展:虚拟内存系统使用外部存储器 (硬盘) 作为主内存的扩展.不常用的数据页面被换出 (Swap Out) 到硬盘上,释放物理内存空间。
- 按需调入:当 CPU 需要访问不在物理内存中的数据页面 (称为缺页 fault, Page Fault) 时,操作系统负责将所需页面从硬盘调入 (Swap In) 物理内存.如果物理内存已满,则需要替换物理内存中暂时不用的页面到硬盘上,腾出空间加载新页面。
- 缓存相似性:虚拟内存的页面交换机制与缓存的工作方式类似.物理内存可以看作是硬盘数据的缓存。
虚拟内存的性能
- 性能影响:虚拟内存的性能严重依赖于页面交换的效率.如果程序频繁发生缺页 fault,导致频繁的硬盘读写操作,系统性能会大幅下降,这被称为“磁盘抖动 (Disk Thrashing)”。拟内存的未命中惩罚 (Miss Penalty) 非常高,可能高达 100,000 个 CPU 时钟周期。
- 内存不足与虚拟内存:在 Windows 等操作系统中,如果同时打开多个应用程序,容易耗尽物理内存.此时,操作系统会开始使用虚拟内存。系统性能会显著降低,运行速度变得非常缓慢。
Lecture 13 A: 磁盘与CD-ROM
机械硬盘的结构
-
盘片 (Platters):
-
这是存储数据的载体,通常由铝合金或玻璃制成,表面涂有磁性材料。
-
一个硬盘中可能包含多个盘片,增加存储容量。
-
盘片正反两面都可以用来存储数据。
-
盘片被格式化成磁道 (Tracks) 和扇区 (Sectors)。
-
-
磁头 (Heads):
-
用于读取和写入盘片上的数据。
-
每个盘片的每个面都有一个对应的磁头。
-
磁头通过电磁感应原理,改变盘片表面的磁性方向来写入数据,或者感应磁性方向来读取数据。
-
磁头悬浮在盘片表面上方极小的距离 (几纳米) ,高速旋转时不会直接接触盘片,依靠气垫效应 (air bearing) 来维持。
-
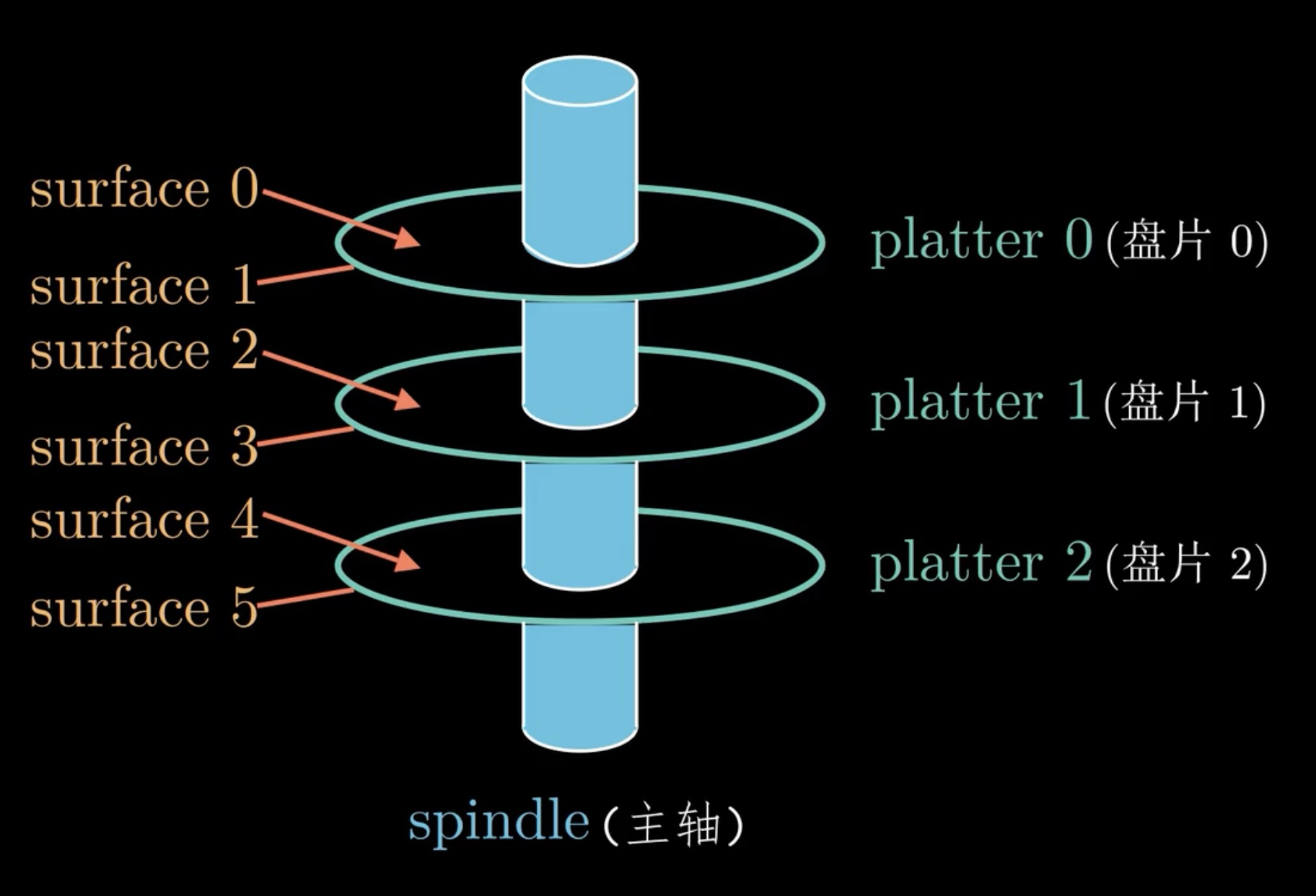
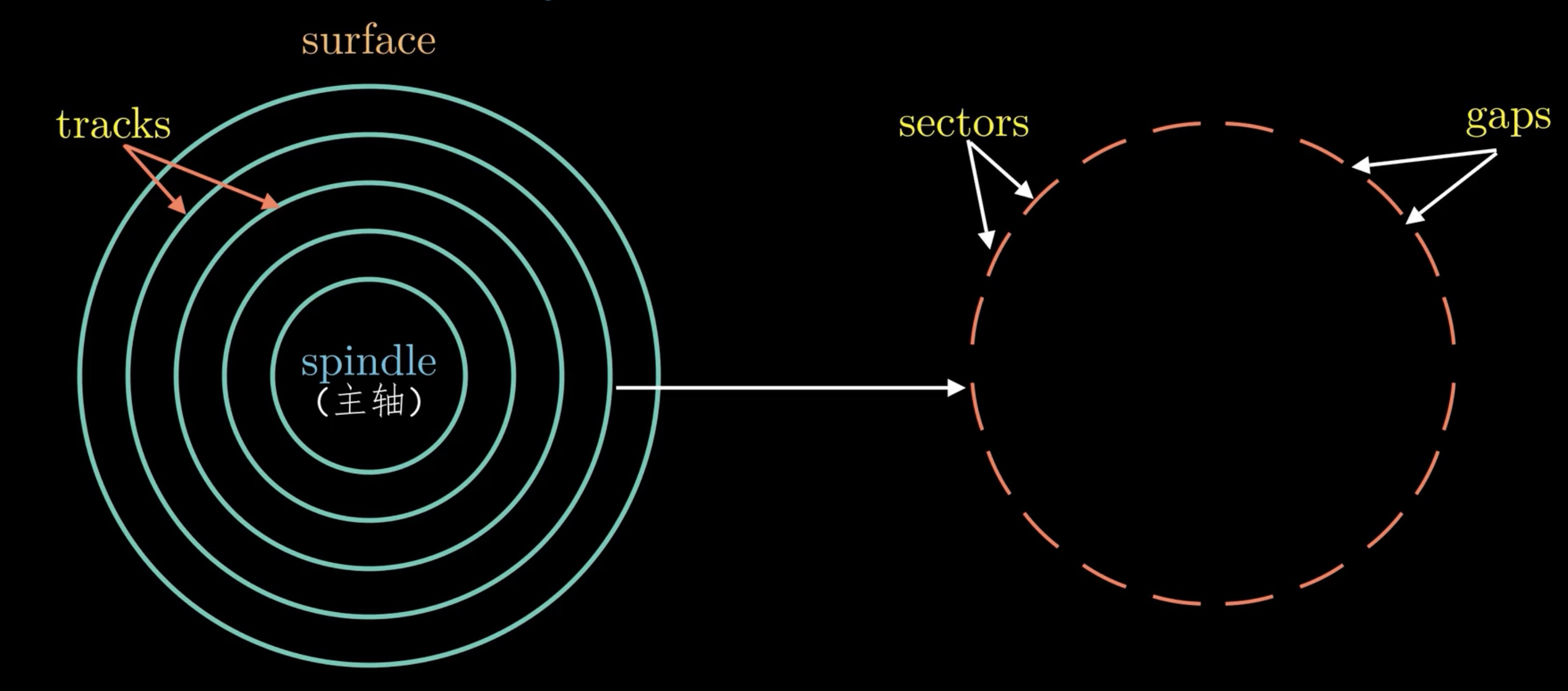
在每一个盘片上有多个磁道,每个磁道可以分为多个扇区,通常情况下,每个扇区可以存储 512 byte 的数据
编码方式
两个事实:
- 磁记录介质通过改变磁极方向 (即磁通转换) 来存储数据。 磁通转换越频繁,单位面积内能存储的信息量就越少。
- 限制连续 0 的数量可以优化磁记录过程。 长时间没有磁通转换可能会导致时钟同步困难和信号衰减。 通过控制游程长度,可以避免这些问题,并提高存储密度。
FM 编码
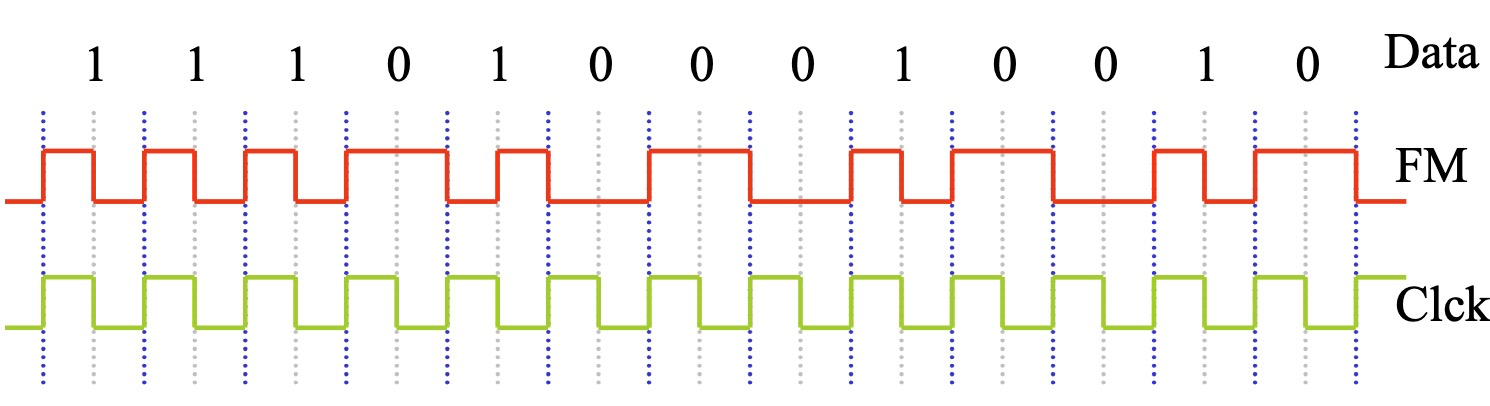
在 FM 编码中,每个位周期 (Bit Cell) 都包含一个时钟转换 (Clock Transition) ,位于位周期的起始位置。
- 0 在位周期中间没有数据转换。
- 1 在位周期中间有数据转换。
锁相环
一个能从数据信号中提取时钟信号的装置
MFM 编码
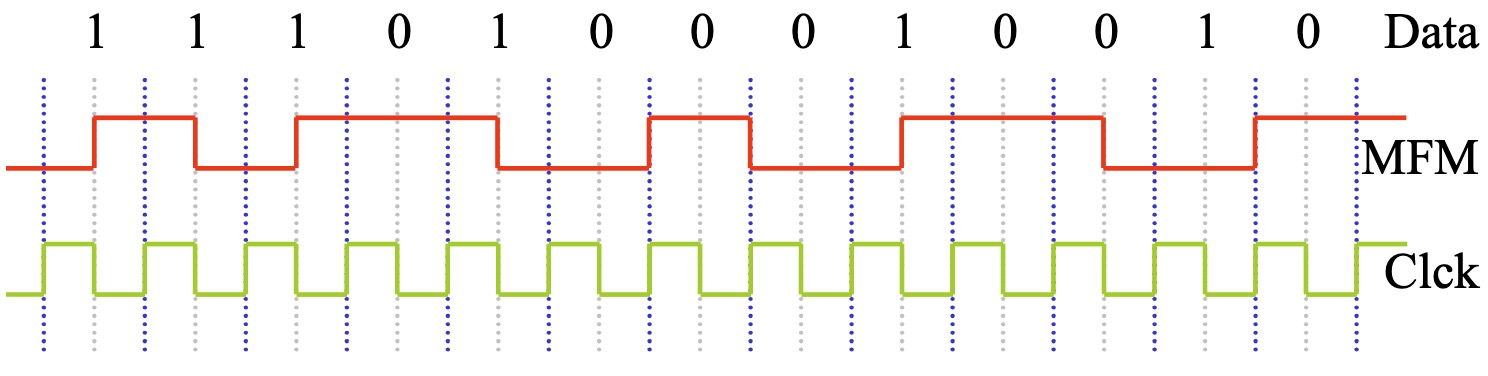
MFM 编码减少了磁通转换的次数,这意味着在单位时间内需要写入的磁通变化更少。这降低了对磁记录系统的带宽要求,并减少了因频繁转换而引起的信号失真。
-
0 如果前一位是 0,则在位周期开始处进行转换;如果前一位是 1,则不进行转换。
-
1 在位周期开始处进行转换。
RLL 编码
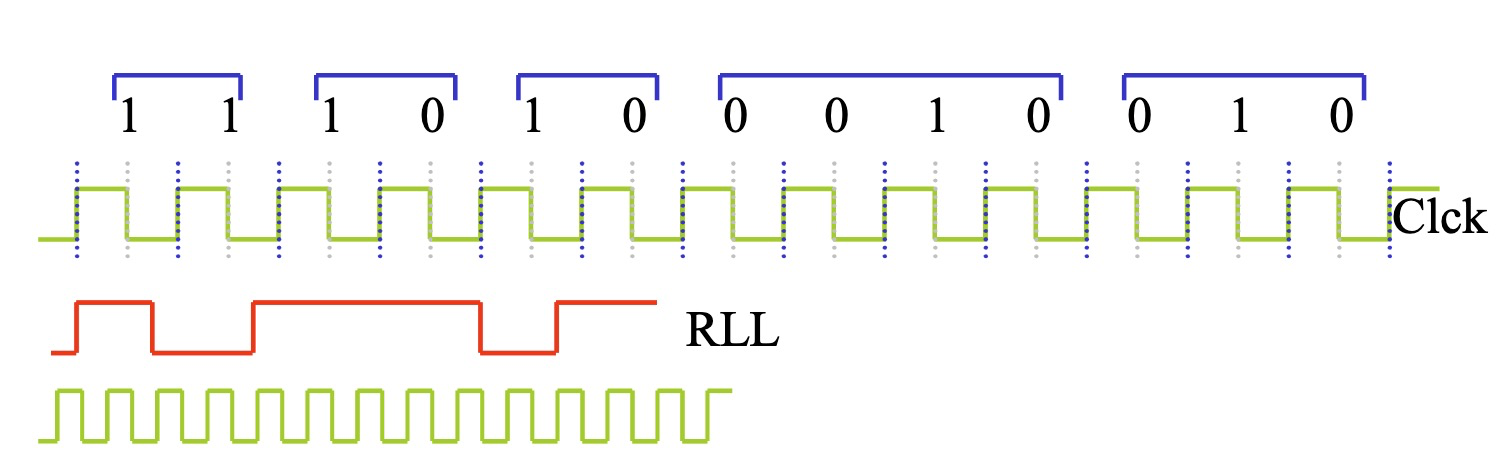
RLL 编码通过限制连续的 0 (零) 的数量来优化磁记录过程。说是比 MFM 编码好 40%
性能参数
访问时间 (Access Time): 从请求数据到接收到数据之间的时间,通常为 20 mS。
寻道时间 (Seek Time): 磁头移动到特定位置所需的时间,通常为 12 mS。
延迟时间 (Latency Time): 例如锁相环 (PLL) 等开始从磁道读取数据所需的时间,为 8 mS。
传输速率 (Transfer Rate): 从磁盘以持续速率读取数据的速率。10 Mbits/Sec (硬盘 HD),1 Mbit/sec (软盘 Floppy)。
磁道/扇区格式
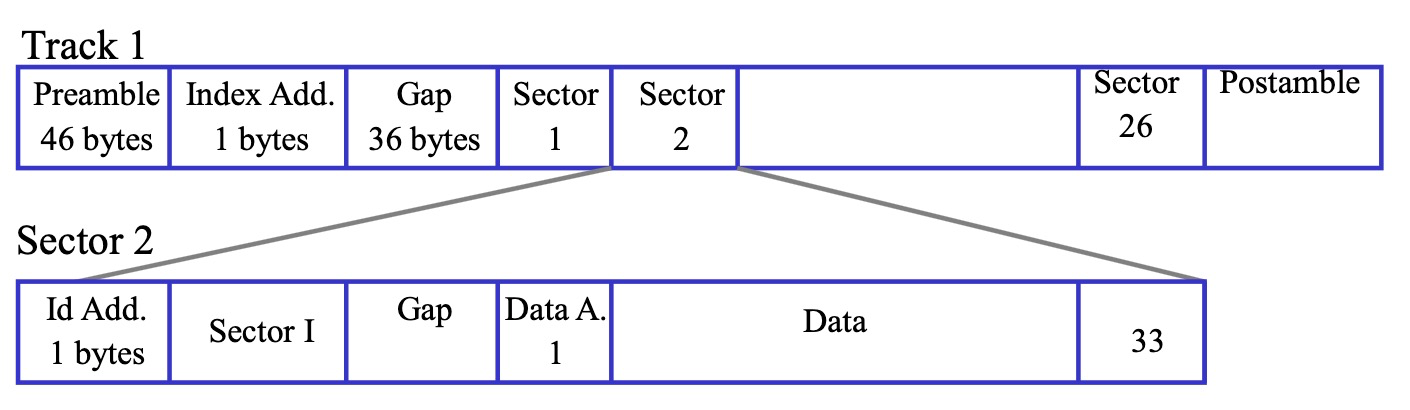
磁道,扇区上面会存储一些控制信息
磁盘控制器
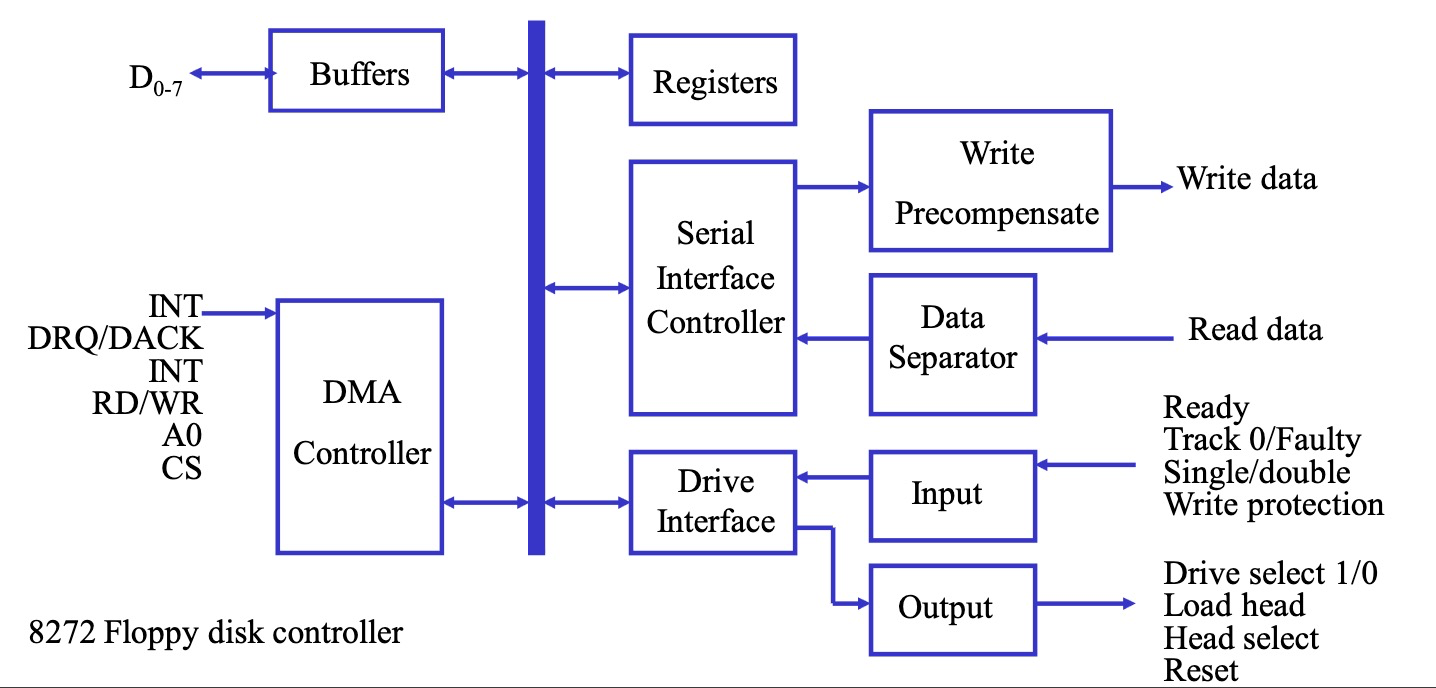
磁盘有一个自己的控制器来响应 CPU 的 I/O 操作,并且维护磁盘逻辑块号和物理磁盘扇区的关系
差错检测与纠正
最简单的就是直接记录 校验和,复杂一点就上 CRC 或者 汉明码
磁盘格式
- 磁盘引导
- 文件分配表
- 文件分配表副本
- 根目录
- 数据区
FAT/簇
FAT 是一种简单且广泛使用的文件系统,簇是 FAT 文件系统用于存储数据的最小单位。 一个簇由一个或多个连续的扇区组成。其硬盘大小限制是 2GB,簇大小限制是 32,768 bytes,至少需要一个簇来存储文件,所以假如簇很大却存了一个很小的文件,会导致浪费
FAT 32 是 FAT 16 的升级,最大支持 268435456 个簇,适用于较大的硬盘
FAT 32 有回收站机制
根目录
字节编号 (Byte Number)
- 0-7: 文件名 (Filename)
- 8-10: 扩展名 (Extension)
- 11: 文件属性 (File Attribute), 1 读取 (Read), 2 隐藏 (Hidden), 4 系统文件 (System file), ....
- 12-21: 保留 (Reserved)
- 22-23: 文件创建时间 (Time file was created)
- 24-25: 文件创建日期 (Date the file was created)
- 26-27: 起始簇号 (Starting cluster number)
- 28-31: 文件大小 (字节) (File size in bytes)
根目录标识特定文件的 FAT 中的第一个簇,FAT 的第一个簇入口将包含第二个簇的簇号。此过程会持续进行,直到链接足够的簇以包含文件大小。 (很像链表)
长这样:
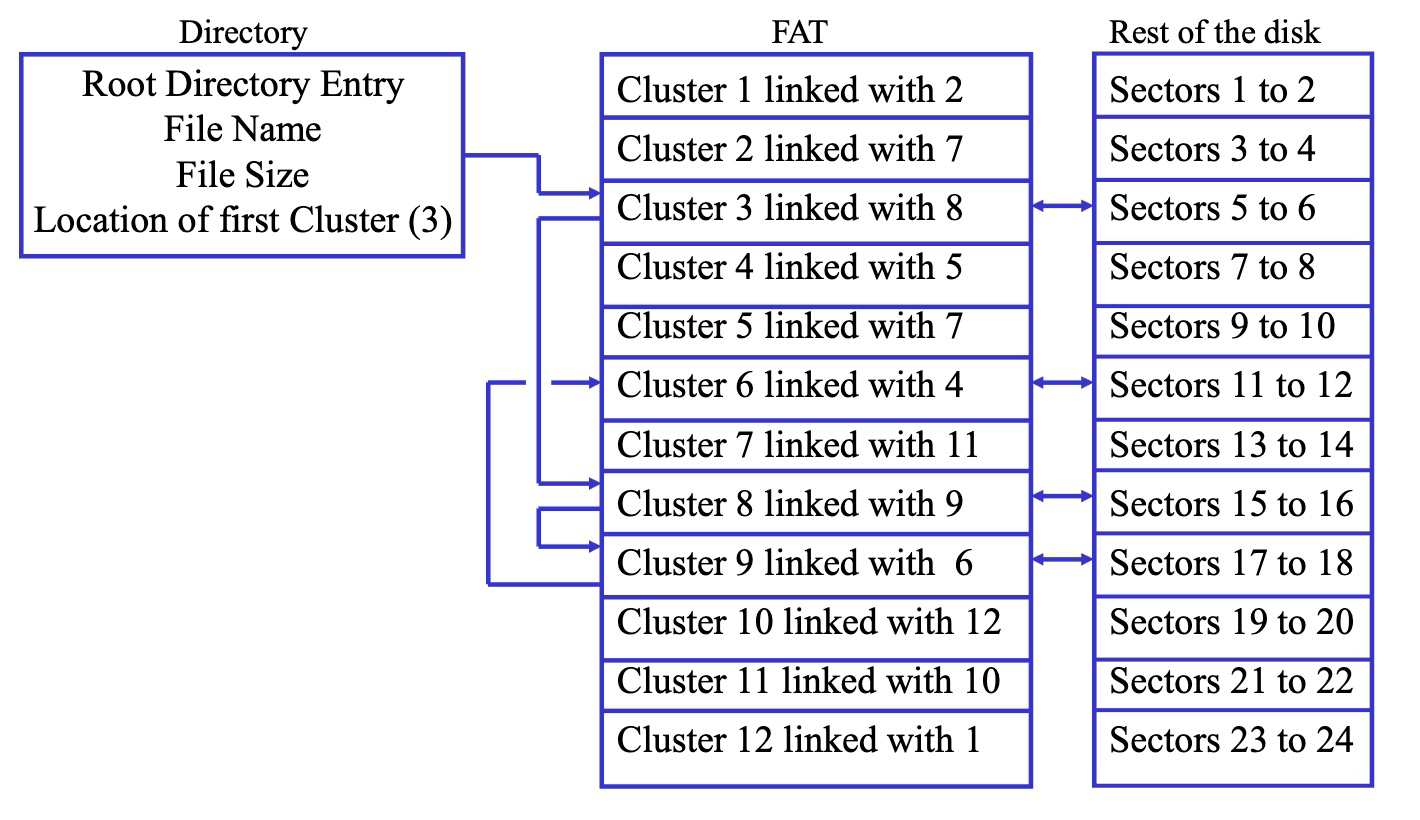
连接方式
IDE (Integrated Disk Electronics)
- 增强型 IDE (EIDE,也称为 ATA-2) 支持更大的硬盘,并允许连接四个设备,包括磁盘、磁带和 CD-ROM。
- 传统的 IDE 支持两个容量小于或等于 528MB 的硬盘。
SCSI (Small Computer Systems Interface)
- SCSI 使用 50 芯电缆,被 Macintosh 计算机、RISC 工作站、小型机甚至某些大型机使用,也可用于 PC。
- SCSI 允许将多个设备链接在一起 (
菊花链) ,且在硬盘备份到磁带机时,微处理器无需运行。SCSI 电缆需要端接 (terminating)。
RAID 磁盘阵列
- RAID Level 0: 数据条带化 (Striping) 跨越四个磁盘,提高速度,但不提供数据完整性改进 (没有冗余)。
- RAID Level 1: 磁盘镜像 (Mirroring),没有条带化,在一个磁盘上维护另一个磁盘的副本。
- RAID Level 3: 条带化,带有一个额外的专用奇偶校验磁盘 (parity disk)。 只有 20% 的磁盘用于存储冗余信息。
- RAID Level 5: 数据和奇偶校验条带化跨越 5 个磁盘。
- RAID Level 10: 数据条带化跨越两个磁盘,磁盘进行镜像。

光盘
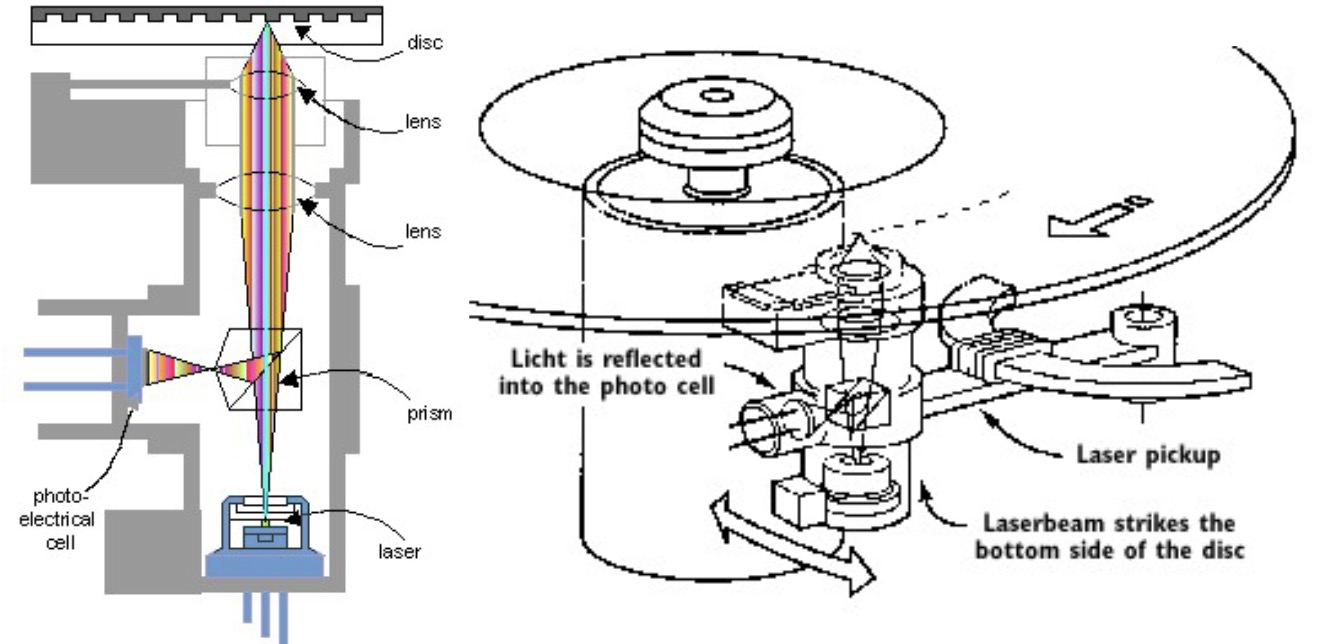
单层DVD的容量为4.7GB,CD的容量为680MB,而双面双层DVD的容量可达17GB,CD既可以通过母盘复制/压制进行批量生产,也可以使用CD-R或CD-RW技术进行单独创建。
Lecture 13 B: 硬件保护
I/O 结构
微处理器 (µP) 通过 UART (通用异步收发器) 与外部设备进行数据传输,UART 里面有一个缓冲区能加快数据传输。
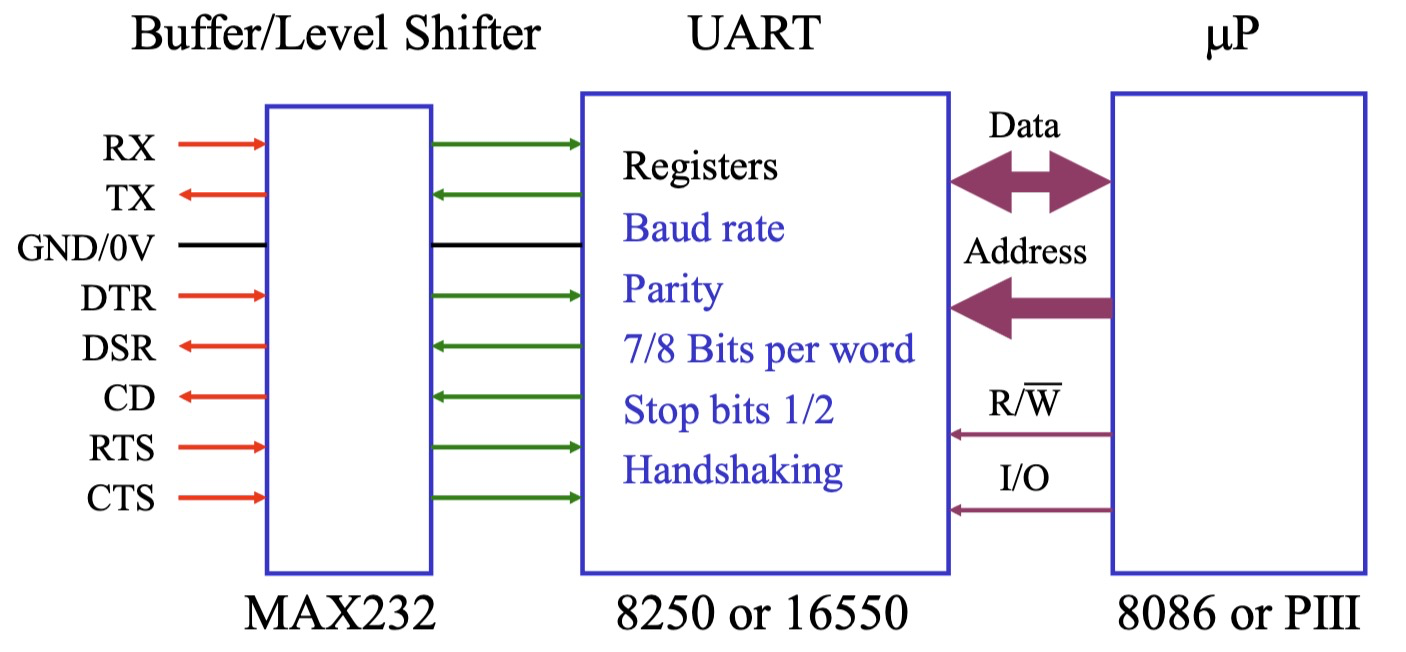
同步 I/O
在同步 I/O 中,应用程序发起 I/O 操作后,必须等待 I/O 操作完成才能继续执行后续代码。 也就是说,应用程序会被 阻塞 在 I/O 操作上,直到数据传输完成。
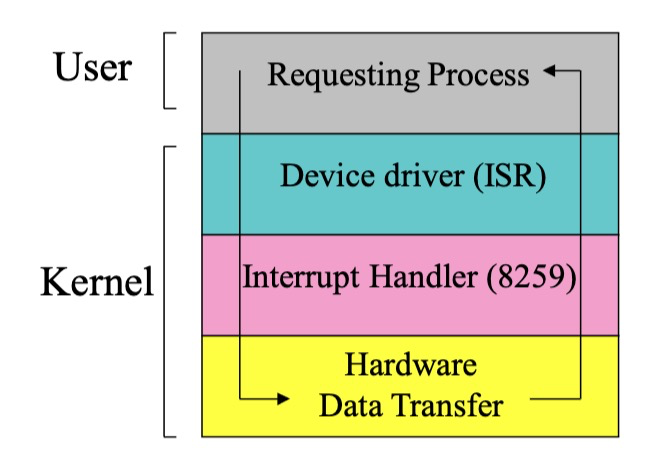
异步 I/O
在异步 I/O 中,应用程序发起 I/O 操作后, 无需等待 I/O 操作完成就可以继续执行后续代码。 操作系统或 I/O 设备会在后台执行 I/O 操作,并在操作完成后通过中断等机制通知应用程序。
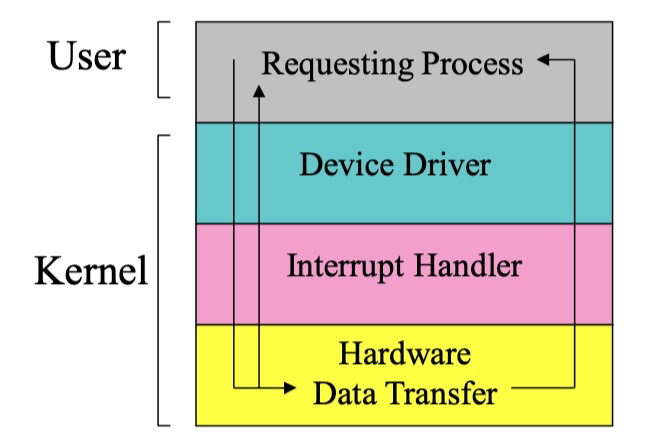
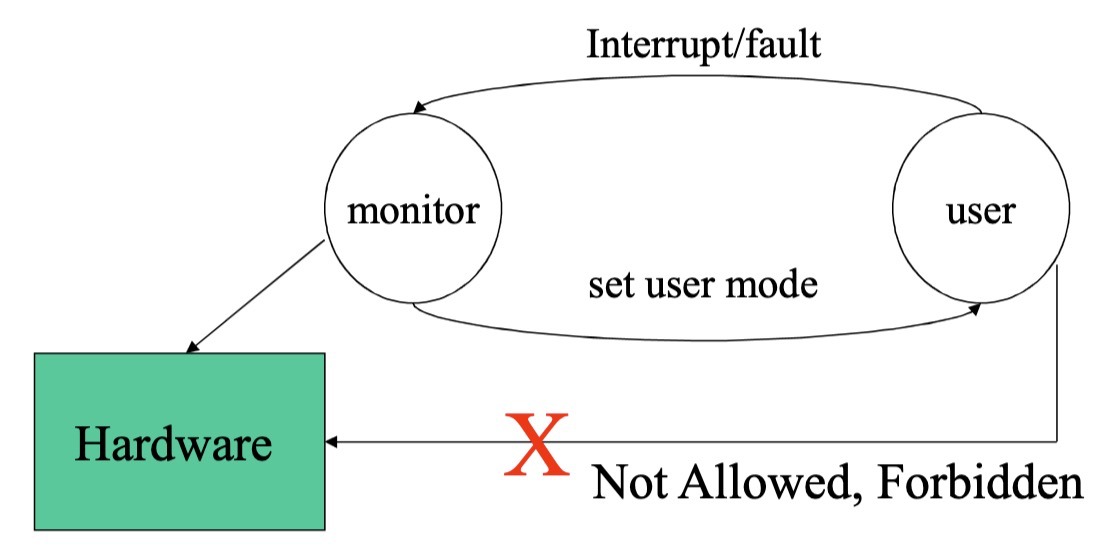
硬件保护
CPU允许两种操作模式。在寄存器中的一个位设置了CPU正在运行的模式。
- **用户模式 (User Mode): **代表用户运行的代码。
- **监控模式 (Monitor Mode): **代表操作系统运行的代码。
在用户模式下,应用不能切换到监控模式。操作系统在启动用户程序之前,会先切换到监控模式,然后创建一个新的进程或线程,并将控制权交给该进程或线程。只有在监控模式下才能使用能够危害其他程序的特权指令。因此只有通过操作系统,用户程序才能和硬件交互
内存保护
恶意程序在没有内存保护的情况下能直接修改中断向量表,造成严重的系统异常!!!
CPU 保护
操作系统理念有一个计时器,规定了一个程序最长能占用的CPU周期,防止某个进程霸占 CPU 导致系统崩溃,计时器中断触发会保存当前上下文,然后把控制权交给下一个进程
Lecture 14: CISC/RISC 向量处理器与并行处理器
RISC vs CISC
CISC (Complex Instruction Set)
核心理念:通过丰富的指令集和寻址方式,尽可能地用一条指令完成复杂的任务。
- 指令集丰富:指令数量多,包含大量复杂指令,以及多种寻址方式。
- 汇编编程友好:汇编代码编写相对容易,因为高级操作可以通过单条指令完成。
- 特定指令执行速度快:针对特定应用优化的复杂指令,执行效率高。
- 指令解码复杂:由于指令长度不一、格式多样,解码过程复杂,增加硬件开销。
- 程序体积较小:完成相同任务所需的指令数量较少,程序体积相对较小。
RISC (Reduced Instruction Set)
核心理念:简化指令集,使用少量、简单、定长的指令,并通过优化指令执行流程来提高整体性能。
- 指令集精简:指令数量少,指令格式统一,寻址方式简单。
- 指令执行效率高:绝大多数指令都可以在一个时钟周期内完成。
- 编译器要求高:生成 RISC 代码的编译器设计难度较高。
- 内存性能要求高:需要快速的内存访问,以保证指令流的持续供应。
- 性能更好:指令执行效率高,流水线优化使得并发执行成为可能。
- 通用寄存器多:依赖大量通用寄存器,减少对内存的访问,提高数据处理速度。
- 优化指令流水线:允许同时执行多条指令。
CISC 和 RISC 在追求更好性能时的策略
- CISC 的策略 是让机器指令更像高级语言,这样编译器更容易生成代码,程序也更小更快。许多 CISC 编译器实际上只使用指令集中的一部分。
- RISC 的策略是优化最常用指令的执行效率,减少内存访问,并充分利用指令流水线和寄存器。RISC 设计侧重于通过使用寄存器(可以看作是非常快的本地缓存)和优化指令的执行流程来提高速度。
CISC 和 RISC 实现乘法
RISC 实现乘法
.STARTUP
mov ax, 0 ; 初始化结果寄存器 AX 为 0
mov dx, 100 ; 乘数 100 放入 DX 寄存器
mov bx, 123 ; 被乘数 123 放入 BX 寄存器
mov cx, 8 ; 循环次数设置为 8 (假设进行 8 位乘法)
back:
rcr dx, 1 ; 将 DX 寄存器最低位循环移入 CF (进位标志位)
jnc over ; 如果 CF = 0 (最低位为 0),则跳转到 over 标签
add ax, bx ; 如果 CF = 1 (最低位为 1),则将 BX 累加到 AX (部分积)
over:
shl bx, 1 ; 将 BX 寄存器左移一位,相当于乘以 2
loop back ; 循环计数器 CX 减 1,如果 CX != 0,则跳转到 back 标签继续循环
call Print
.EXITCISC 实现乘法
.STARTUP
mov dl, 100 ; 乘数 100 放入 DL 寄存器
mov al, 123 ; 被乘数 123 放入 AL 寄存器
mul dl ; 执行乘法指令 mul,AL * DL,结果存储在 AX 寄存器
call Print
.EXIT流水线
早期 CPU 执行一条指令从出生到入土,非得霸占整个逻辑处理单元不撒手。Fetch, Decode, Execute 三兄弟明明能各干各的,非得搞什么"一条龙服务"——结果就是ALU天天摸鱼,寄存器天天加班。图灵的在天之灵振臂高呼:杂鱼 CPU 就应该狠狠的填满🥵,上流水线!
流水线执行:时间管理大师の骚操作
- 周期1:Ins.1刚扒上Fetch的窗口,CPU就开始偷瞄下一条
- 周期2:Ins.1在Decode里翻来覆去,Ins.2已经蹲在Fetch门口催单
- 周期3:Ins.1终于Execute,后面俩小弟Ins.2/3直接卡成贪吃蛇
- 周期4:Ins.1 Execute 完了,提起裤子直接跑了,轮到 Ins.2 上场接力
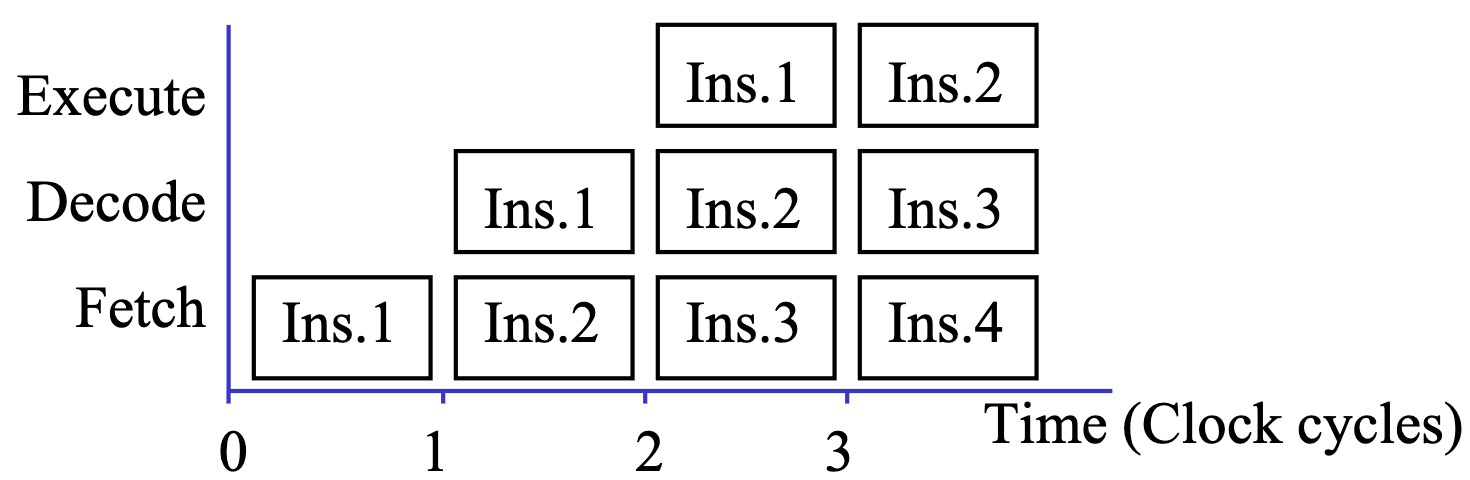
【奔腾の骚操作手册】
- 分支预测:我全都要!左手预取老实人指令,右手偷跑分支代码,赌狗の胜利
- 双核の野望:U/V两个执行单元宛如双车道飙车,前提是别碰上"简单指令+无依赖"这种稀有精英怪
- 硬连线玄学:简单指令直接焊死在电路板上,复杂指令?不存在的,RISC正统在Intel(战术后仰)
- 写回の艺术:寄存器更新比微博热搜还快,标志位翻脸比翻书还勤
流水线の黑暗面:你以为的效率革命,其实是 CPU 的血泪史
1. 资源冲突:CPU版《鱿鱼游戏》
- 内存总线就是独木桥,两条指令同时过?直接给你踹下去!ALU、寄存器全特么是限量款,抢不到资源的指令只能蹲在流水线里斗地主
2. 控制依赖:薛定谔的跳转指令
- 分支预测?预测个锤子!当你的jump指令在流水线里蹦迪时,后面跟的一串指令全是开盲盒——猜对了叫"分支预测成功",猜错了?恭喜喜提"清空流水线大礼包"!
3. 数据依赖:套娃式死亡连环call
- 想算A=B+C?先等B从内存爬出来!
- 要搞D=A*2?麻烦前面那个算A的别摸鱼!
- 最骚的是进位标志位——这玩意儿就像祖传染色体,少一个bit整个运算家族都得绝后
浮点运算の流水线魔法:从牛车到高铁的骚操作
标量运算の原始社会:
- 24步苦力操作,每个加法都得把C/S/A/N四件套从头撸到尾
- 流水线?不存在的!ALU就像单身狗热炕头——每次只能宠幸一个阶段
- 寄存器疯狂007:刚伺候完Check又要搞Shift,CPU直接过劳死预警
流水线の工业革命:
| 周期 | C (Check if Zero) | S (Shift) | A (Add) | N (Normalize) |
|---|---|---|---|---|
| 1 | 加法 1 | |||
| 2 | 加法 2 | 加法 1 | ||
| 3 | 加法 3 | 加法 2 | 加法 1 | |
| 4 | 加法 4 | 加法 3 | 加法 2 | 加法 1 |
| 5 | 加法 5 | 加法 4 | 加法 3 | 加法 2 |
| 6 | 加法 6 | 加法 5 | 加法 4 | 加法 3 |
| 7 | 加法 6 | 加法 5 | 加法 4 | |
| 8 | 加法 6 | 加法 5 | ||
| 9 | 加法 6 |
(拍黑板)看见没?资本家CPU的终极奥义:
- 四阶段流水线化身血汗工厂:Check工人刚摸鱼完,Shift工人立刻接盘
- 每个时钟周期都在榨干硬件:6个加法只付9个周期的工资(6+4-1),比周扒皮还狠
- 前戏与收尾の量子纠缠:前3周期在填流水线(热身),后6-1=5周期疯狂输出(冲业绩)
假如还有这个屠龙宝剑,计算8个加法甚至只要5周期!
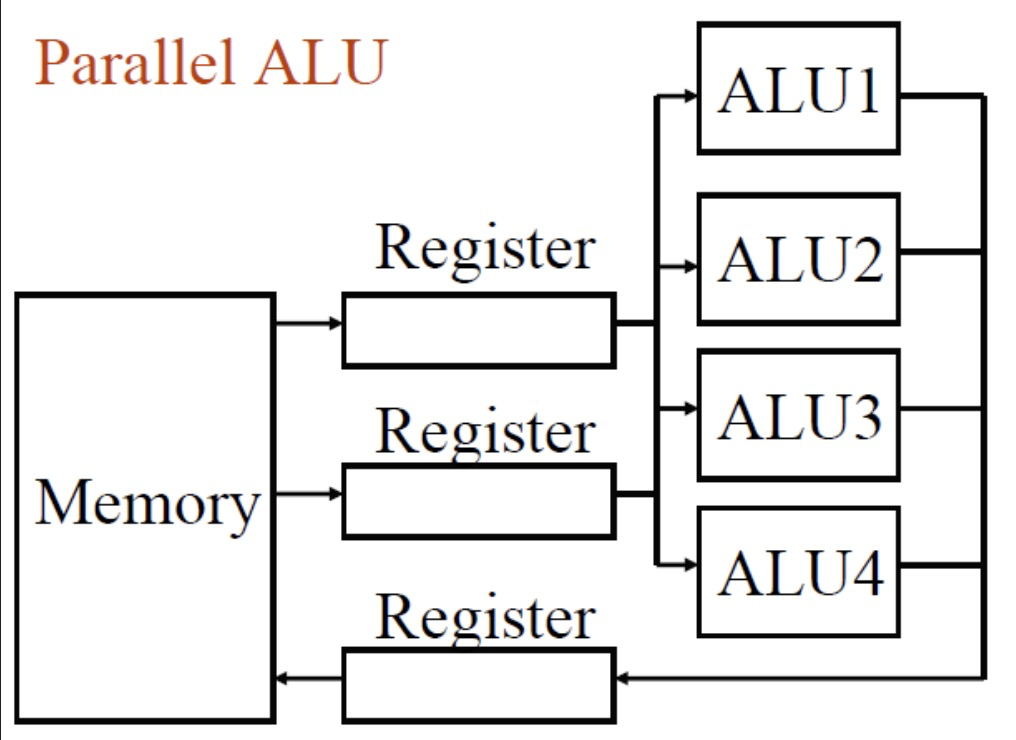
向量处理
例如要计算 $\begin{bmatrix}1\2\3\end{bmatrix}+\begin{bmatrix}3\4\5\end{bmatrix}=\begin{bmatrix}4\6\8\end{bmatrix}$ 使用标量处理至少需要3个周期,但是加上流水线和并行处理可能能在一个周期内解决
M. Flynn 并行处理器分类
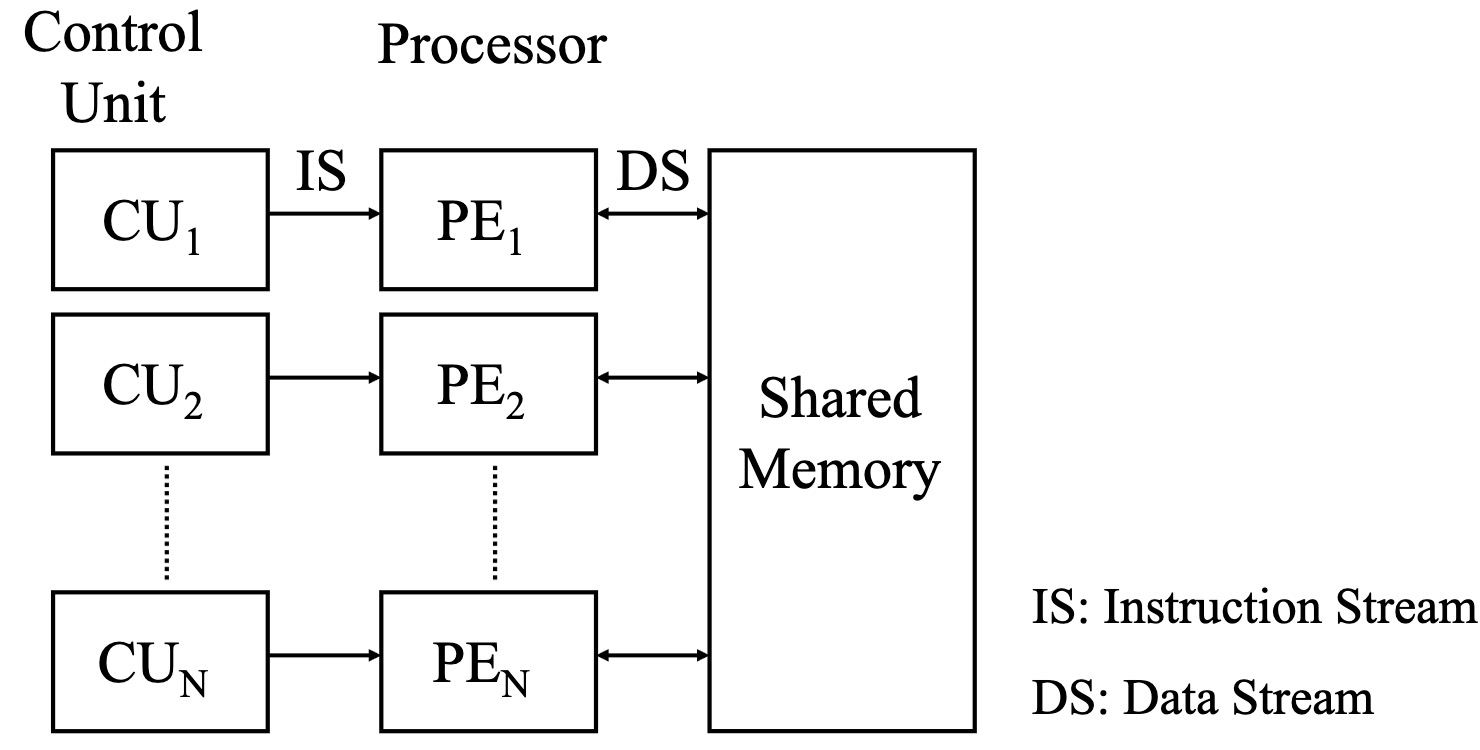
- SISD (单指令流单数据流):使用单个处理器来解释对单个数据块的单条指令。通过流水线技术实现并行。
- SIMD (单指令流多数据流):使用单条指令来控制多个处理单元。例如,向量处理器。
- MIMD (多指令流多数据流):一组处理器同时执行对不同数据块的不同指令。
多处理器
共享内存,受限于内存带宽,不能做到很大的规模
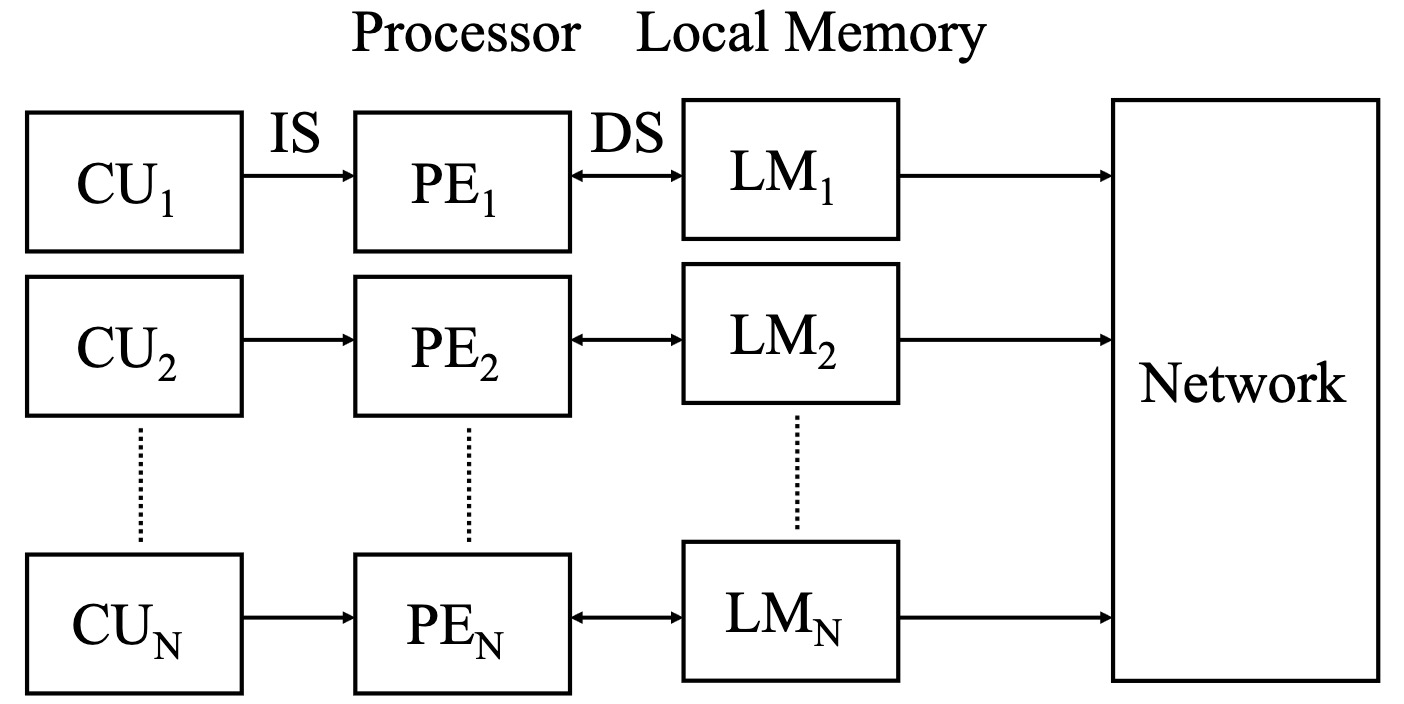
多计算机
每个处理器由自己独立的内存,说白了就是分布式系统,通过PVM来交换数据
拓扑架构
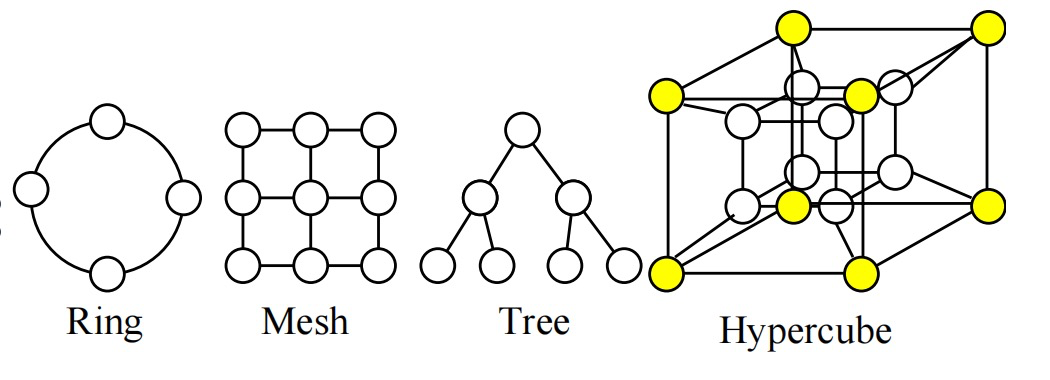
- 环形结构 ring,最远距离 n/2
- 网状结构 mesh,最远距离 2n-2
- 树形结构 tree,一般适用于分治的系统
- 超立方体结构,一共有 $2^n$ 个节点,每个节点连出去 $\log_2(n)$ 条边。最远距离 n
超标量处理器
一次能执行多条指令的 CPU,前提是指令之间不存在依赖或者冲突关系
好的,我将根据您提供的信息,对并行系统进行重写,力求更清晰、准确和易懂:
并行系统
并行系统本质上是由多个处理器组成的计算系统,旨在通过同时执行多个任务来提高性能和可靠性。 它们可以被视为多处理器系统,具有以下关键特征:
-
紧耦合性 (Tightly Coupled):
-
并行系统中的处理器共享相同的物理资源,例如总线、时钟和外围设备。
-
处理器之间通过共享内存进行通信,这意味着它们可以访问相同的内存地址空间。
-
缺点:这种紧密的集成限制了系统的可扩展性,因为增加处理器的数量会导致资源竞争和通信瓶颈。
-
对比:与此相反,分布式系统(也称为多计算机系统)中的处理器不共享总线和时钟。它们通过专用的通信链路(例如网络连接)进行通信,并使用消息传递协议来交换数据。这种架构称为松耦合 (loosely coupled),具有更好的可扩展性。
-
-
容错性 (Fault Tolerance):
-
并行系统设计的一个重要目标是在部分硬件发生故障时仍能继续运行。
-
如果某个处理器出现故障,其他处理器应能够接管其任务,从而确保系统继续提供服务,尽管性能可能会有所降低(这种特性称为优雅降级 graceful degradation)。
-
并行系统的分类
根据处理器之间的关系和任务分配方式,并行系统可以分为以下几种类型:
-
串联系统 (Tandem Systems):
-
每个进程复制两份,分别在两个独立的处理器上同时运行。
-
其中一个进程作为主进程 (primary),另一个作为备份进程 (backup)。
-
在固定时间间隔,主进程的状态和数据被复制到备份进程。
-
如果主进程发生故障,备份进程可以立即接管,从而实现零停机时间。
-
应用场景:尽管这种方式比较昂贵,但对于需要极高可靠性的关键应用(例如银行系统和证券交易所)至关重要。
-
-
非对称系统 (Asymmetric Systems):
-
有一个主处理器 (master processor) 负责控制和协调其他从处理器 (slave processors)。
-
每个处理器都被分配特定的任务。
-
主处理器负责将任务分配给从处理器,并收集和汇总结果。
-
优点:易于实现和管理。
-
缺点:主处理器容易成为瓶颈。
-
-
对称系统 (Symmetric Systems):
-
所有处理器地位相同,运行相同的操作系统副本。
-
处理器之间可以相互通信,并共享系统资源。
-
任务可以动态地分配给任何可用的处理器。
-
优点:更好的负载均衡和容错性。
-
缺点:需要更复杂的操作系统和调度算法。
-
并行系统的优点
-
资源共享 (Resource Sharing):并行系统允许系统中的处理器共享各种资源,例如打印机、存储设备和网络连接,从而降低成本和提高资源利用率。
-
计算加速 (Computation Speedup):通过将计算任务分解成多个子任务,并在多个处理器上并行执行,可以显著缩短计算时间。
-
可靠性 (Reliability):并行系统具有内在的冗余性。如果某个处理器发生故障,其他处理器可以继续运行,从而提高系统的可靠性。
-
通信 (Communication):并行系统允许系统中的处理器之间进行远距离通信,从而实现协作和数据共享
Lecture 15: 总线
总线
总线 (Buses) 是一组共享的通信线路,用于连接计算机的不同组件,并提供使用该线路的标准。
- 系统内通信 (Intrasystem communication):连接计算机内部的各种组件,距离小于一米,通过大量并行的总线来实现。
- 系统间通信 (Intersystem communication):连接计算机和远距离的硬件,通常使用串行链路来实现。
计算机总线
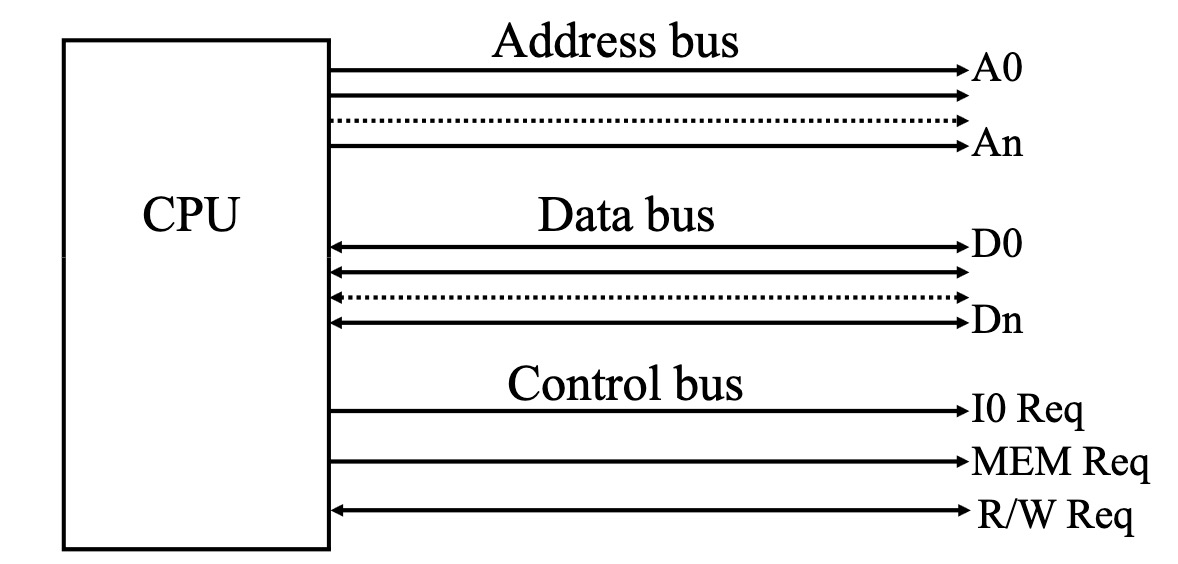
- 地址总线 (Address Bus): 当计算机希望从内存或 I/O 设备读取/写入数据时,地址总线会指定要访问的位置。 它只能输出。
- 数据总线 (Data Bus): 一种双向总线,用于将数据传输到 CPU 和从 CPU 传输数据。
- 控制总线 (Control Bus): 一组输入/输出线路,用于控制读取/写入操作期间的事件序列。
- 专用总线 (Dedicated Bus): 专用总线仅用于连接两个设备。
- 共享总线 (Shared Bus): 在早起计算机系统中,虽然地址总线、数据总线和控制总线在逻辑上是分离的,但在一些早期的、简单的系统中,它们可能会在物理上共享同一组线路。
总线时序 (Bus Timing)
在任何一个时间点,只能有一个设备可以发送数据,所有其他设备必须监听或忽略数据。 发送控制信息的设备被称为主设备 (master),其他单元被称为从设备 (slave),总线会产生瓶颈。
- 同步总线 (Synchronous Buses) 包含一个时钟信号,该信号允许每个项目在主设备和从设备都知道的预定时间段内传输。 可能实现非常快的数据速率。 然而,系统会变得和总线上最慢的设备一样慢。
- 异步总线 (Asynchronous Buses) 不包含时钟信号,要传输的每个项目都伴随一组用于排序传输的控制信号。 这有时涉及握手 (handshaking)。
PC 总线
PC 中的主要总线类型:ISA 和 PCI
早期的 PC 中主要有两种总线:ISA 和 PCI。
-
ISA (Industry Standard Architecture) 总线:
- 这是一种较老的总线标准,虽然速度较慢,但具有良好的兼容性,可以连接各种外设。
- 最初是 8 位,运行频率 4.8MHz。 后来扩展到 16 位,运行频率 8MHz。
- ISA 设备通过 ISA 连接器与主板相连。 8 位 ISA 设备只使用连接器的一部分,而 16 位设备使用整个连接器。
-
PCI (Peripheral Component Interconnect) 总线:
- 随着技术的发展,PCI 总线逐渐取代 ISA,成为目前最常见的 I/O 总线。
- PCI 提供更高的带宽,通常为 32 位宽,运行频率 33MHz。
- 通过 PCI 控制器来管理总线上的设备访问和仲裁。
- PCI 的一个重要优势是支持即插即用 (plug and play),简化了硬件的安装和配置过程。
不过现在都是用 PCIE 了
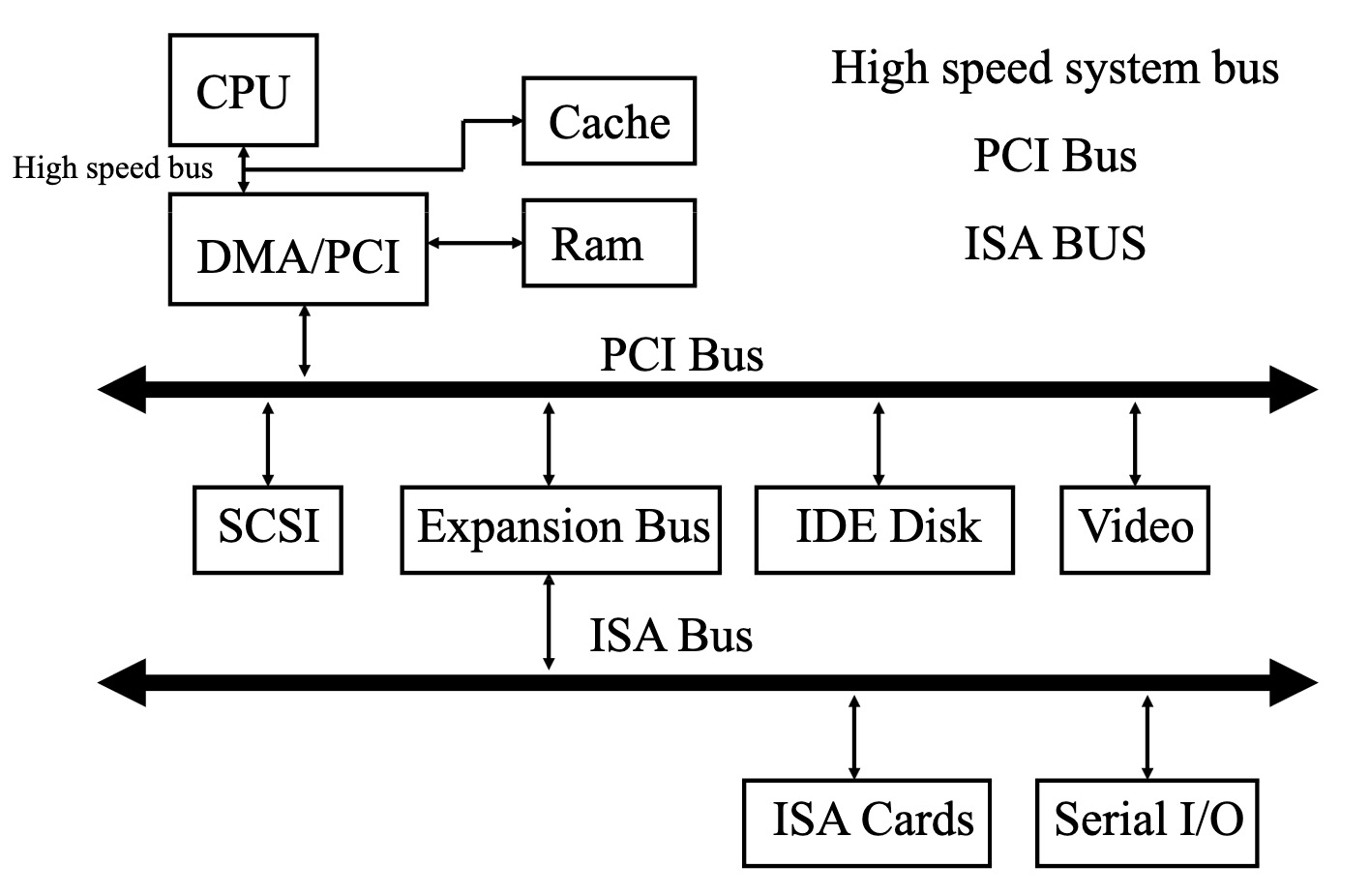
争用
像计算机上的地址总线这样的单向总线易于实现。 CPU 产生地址,所有设备监视地址线路。
但是数据总线这样的一些总线需要双向传输数据。如果两个输出连接在一起,结果称为争用。 小则数据损坏,严重就直接把电路烧了,就像这样:
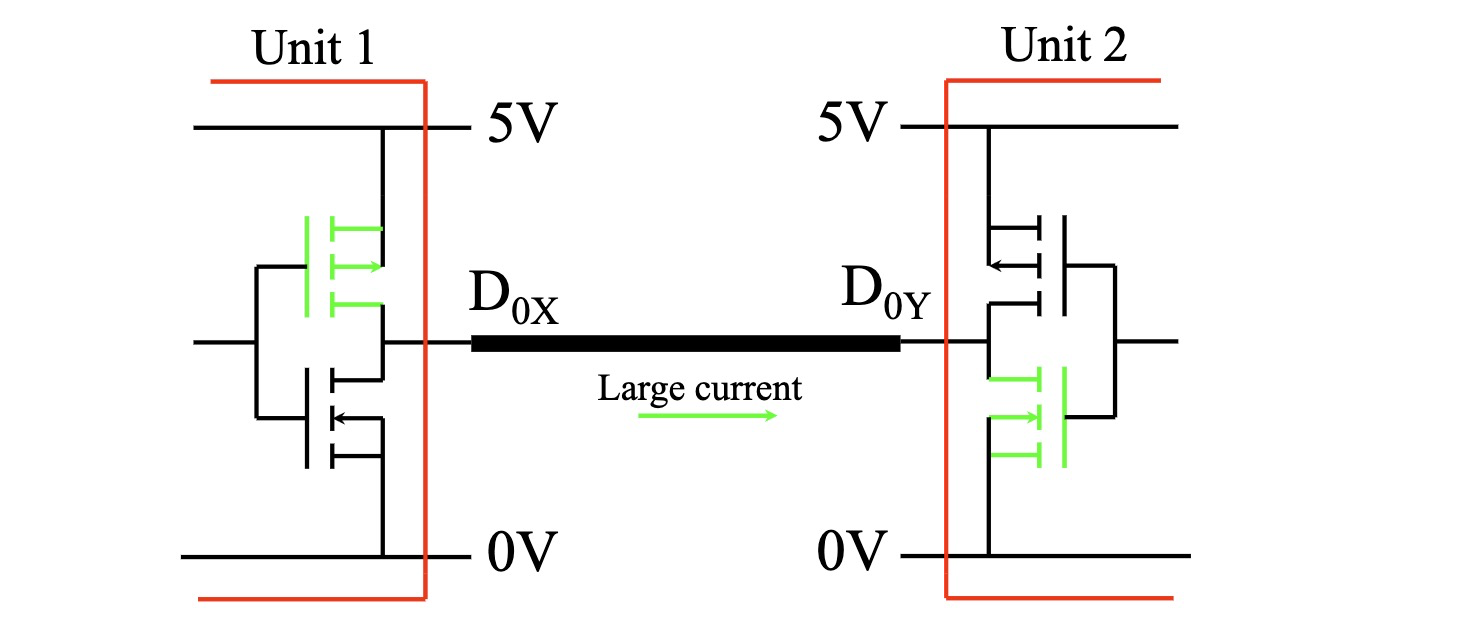
电流吸收逻辑
当然也可以这样,接一个上拉电阻,限制最大电流,这样就不会烧坏电路了,不过这种方案有速度慢和浪费电力等缺点
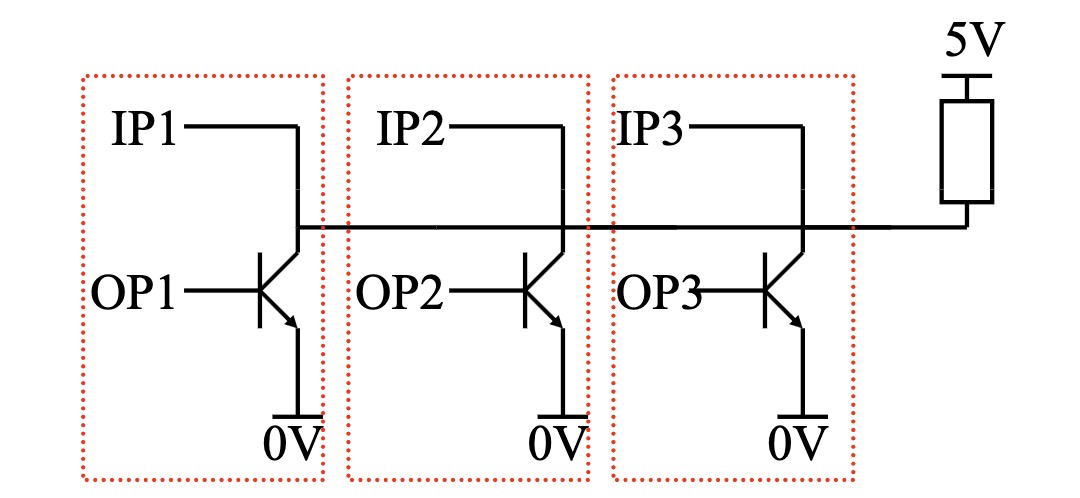
使用三态缓冲器
三态设备用另一根控制线来断开设备与总线的连接。当断开连接的时候,它的输入阻抗 (High-impedance) 变得非常大,这样就能避免总线争用的情况了。
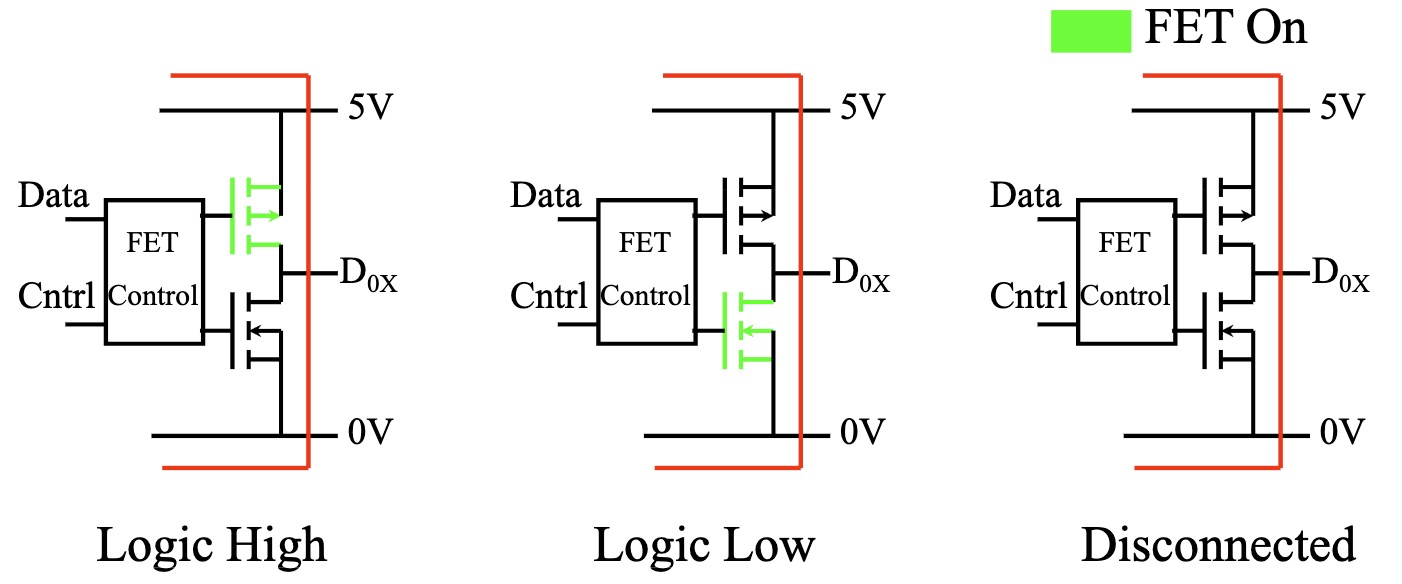
仲裁 (Arbitration)
不同设备可能希望同时使用总线,这个时候需要总线仲裁用于避免总线上的冲突或竞争。
级联 (Cascading)
当设备想要使用总线时,它会拉高 Request 信号。 如果 Busy 信号为高电平,表示总线正忙,控制器将忽略新的 Request 信号。 反之,如果 Busy 信号为低电平,控制器则发送 Grant 信号给该设备,允许其使用总线。 收到 Grant 信号后,设备会立即拉高 Busy 信号,并将数据放到总线上传输。
轮询 (Polling)
当设备想要使用总线时,它会拉高 Request 信号。 一旦收到请求,控制单元就开始挨个查看轮询线,看看哪个设备想要用总线。 找到了想用的,就把 Busy 信号拉高,然后把数据线连通,让这个设备用。
通俗一点来就像点名一样:设备想用总线先举手 (发出请求)。然后控制器一个一个地问:“1 号,你要用总线吗? 2 号,你要用总线吗? 3 号,你要用总线吗?...”,一旦点到某个举手的设备,控制单元就说:“好,给你用!” 然后把 Busy 信号设为“忙碌”,并把数据线连通,让这个设备传输数据。“点名”的顺序决定了谁先被服务,也就是谁的优先级最高。 如果 1 号总是先被点到,那么 1 号的优先级就最高。
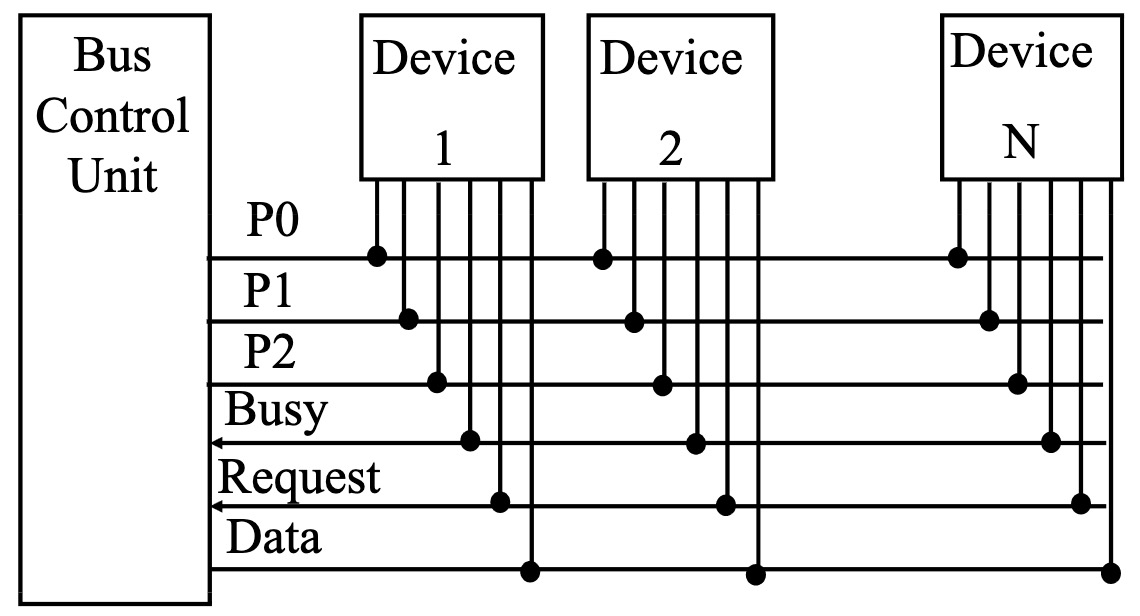
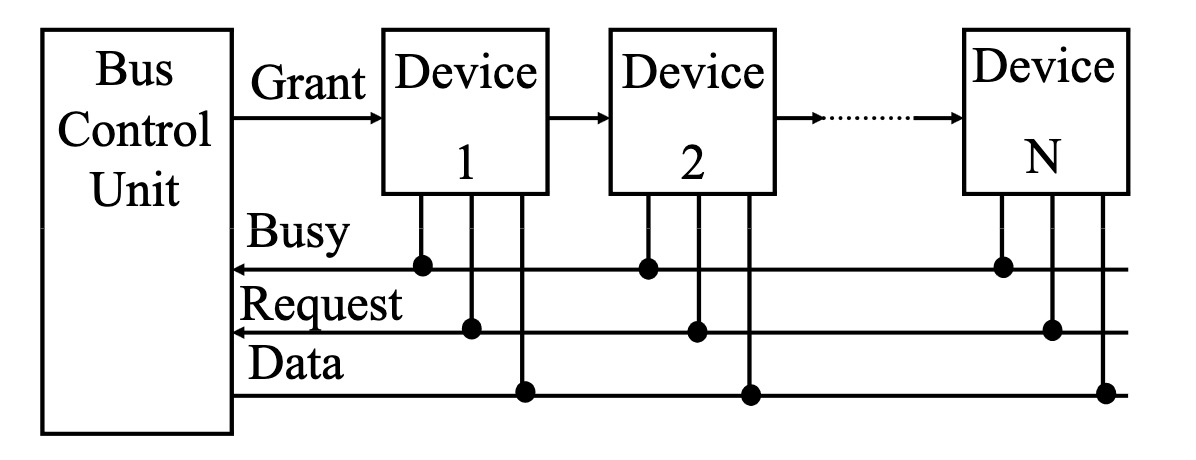
独立请求 (Independent Request)
每个外设单元都有单独的请求线 (Request) 和授权线 (Grant)。优先级由总线控制单元来决定。不过缺点就是比较复杂,因为每个单元都需要单独的请求线和授权线。

Lecture 16: 闪存与 FPGA
闪存
闪存 (Flash) 的存储单元包含一个带控制栅和浮动栅的存储晶体管。浮动栅通过薄氧化层与晶体管隔离,用于存储电荷并控制电流。
- 写入:在高电场下,通过在源极和漏极施加强负电荷,在控制栅上施加强正电荷,使电子穿过薄氧化层进入浮动栅。此时 FET 源极和漏极之间的 p 掺杂沟道可以轻松地流动电流,表示
1。 - 擦除:在控制栅上施加强负电荷,迫使电子进入具有强正电荷的沟道,减少 p 掺杂沟道中的空穴,导致电导率大幅下降。表示
0。 - 数据保持:由于氧化层的电隔离,浮动栅中捕获的电子不依赖于 Flash 存储单元是否接收电源。Flash RAM 可以无需电源即可保存内容多年,因此可用作计算机的存储介质。
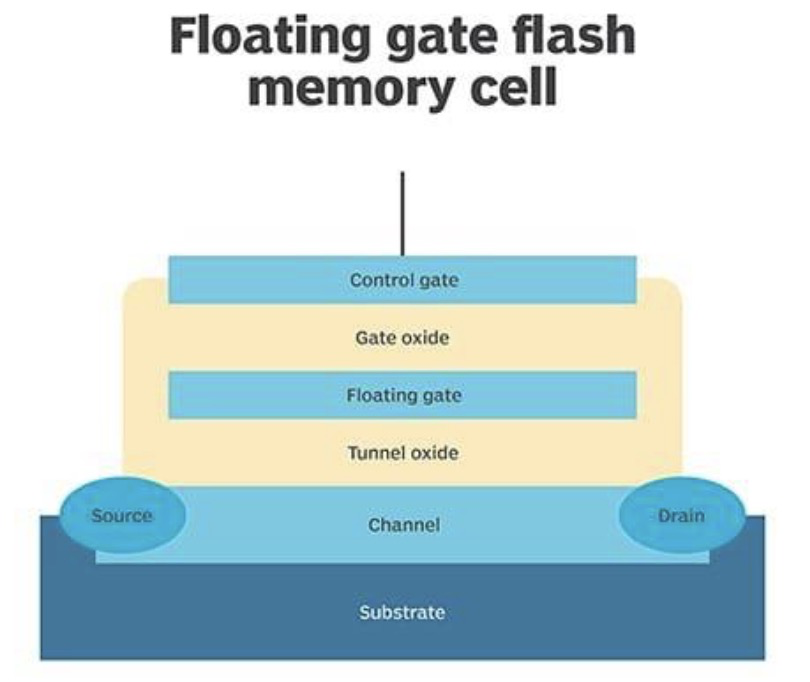
NAND Flash VS NOR Flash
Flash RAM 分为 NOR 和 NAND Flash 存储器。
- NOR Flash:不使用共享组件,可以并行连接各个存储单元,从而可以单独随机访问所有数据。
- NAND Flash:单元更紧凑,位线更少,浮动栅晶体管串在一起以增加存储密度。更适合串行数据访问。
- 编程方式:NOR Flash 按字节级别编程数据,NAND Flash 按页级别编程数据(大于字节但小于块)。
- 读写速度:NOR Flash 读取数据速度快,但在擦除和写入方面通常比 NAND 慢。
- 功耗:NAND Flash 在写入密集型应用中比 NOR Flash 消耗更少的功率。
- 成本:NOR Flash 存储器通常生产成本更高。
SSD
基于 Flash 的介质基于硅基板,因此被称为固态设备。有很多种接口:2.5"SATA, mSATA, M.2, PCle Add-In Card

FPGA
现场可编程逻辑门阵列(英语:field-programmable gate array,缩写为FPGA)以PAL、GAL、CPLD等可编程逻辑器件为技术基础发展而成。作为特殊应用集成电路中的一种半定制电路,它既弥补全定制电路不足,又克服原有可编程逻辑控制器逻辑门数有限的缺点。可以利用逻辑合成和布局、布线工具软件,快速地刻录至FPGA上进行测试,这一过程是现代集成电路设计验证的技术主流。这些可编程逻辑组件可以被用来实现一些基本的逻辑门数字电路(比如与门、或门、异或门、非门)或者更复杂一些的组合逻辑功能,比如译码器等。在大多数的FPGA里面,这些可编辑的组件里也包含记忆组件,例如触发器(Flip-flop)或者其他更加完整的记忆块,从而构成时序逻辑电路。
系统设计师可以根据需要,通过可编辑的连接,把FPGA内部的逻辑块连接起来。这就好像一个电路试验板被放在了一个芯片里。一个出厂后的成品FPGA的逻辑块和连接可以按照设计者的需要而改变,所以FPGA可以完成所需要的逻辑功能。
FPGA一般来说比特殊应用集成电路(ASIC)的速度要慢,无法完成更复杂的设计,并且会消耗更多的电能。但是,FPGA具有很多优点,比如可以快速成品,而且其内部逻辑可以被设计者反复修改,从而改正程序中的错误,此外,使用FPGA进行调试的成本较低。厂商也可能会提供便宜、但是编辑能力有限的FPGA产品。因为这些芯片有的可编辑能力较差,所以这些设计的开发是在普通的FPGA上完成的,然后将设计转移到一个类似于专用集成电路的芯片上。在一些技术更新比较快的行业,FPGA几乎是电子系统中的必要部件,因为在大批量供货前,必须迅速抢占市场,这时FPGA方便灵活的优势就显得很重要。
FPGA (Field Programmable Gate Array) 是一种 SSD 设备。通过硬件描述语言 (HDL) 描述的电路,可以烧录到FPGA上,在原型设计产品(如微波炉或洗衣机)时,工程师可以为 FPGA 编写软件来测试系统的功能,对于大众消费产品,使用 FPGA 进行原型设计更便宜,因为 HDL 程序可用于设置掩模以构建特定应用集成电路 (ASIC) 芯片,该芯片的生产成本非常低。
FPGA 结构
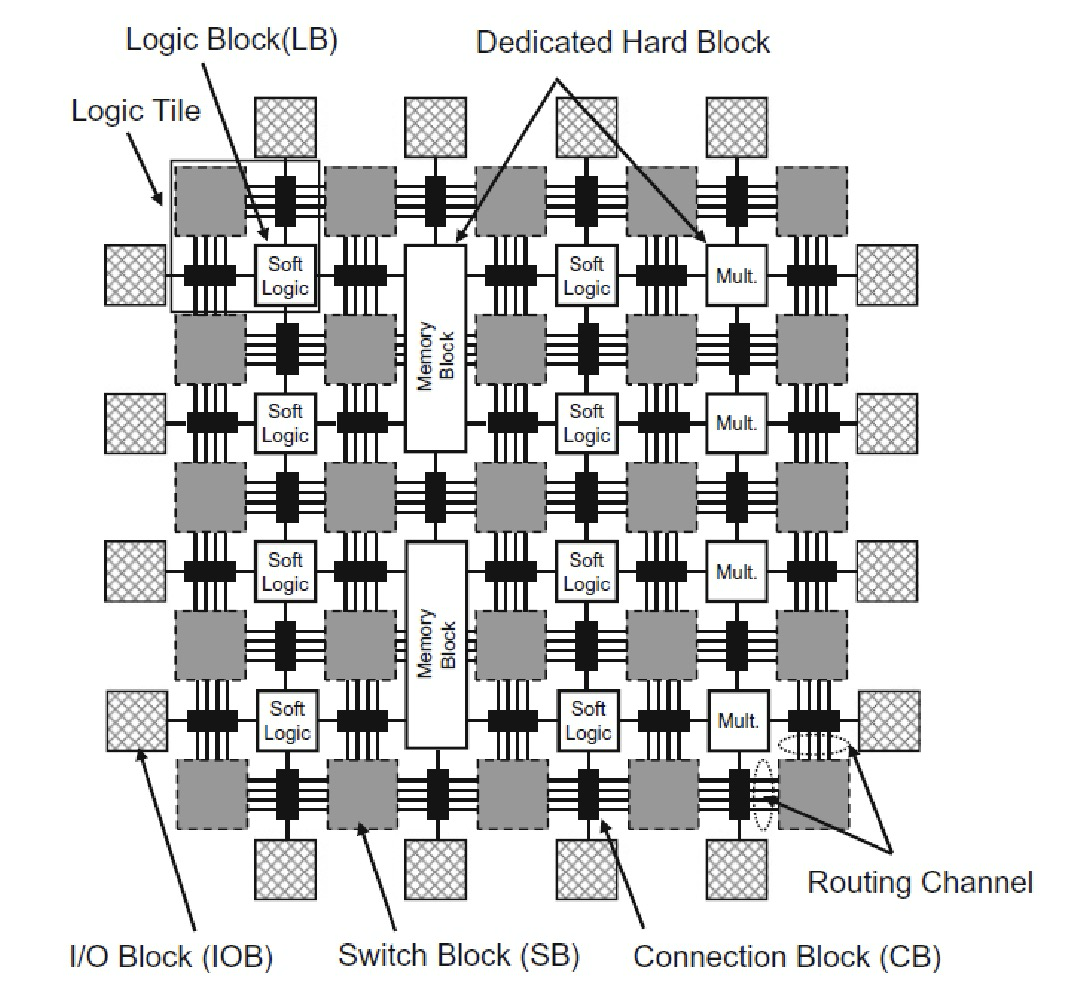
Verilog
有几种 HDL,但最常用于教学的是 Verilog。与工业中使用的 VHDL 不同,Verilog 是一种更易于学习的语言,并且可以执行 VHDL 可以执行的几乎所有功能。
用 Verilog 编写的 SR 锁存器的简单结构描述
module SRlatch(
output Q, Q_bar,
input S, R);
nor N1(Q_bar, S, Q);
nor N2(Q, R, Q_bar);
endmoduleThe End ~~~ : )